AWS for M&E Blog
FAQs about live streaming on AWS: How does AWS make live streaming reliable and highly available?
How Does AWS Make Live Streaming Reliable and Highly Available?
In my last blog I looked in detail at the factors that contribute to the cost of live streaming on AWS. I focused on the AWS Elemental Media Services that encode, package and originate, and monetize live streams, as well as the use of Amazon CloudFront to distribute content to audiences around the world.
In this post, I want to dive deeper into benefits you get from using these services. Basically, what you get for your money.
First, I’ll look at why live streaming is so challenging, with a focus on how these challenges were addressed in the past, how that changed with the cloud, and how it evolved further with AWS Elemental Media Services.
Live is Hard
As I’ve said before, streaming live video is hard. A lot of the challenges to successful live streaming follow from the fact that everything involved in live streaming has to be done in real time, as live is, well, live. There are no second chances. And, there is a compounding effect that makes those challenges even harder.
For one, as the content you want to stream becomes more valuable and well-known, the pressure to make the live channels more reliable intensifies. For high profile content, the impact of any failure is magnified. An outage for a minor league sporting event would be bad, but an outage during a championship final would be a lot worse. The higher the profile of the content, the more reputational harm and brand damage that can be done from a poor streaming experience.
As the content gets more popular, the challenges of delivering that content to the larger audiences gets harder. This is when popularity and reliability compound the challenges to successful live streaming: when there are a few hundred people watching, live video delivery can be quite easy; when there are over a million people watching, it becomes much harder. With more viewers, Content Delivery Networks (CDNs) are delivering more content, and as this content is live the caching efficiencies that are seen with On-Demand content are not there, and more requests have to go back to the origin of the live stream. This means the origins for live streams have to scale to match the peak requests. Even if only one percent of the total of requests reach the origin, with a millions viewers, that’s 10,000 request that have to be delivered quickly. If the origin were to fail at this point, you’ve just created a million unhappy viewers.
Finally, as that audience grows, expectations grow too. Viewers watching an OTT live stream believe that it should be as good as–if not better than–traditional broadcast. Ten or 15 years ago, it could be said that an online version of a live stream was the “best-effort” and audience expectations would reflect that. In today’s world, audiences expect to be able to watch content on their terms, on any devices, and any type of internet connection with the same quality of experience as the TV in their living room. Indeed, for an increasing number of consumers, OTT viewing is their only form of viewing. There is no longer an option to cut corners with OTT streaming and accept a lower bar for reliability.
Delivering that broadcast TV experience traditionally meant building a live broadcast chain, then duplicating that chain to provide redundancy. Then, adding a third chain to keep things running in a disaster recovery (DR) scenario. This approach is still being used and has worked for many years, but is by no means perfect. The separate chains have to be monitored and managed, usually with an “eyeballs-on” operations team that had to constantly watch dashboards and alerts and take manual operational steps to resolve any issues as they occur.
Chaos Engineering for Live Streaming
The cloud offers a new way to build and architect systems that is not feasible with this traditional approach. Native cloud architectures should be designed to work even if components within the workflow fail. And any failures should heal and the system should recover without any manual intervention required.
Netflix has made famous the concept of Chaos Engineering. This discipline, put rather simply, tries to build a complex system that can maintain a steady state, even when issues like software bugs, network issues, or hard drive failures impact the components within the system.
Looking at a live streaming workflow, a “steady state” would mean audiences can still watch content without a noticeable degradation of quality of experience.
Something that can conform with these basic principles of chaos engineering in the cloud would be much better than replicating the traditional multi-data center model, but this can still be a very complex system to build and maintain.
What would this solution look like?

Ideally, the elements that make up the workflow would be separated to reduce the impact of any one component having an issue: inputs separate from encoding, encoding separate from packaging, the ingest for packaging separated from the origination, and so on. Each chain of the channel would auto-scale all the elements. This means encoding resources, packaging resources for ingest, and packaging and origination would all heal and scale as needed. Resources would be split across data centers, or availability zones, providing the equivalent of a multi-data center distributed workflow. Video encoding would be synchronized between the distributed encoding resources and would failover between the pipelines to provide a single, consistent origin for CDN distribution. This means viewers of the stream will receive continuous output for a live channel, and any degradation of components that make up that channel will not affect the output to the viewer. Even a failover of an encoding pipeline would be unnoticed by viewers as the video segments would be synchronized so switching between pipelines would be seamless. So, the goal of maintaining a steady state when workflows are degraded is achieved.
