Microsoft Workloads on AWS
Optimizing large-scale migration of SQL Server databases to Amazon EC2 using backup metadata
In this blog post, we explore how the Microsoft SQL Server backup metadata, known as backup headers, can be leveraged when migrating from on premises to Amazon Elastic Compute Cloud (Amazon EC2). This technique is particularly useful when access to source database information is non-existent or only backup files are available with no access to the source SQL Server instance.
Introduction
Migrating databases can be a particularly challenging process when using the backup and restore method. Common factors, such as restoring from split or multi-file backups and moving data and log files to new drives, often make the entire restore process a laborious task that is prone to human error, especially when dealing with large numbers of databases and their respective backup files.
Moreover, when searching for automated database restore scripts, users may either overlook these issues or lack a reliable restoration method. For instance, some scripts may not extract crucial information, such as the database name and other metadata, directly from the backup file. Instead, they might use the backup file’s name as the new database name during the restore and it forces the users to deal with unintended results and challenges for reasons such as:
- What if the name of the backup file was changed (or added with a prefix such as “backup” or “bkp” and suffix such as date in the file name) but the user wants to keep the original database name for the backup that is being restored?
- What if the user receives all the backup files in one shared location, but does not know which were taken as multi-file backups and which were not?
- What if the user wants to automate the automate the ability to change the drive on which database files are stored?
To address these challenges, we will show you how to use backup metadata information to generate database restore commands and run them on the target server in bulk. This configurable script also has an option to restore databases with other configurable options, such as moving the filegroups and moving data and log files to new destination drives at the target.
Solution overview
This solution uses a Transact-SQL (T-SQL) script to read the metadata information available as a header in the database backup file, and use this information to generate restore script to be run on the target SQL Server that is hosted on an Amazon EC2 instance. This way, the solution ensures that the database to be restored is using the original database name (retrieved from the metadata information) irrespective of the name of the backup file(s) used for the restoration. This solution can be incorporated into an existing automated backup and restore process.
Figure 1 illustrates the solution architecture. The source database is the on-premises SQL Server database and the target database is SQL Server on Amazon EC2. To connect the on-premises data center to AWS, we can connect using the public internet or private connections, such as AWS Direct Connect or AWS Site-to-Site VPN. Amazon FSx for Windows File Server with AWS FSx File Gateway is used to store the backup files from the on-premises SQL Server.
For this post, we are using a SQL Server database running on Amazon EC2 as our source database, which closely resembles the setup of an on-premises SQL Server database (Figure 2).
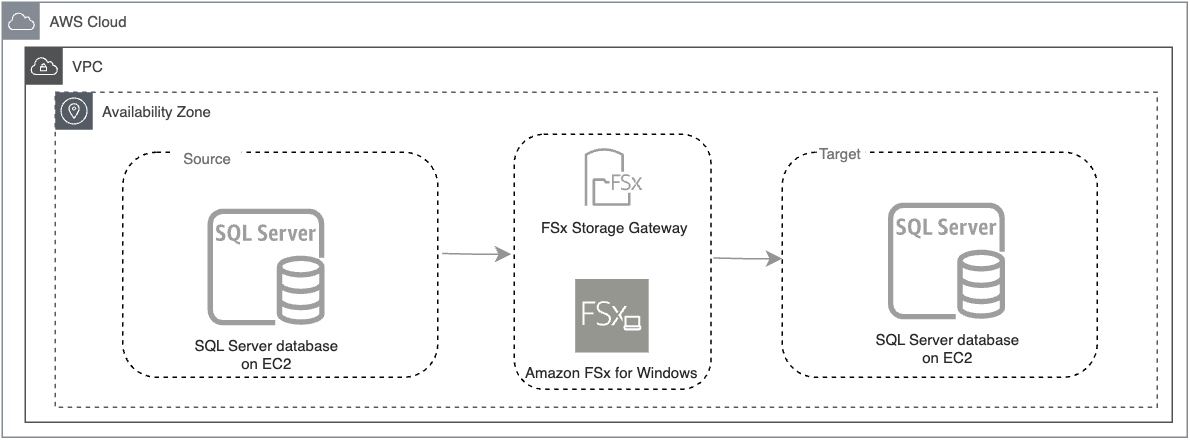
Figure 2: Diagram representing Amazon EC2 writing backup file to Amazon FSx for Windows File Server
Prerequisites
To following prerequisites are required:
- An AWS account
- An Amazon FSx for Windows File Server file system to be used for storing backup files
- A SQL Server instance hosted on Amazon EC2 or on premises that will be used as the source server
- A SQL Server hosted on Amazon EC2 as target server
- An AWS Directory Services for Microsoft Active Directory domain to integrate with the Amazon EC2 instances and the Amazon FSx file system
- A SQL Server login with the
db_backupoperatordatabase role to take backup on source instance - A SQL Server login with the sysadmin role to enable and disable
xp_cmdshellusing advanced SQL Server configuration on the target instance - SQL Server Management Studio (SSMS) installed on the source and target Amazon EC2 instances
- The source SQL Server service should have ‘write’ permission on the Amazon FSx file system to write the backup files
- The target SQL Server service should have read permission on Amazon FSx file system to read the backup files
Setup
Follow these steps to set up your environment for this solution.
