AWS for M&E Blog
Automatically compare two videos to find common content
Comparing two videos to determine what is common and what is different between them is useful in many ways. The ability to find common content across two video sources opens up a number of interesting possible applications, including:
- Searching third-party videos for unauthorized use of your content
- Monitoring a pair of video streams to ensure that they show the same program, even if their commercials differ
- Comparing two videos to see how much common content exists
Typically, broadcasters handle this type of comparison manually, which requires having a person simultaneously monitor two videos at once. This manual approach is tedious, time-consuming, and can be error-prone.
This blog describes an automated process to perform these types of video comparisons. This approach can be used for comparing stored videos, or for video streams, and is flexible enough to be adopted for a variety of use cases.
A solution with challenges
One option you may consider when looking to compare videos is review screen captures or frame images from both sources. While conceptually simple, there are a number of details that make this approach complex to implement.
First, in many cases, the frames from two video sources won’t be an exact match since the on-screen logos for broadcasters differ. For example, if a television program is syndicated, one video shows a logo from one station, and the other video shows a logo from another station. These on-screen logos (or bugs) are used to provide station identification, and are typically displayed during the entire airing of a program, meaning the frame images always differ between the two video sources.
Second, there can be other on-screen differences like a content rating icon (“TV 14”, for example) or a closed caption indicator that differs from one broadcaster to another. This situation is most common when comparing videos that are aired in different countries, for example a program that originated in US shown on a Canadian television station.
Additionally, there may be on-screen overlay or banner advertisements displayed at the top or bottom of the picture for a few seconds. Like the commercial breaks during a broadcast, those ads may be regional, and different from one broadcaster to another.
Further, frames captured for each source are probably from slightly different moments in time, which causes slight visual differences. Even if the scene is someone sitting and talking, their facial expressions change over time, as does the position of their hands and their posture. In situations where the screen changes rapidly (like some opening credits sequences, or sporting events), you may end up with completely different sets of frame images. Because of this, a simple comparison of a frame from one video with a frame from another isn’t going to work – they are never going to be an exact match.
Finally, even if the main content of two videos is the same, the distribution of commercials may vary between the two video sources. For example, at a particular commercial break, one broadcast may have two minutes of commercials while the other has only one minute thirty seconds of commercials. The following diagram illustrates this situation:

Diagram showing different ad distributions surrounding the same broadcast content
With this uneven distribution of commercials, you can’t make any assumptions about where matching content might be.
Fuzzy matching and taking the middle third
Fortunately, there are solutions for all of these concerns.
First, for videos with differing on-screen logos and icons, we can work with just one part of each frame image. By stripping off the top and bottom third of each frame image, we remove all of the logos and icons, as well as any banner or overlay ads. Here’s an example of that operation:

Full screen image on the left, middle third of the same image shown on the right
Using Python and the popular open source image manipulation library named Pillow, this operation can be done as follows:
from PIL import Image
with Image.open(f) as im_pil:
crop_x1 = 0
crop_x2 = im_pil.width
crop_y1 = int(im_pil.height * 0.333)
crop_y2 = int(im_pil.height * 0.666)
middle_third = im_pil.crop((crop_x1, crop_y1, crop_x2, crop_y2))
Next, since images are likely to be slightly different from one video source to another even with the on-screen logos removed, we need to find a method to determine how similar images are to each other, as opposed to looking for exact matches. A perceptual hash is a good method to accomplish this.
A perceptual hash is an algorithm that takes an image and returns a corresponding value. There are different types of perceptual hashes, but the idea is that a given image returns the same hash value, even if the image has been resized.
Hash values from different images can be compared to each other and used to measure how similar the images are. The following are two examples. On the left, two consecutive frames are displayed. They are very similar but have some subtle differences. On the right, two very dissimilar images are shown. Notice the percentage differences between the frame pairs:

On the left, two very similar frames are shown with a difference of 9%. On the right, two differing frames are shown with a difference of 53%.
Using perceptual hash values, we can consider two frame images to be a match if they differ by a certain threshold or less. Based on testing, we’ve found that if the images vary by 25% or less, we can consider that a match.
Perceptual hashing is supported by the Python open source library named ImageHash. The use of that library to get a hash from an image is as follows:
hashval = imagehash.phash(middle_third)By applying a perceptual hash to the middle third of the frame images, and looking for a difference less than a given threshold, we can find matching frames across two video sources. However, that’s still not enough to determine if there is matching content.
Black frames frequently appear during a television program’s credits, or between commercials. Although black frame images are found in both video sources, a single matching frame simply wouldn’t be an accurate indicator of matching content. To achieve an accurate result, we need to compare groups of frame images at a time. For that we use a method called fuzzy matching.