To this reliable foundation, add scalable and durable content storage, so the live streams can have DVR-like features. A built-in layer of monitoring and alerting would be required to give confidence that the live channel is maintaining its steady state, even if alerts are firing about degraded components. And last, but by no means least, would be systems that ensure operational excellence for security and access control across the system and for components within the system.
AWS Elemental Media Services
As I said, this is a lot to build and maintain. However, it should not be surprising to discover that a solution like this can be built using the AWS Elemental Media Services, and that it provides the benefits a highly available and reliable live channel, with redundant inputs, synchronized encoding pipelines, automatic failover between pipelines, and auto-scale resources for origination, all with reduced complexity.
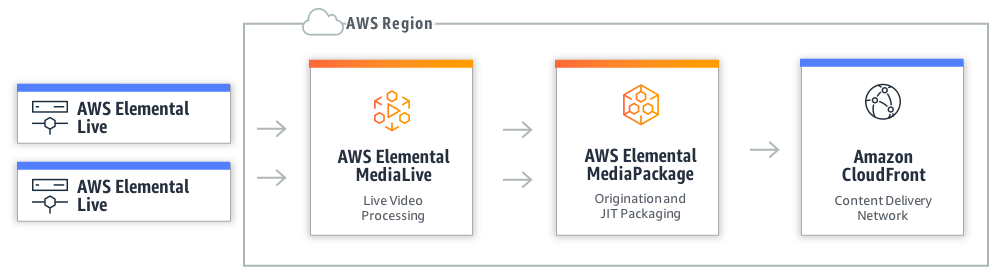
Let’s look a little deeper into the benefits offered by AWS Elemental MediaLive and AWS Elemental MediaPackage, and how they include a lot more than just single encoding or packaging instances in the cloud.
In the examples I gave in the earlier blog post, a MediaLive channel with a typical configuration of inputs and outputs running in US West, North Virginia region would cost about $5.00 an hour with on-demand pricing, or the equivalent of $1.20 an hour with reserved pricing (with 12-month commitment.) MediaPackage could add about $10.00 an hour (this figure is more variable, and is subject to the assumption described in the earlier blog post.) So, what are you getting for your money?
AWS Elemental MediaLive
MediaLive provide two inputs for each live channel you create. If the inputs are pull based, just enter the URL. If they are push based, then two IP addresses are provided as ingest points. Each ingest point will be in a separate availability zone. A channel configuration is applied, and two destinations are configured. The resources that do the encoding are also spread across availability zones, and when the same timecode is embedded in input A and B, the separate encoding pipelines will produces synchronized outputs to destinations A and B. All resources are auto-scaling, so failures will heal without manual intervention, and with synchronized outputs what the viewer sees is unaffected.
AWS Elemental MediaPackage
After MediaLive provides two synchronized ABR encoded outputs for a live channel, MediaPackage takes over for packaging and origination. MediaPackage natively provisions resources across multiple availability zones within a region, and the two MediaLive outputs are sent to two redundant ingest addresses for the MediaPackage channel.
There is a fleet of auto-scaling ingest resources, with, durable, reliable, and scalable storage and database resources that index and archive the live stream. The packaging, origination, and caching resources are also distributed and auto-scaling provides reliable performance as audience sizes grow. The channel output will automatically failover between the redundant ingest feeds if a loss of input is detected, and with MediaLive synchronizing its two outputs, this failover is seamless for anyone watching the channel. This failover comes without any need to add custom logic in players or clients as it works from a single endpoint for each packaged stream output.
There are also layers of protection built-in as standard to protect against common web exploits, and easy “one-click” configuration of Amazon CloudFront endpoints to add CDN distribution to the live channel.
CONCLUSION
With audiences for live OTT content growing, and their expectations for features, faultless experiences, and greater choice increasing, delivering against those expectations is a must for any serious players in the market. Traditional methods of running a TV channel by deploying hardware across multiple self-managed data centers that served broadcasters, distributors, and operators in the past are inflexible, slow to deploy, and require large capital expenses and over-provisioning to achieve the levels of redundancy required for live workflows. The cloud offers a new way to build systems that can scale on demand with audience sizes, stay nimble and agile to keep up with audience expectations, and offer greater reliability and cost efficiency to maintain the levels of service and experience audiences demand from live TV. The AWS Elemental Media Services make it even easier by handling the complexity of architecting a highly reliable, distributed, feature-rich live channel workflow.
Over the next few months we’ll be posting some “How-To” and Best Practices guides to provide detailed, step-by-step instructions to help you get the best out of AWS Elemental MediaLive, MediaPackage, and CloudFront.