1. Create an Amazon FSx for Windows File Server file system and map it to the source and target Amazon EC2 instances.
This solution uses Amazon FSx for Windows File Server for storing and retrieving database backup files. Amazon FSx has built-in support for Windows file system feature, and supports the industry-standard Server Message Block (SMB) protocol to access file storage over a network.
The on-premises source instance accesses the Amazon FSx file system using Amazon FSx File Gateway. You can use the documentation to create an FSx File Gateway and an Amazon FSx File System.
To create an FSx File Gateway on premises, you can deploy a FSx File Gateway Virtual Machine (VM) in your local VMware, Hyper-V, or Linux KVM virtual environment. Alternatively, you can purchase a dedicated physical hardware appliance. If you host a gateway on an Amazon EC2 instance, you will launch an Amazon Machine Image (AMI) that contains the FSx Gateway VM image and then activate it.
In our specific example, we are using the source database server hosted on an Amazon EC2 instance. The Amazon FSx system is directly integrated with AWS Managed Microsoft AD, so we do not need an Amazon FSx File Gateway. Use documentation to create and map Amazon FSx for Windows file system and integrate Active Directory to configure the source and target Amazon EC2 instances. Refer to the Figure 3 .
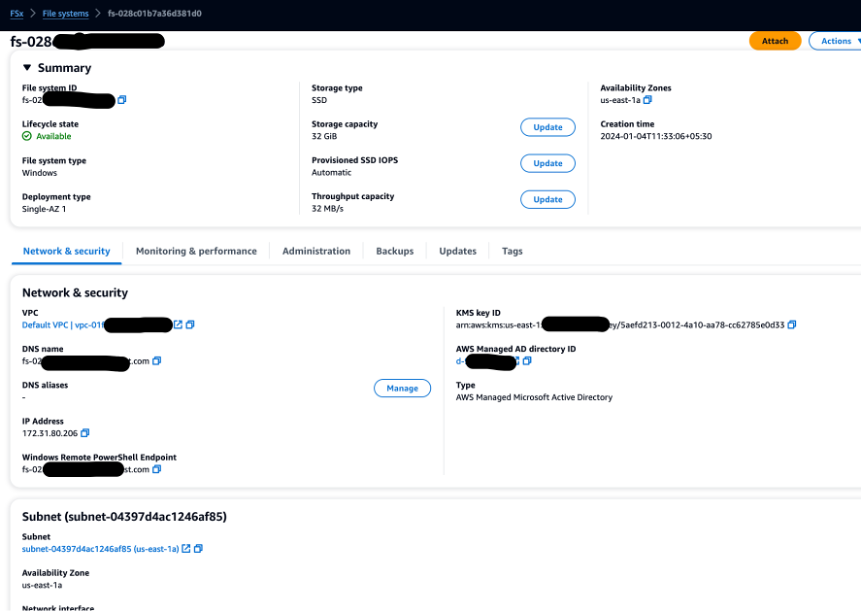
Figure 3: Creating FSx file system for Windows
Figure 4 shows the Amazon FSx file system mapped as a network drive on the source Amazon EC2 instance. A directory (//DB_Backup/) has been created to store backups. We also map the same file system to the target instance.
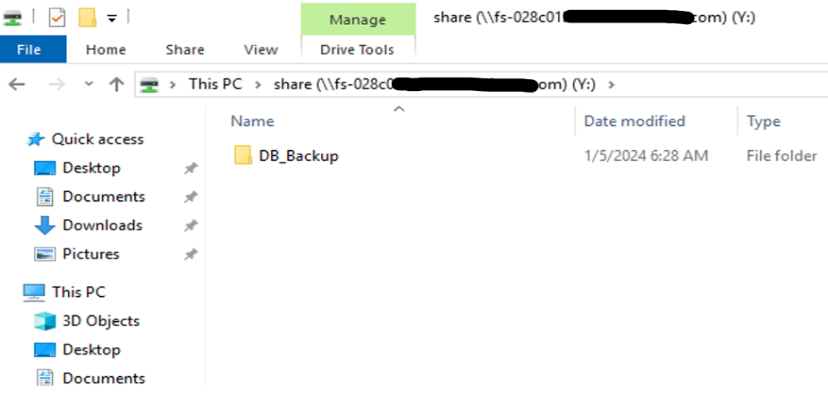
Figure 4: Amazon FSx File system mapped as a network drive on the source Amazon EC2 instance
2. Create backups of databases from the source instance on Amazon FSx.
Connect to the source SQL Server instance database and take backups of user databases that need to be migrated to the target Amazon EC2 instance.