Fuzzy matching is a technique that looks for a certain threshold of matches, rather than looking for exact matches. Based on testing, we’ve found that if we compare two sets of frame images and find that 75% of the frames match across the two groups, we can count that as a match. This is a helpful technique in situations where some frames may simply not show up in both sets due to different moments captured by the frame images.
In order to compare groups of frames, we compare them with two sliding windows that specify which frames we are examining. The following is an illustration of this concept, with each sliding window examining four frames at a time. The thick arrows indicate frames that are considered a close match:
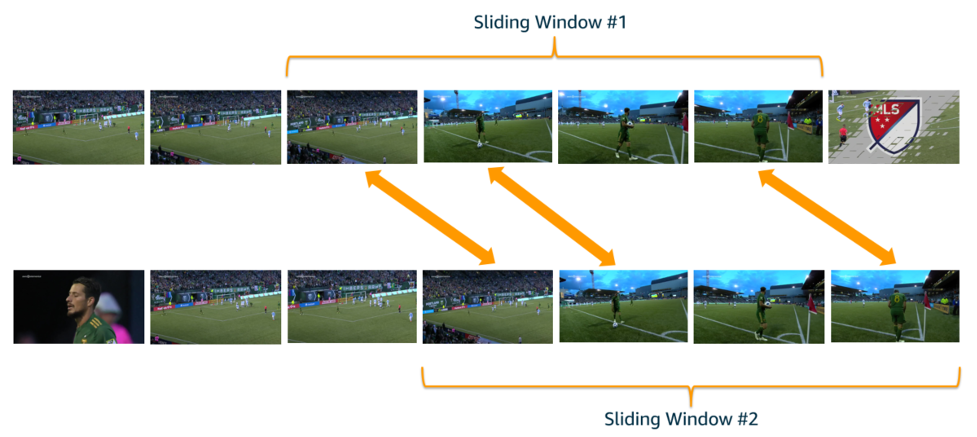
Diagram showing two sets of frame images, with arrows indicating which frames from the top and bottom sets match.
These sliding windows can traverse the entirety of both videos, or you can constrain them so they are always within a certain number of seconds of each other. For example, if you wanted to confirm that there was matching content within a 5-minute window, then you’d constrain the sliding windows so they were never more than 5 minutes apart.
The following is sample Python code that shows how to compare two sets of perceptual hashes using the fuzzy matching approach previously described. Note that hashes1 and hashes2 are lists of the hash values in each sliding window:
num_matches = 0
for hash1 in hashes1:
for hash2 in hashes2:
# subtracting hashes returns the # bits difference
hash_diff = hash1 - hash2
if hash_diff <= config.MAX_DIFFERENT_BITS:
num_matches += 1
hashes2.remove(hash2) # only count each matching item once
break # skip the rest since we've found a match
# how many of hashes_1 were found in hashes_2, and vice versa?
num_compared = len(hashes1)
percentage_match = num_matches / num_compared
matched = (percentage_match >= config.MIN_MATCH_PERCENTAGE)
return not matched
This code assumes you have some configuration constants set. For example, the MAX_DIFFERENT_BITS value would be 16 if you want the frame matching to have a tolerance of 25% difference (since the total number of bits compared is 64). Likewise, the MIN_MATCH_PERCENTAGE would be something like 0.7, if you needed at least 70% of the frames to match within the sliding windows, in order to count as a match.
Additionally, the behavior of the sliding windows can be modified depending on what your goal is. If you are just interested in whether there is any matching content, you can stop searching when the first match is found. If you want to get a list of all common content across two videos, you can use this process to search through the entire contents of the videos by moving the sliding windows across the content.
To summarize, the combination of isolating the middle third of each frame image, comparing frame images using a perceptual hash, and using fuzzy matching with sliding windows allows you to confidently determine whether the two video sources have matching content, and where that matching content occurs.
