Artificial Intelligence
Visual search on AWS—Part 1: Engine implementation with Amazon SageMaker
| April 2023 Update: Starting January 31, 2024, you will no longer be able to access AWS DeepLens through the AWS management console, manage DeepLens devices, or access any projects you have created. To learn more, refer to these frequently asked questions about AWS DeepLens end of life. |
To perform a visual search instead of asking for something by voice or text, you show what you are looking for. As the old saying goes, “A picture is worth a thousand words.” Often it’s easier to show a physical example or image than to try to describe an item with words that a search engine can effectively use. Some users might simply lack the knowledge or understanding to describe a specialized item. Another use case for visual search is when image or video data must be searchable, but it’s ingested too fast to accurately assign labels or metadata.
For retail use cases for visual search, take the example of a consumer looking for a replacement part in a hardware store. Instead of using words to identify the part, which might be difficult if the consumer lacks required expertise, the consumer could just show the part to an AWS DeepLens device, a deep-learning-enabled video camera. The device could then pull up a list of visually similar recommended parts and their location in the store. If consumers had an AWS DeepLens device at home, they could simply show an item in the house to the device when looking to buy another item resembling it. An advantage of visual search is that it relies entirely on item appearance. There is no need for other data such as bar codes, QR codes, product name, or other product metadata.
In this two-part blog post series we explore how to implement visual search using Amazon SageMaker and AWS DeepLens. In Part 1, we’ll take a look at how visual search works, and use Amazon SageMaker to create a model for visual search. We’ll also use Amazon SageMaker to build a fast index containing reference items to be searched. In Part 2, we’ll extend the results of Part 1 from the digital world to the physical world using AWS DeepLens. Most current applications of visual search don’t involve direct interaction with the physical world in real time, but instead they involve static images within the digital world of websites and apps. Part 2 crosses the bridge from the digital to the physical world by demonstrating how to directly search for items visually similar to physical objects in real time via an AWS DeepLens device. The notebooks associated with this blog post series can be found at https://github.com/awslabs/visual-search/tree/master/notebooks.
How visual search works
You can apply several different algorithms to perform visual search. For this blog post, we’ll extract features from images using a Convolutional Neural Net (CNN) model pretrained on the well-known ImageNet dataset of over 11 million images. The idea of using a pretrained CNN to extract features from images has been examined in multiple research papers, such as the one by Babenko et al (2014), “Neural Codes for Image Retrieval.” The CNN extracts features from images by detecting colors, textures, shapes, etc. With the resulting features defined in a much lower dimensional space than the original images, it becomes easier to make image-to-image comparisons to find the most visually similar matches.
Normally a pretrained CNN outputs labels for classifying images into different categories such as car, table, vacuum cleaner, etc. To make use of a pretrained CNN, we’ll need to modify it. Specifically, we’ll modify it to extract features from images. A CNN typically is modified so the layer before the last fully connected layer is used as the output. The output of this layer can be considered as a “feature vector” for an image that summarizes the image’s features. To perform visual search given an image of a query item, a query feature vector is produced and then a lookup is performed against an index of feature vectors of reference items. The following image illustrates this:

A key advantage of using a pretrained model is avoiding the time and costs associated with gathering labeled training data and training a new model. The featurization process is much faster than model training. This is because featurization only involves one forward pass in the model for each reference data item. This process doesn’t include the compute-intensive backward pass gradient calculations normally performed in training.
The only data gathering that must be done is of a reference item dataset, which is then converted into a set of feature vectors. As an example of the data gathering step, consider a retail store. The only data that must be gathered by the store is a set of reference images representing items sold by the store, and related metadata about those images such as product titles, image URL, etc. For the CNN model itself, the underlying “dataset” essentially is the ImageNet dataset, which often is sufficiently diverse to be relied on for feature extraction in general. However, as reference item images become more highly specialized with minor differences distinguishing classes, or otherwise diverge from the ImageNet dataset, it might be helpful to fine-tune the CNN model to account for those specialized images.
Creating a model and featurizing reference items
The process of creating a model for use in visual search involves several steps. First, select a deep learning framework that has an associated “model zoo” of pretrained models, including CNN models pretrained on the ImageNet dataset. For this blog post series, we’ll use Apache MXNet as the deep learning framework. From the MXNet Model Zoo, we’ll use a pretrained model based on the contest-winning ResNet architecture, which has achieved high accuracy in classifying the over 11 million images of the ImageNet dataset.
All of the steps involved in creating the model, and related code, are in the Jupyter notebook associated with this blog post series. The notebook can be accessed from this project’s GitHub repository, at https://github.com/awslabs/visual-search/tree/master/notebooks. The steps can be briefly summarized as follows:
- Import a pretrained CNN model from the MXNet Model Zoo.
- Obtain a reference to the model’s first fully connected layer after its convolutional layers.
- Save a new version of the model with that layer as the output.