Deploying on AWS
Now that we know how to check for matching content across two video sources, the next step is to create an architecture that implements that solution on AWS. Here’s a diagram for a sample implementation:
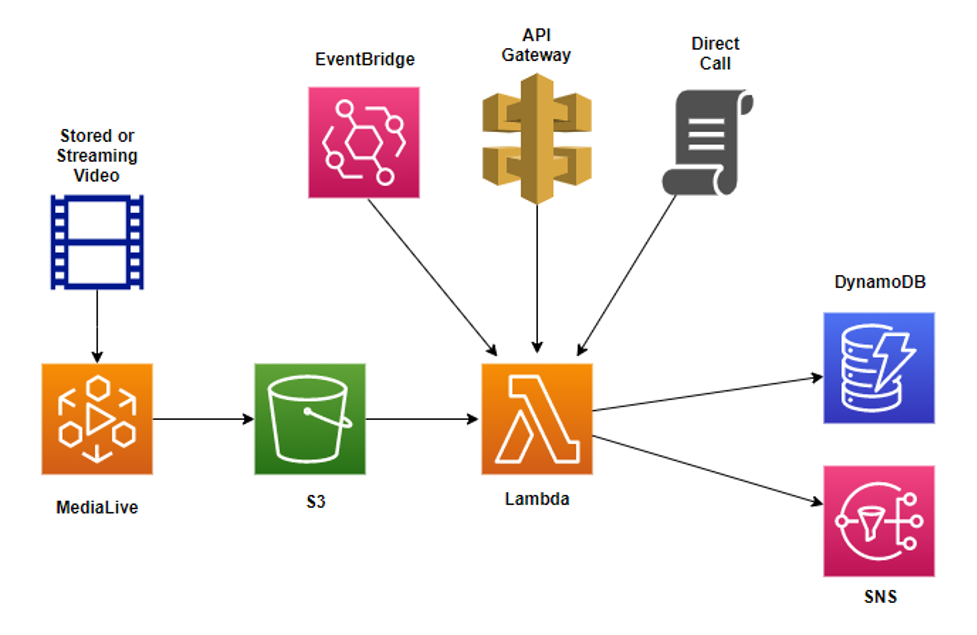
Architecture diagram showing frame images generated by MediaLive, stored in an S3 bucket, then processed by a Lambda function. Output goes to DynamoDB or SNS.
Obtaining frame images from video content can be done with AWS Elemental MediaLive, an AWS service that provides broadcast-grade live video processing. MediaLive can use either stored video files or video streams as inputs, and offers many different types of outputs, including frame captures.
The output frame images are then stored in an Amazon Simple Storage Service (Amazon S3) bucket. S3 is an object storage service that provides essentially unlimited space with industry-leading data availability, security, and performance. Additionally, an S3 Lifecycle policy can be created that automatically archives or deletes the frames images after a certain period of time, which can greatly reduce your costs over the long run.
Once the frame images for both video sources are in the S3 bucket, an AWS Lambda function is used to download them, calculate the perceptual hash values, and then do the comparison. A Lambda function is a serverless compute service that is well suited for tasks like this one due to its built-in scalability and resiliency. By using a Lambda function, you don’t need to provision or manage servers to run the code. It’s an ideal choice for short-running tasks like comparing video streams, although it does have a fixed execution time limit of 15 minutes.
An additional benefit of Lambda functions is that they can be invoked in a variety of ways. In the preceding architecture diagram, three options are displayed: invoking via a call to Amazon API Gateway, invoking on a scheduled basis using Amazon EventBridge, or invoking directly through the command line or via an API call. A scheduled event via EventBridge is well suited for comparisons that need to be done on a regular basis, while invoking the process via an API call through API gateway is good for situations where you wish to run the comparison only as needed.
Finally, results from the Lambda function can be stored or processed in a variety of ways. The architecture diagram shows results being written to Amazon DynamoDB, a key-value, and document database that delivers single-digit millisecond performance at any scale, as well as built-in security and durability. Alternatively, the results could be stored in a relational database or written to a log, depending on the needs of your video processing pipeline.
For more immediate needs, the Lambda function can signal matching content via Amazon Simple Notification Service (SNS), a fully managed messaging service for both application-to-application and application-to-person communication. In this case SNS sends text messages or emails to monitoring personnel, indicating that a lack of sync has been detected, so they can address the situation immediately.
Conclusion
Although video comparison is a complex problem, it can be solved using a combination of extracting the middle third of frame images, comparing them using perceptual hashes, and using sliding windows to ensure that groups of frames are considered rather than single images. This approach handles minor differences between the frames like differing station logos, on-screen advertisements, and closed captioning and other informational icons.
By deploying the solution on AWS, you benefit from scalability, performance, security, and durability. MediaLive allows you to easily produce the frame images needed, and S3 is ideal for storage of these images given its essentially unlimited capacity. A Lambda function is an effective way to package the comparison code, and it can be invoked on a schedule, via an API call, or through a direct call. Detailed information about the result of the comparison can be written into DynamoDB, and the Lambda can use SNS as a mechanism to signal matching or non-matching videos.
If you are interested in applying this video comparison idea to your own business, please have your AWS account manager reach out to the AWS Envision Engineering Americas Prototyping team.