After these steps, the modified model’s output layer generates feature vectors instead of labels for classifying images. A feature vector simply is a vector of floating point numbers. For example, depending upon which fully connected layer is selected as the output, a feature vector generated from a ResNet CNN with 152 layers could contain 2,048 elements. Whereas, for a RestNet CNN with 18 layers, it would have 512 elements. Smaller numbers of CNN layers and feature vector elements allows faster computations in both the feature vector generation and later index lookup stages, at the cost of loss of some information.
With a featurizer model in hand, the next step is to featurize a reference item dataset. As described earlier, this involves sending each image through a forward pass in the model and obtaining the feature vector output. In this project’s Jupyter notebook, this process is performed for a small sample dataset of Amazon.com product images. You might also try another, larger dataset of Amazon.com product images referenced in the paper by J. McAuley et al. (2015), “Image-based recommendations on styles and substitutes.” The resulting feature vectors are inserted in an index for fast lookups of visually similar reference items. Next, we’ll discuss one type of index that can be used.
Indexing similar items with the Amazon SageMaker k-NN algorithm
A featurizer model that generates feature vectors is just one of the core components of visual search. The reference item feature vectors typically are generated offline and should be stored so they can be efficiently searched. For small reference item datasets, it’s possible to use a brute force linear search that compares the query against every reference item. However, this isn’t feasible for large datasets where a brute force search would become prohibitively slow. Accordingly, another core component of visual search is a fast index of reference item feature vectors.
To enable efficient searches for visually similar images, we’ll use the Amazon SageMaker k-Nearest Neighbors (k-NN) algorithm. The main objective of training with the k-NN algorithm is to construct an index. This index enables efficient lookups of items that are “neighbors” as measured by a distance metric such as Euclidean distance or cosine similarity. At lookup time, the index is queried for the k-nearest neighbors of a sample query item. In the context of visual search, a query image is featurized using a modified CNN model, and the resulting feature vector is then used to look up visually similar matches in the k-NN index of reference item feature vectors:
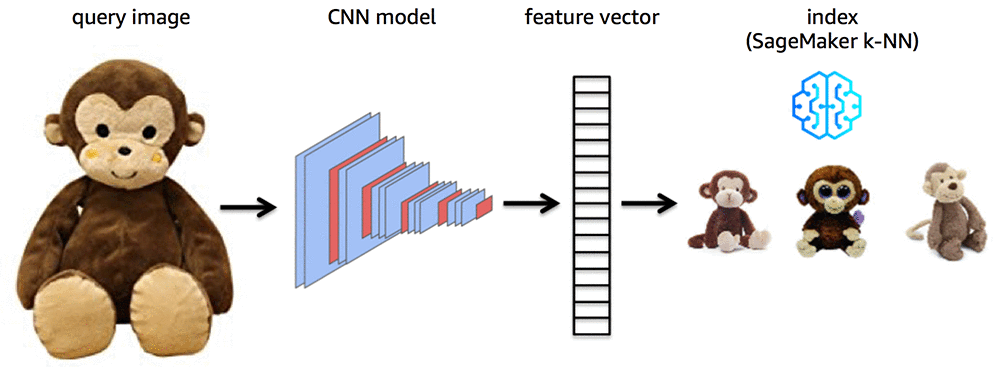
Keep in mind that for use cases other than visual search, k-NN algorithm neighbors typically are used for either classification (by majority vote of neighbors on class label) or regression (by averaging the neighbors). For the use case of visual search, however, we use these nearest neighbors directly as the most visually similar matches to the query image. As illustrated by the previous figure, visual search allows us to narrow down a search to items likely to be of the most interest. By contrast, if we use an unmodified ResNet that outputs classification categories rather than feature vectors, a search would return a general category that might include hundreds or thousands of items of less relevance.
To keep the notebook code readable and concise, the k-NN training job is created using the Amazon SageMaker Python SDK, which provides many helper methods and conveniences. The SDK provides a specific KNN estimator object that abstracts away the lower level details of setting up a k-NN training job. After the index has been built by the k-NN training job, you must use the verbose form of the Amazon SageMaker Predictor API to retrieve the neighbors from a SageMaker endpoint hosting the k-NN index. The following code snippet shows how to invoke the verbose API using the Accept header of the request. It also shows how to use various SDK conveniences, such as a CSV serializer for an input query image feature vector and a JSON deserializer for the response returned by the SageMaker endpoint, as well as the KNN estimator for training:
What’s next
So far we’ve examined use cases for visual search, and dived into the details of how visual search works. We also looked at how to prepare a featurizer model for visual search, and how to use that model to featurize a dataset of reference items, index the features, then perform queries against them.
In Part 2 of this blog post series, we’ll explore how to implement visual search using AWS DeepLens. Stay tuned!
About the Author
 Brent Rabowsky focuses on data science at AWS, and leverages his expertise to help AWS customers with their own data science projects.
Brent Rabowsky focuses on data science at AWS, and leverages his expertise to help AWS customers with their own data science projects.