In a mass migration of SQL Server databases, all source databases can be backed up to Amazon FSx, which can be readily accessible from the target instance.
You can use the following sample command, which can also be automated to run for multiple databases. Ensure that you replace the indicated placeholders with values specific to your environment.
USE master
go
BACKUP DATABASE <<User_database>> TO DISK = N'\\<<FSx DNS Name>>\share\DB_Backup\<<backup_file>>.bak'
WITH NOFORMAT, INIT,
NAME = N'<<database name>> Database Backup',
SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 10
GO
In Figure 5, we perform backups from the source database instance for user databases, both in split and single file formats. We ensure that the backup files stored on Amazon FSx have distinct names, avoiding any reference to the database name. This precaution is to prevent confusion and potential errors during the database restoration process on the target.
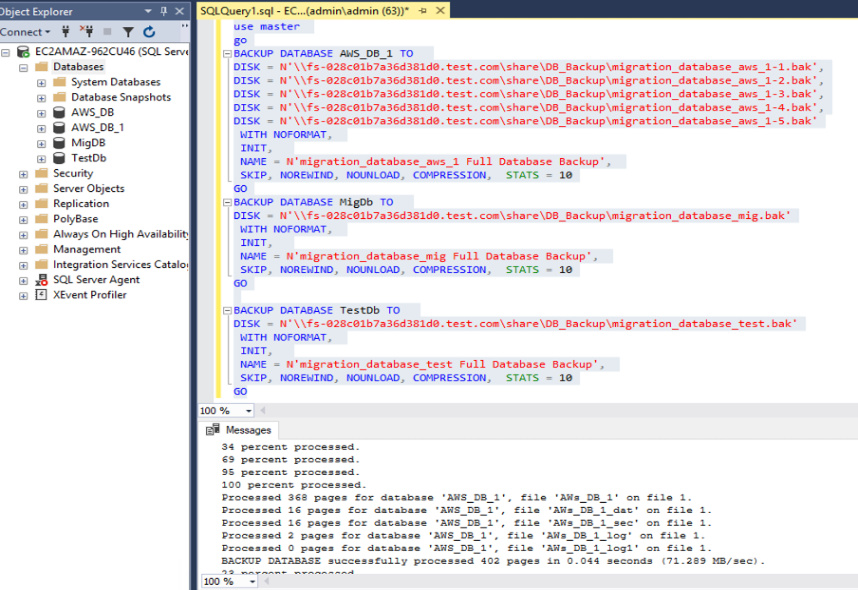
Figure 5: T-SQL script for taking database backup at source in action
Figure 6 shows the backup files created and stored in Amazon FSx file storage.
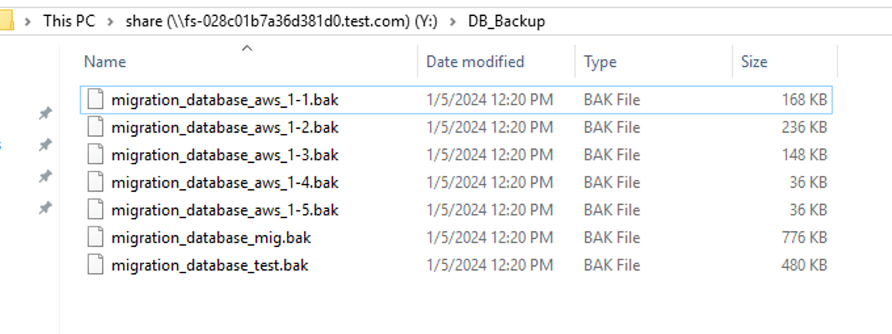
Figure 6: Backup files written on Amazon FSx for Windows File Server
3. Configure and run the T-SQL script to generate a restore script by reading backup files from the source instance.
In the previous step, backup files were generated and are now accessible to the target database instance on the Amazon FSx file system.
In a mass migration scenario, this step is susceptible to human error, potentially leading to the restoration of a database with an incorrect name. To address this issue, we utilize a T-SQL script by configuring it to read files from the specified backup files directory path and data/log directory for restoration on the target.
Connect to the target database instance, modify the SQL variable values in the configurations section as needed, and execute the script. This script checks each backup file, reads its metadata, and generates a valid restore command with the correct database name and configurations.
Note that the script enables xp_cmdshell to list backup files and subsequently disables it after execution. This feature is disabled in SQL Server by default, and its usage may trigger security audit tools. As a best practice, it is advisable to enable it only for the duration of the specific migration task and to disable it afterward.
You can access the T-SQL script from this link.
In Figure 7, the script has been executed and has generated a restore database command. The script also retrieved the original database name from the backup files and has identified those backups, spanned in multiple and sequential files and filegroups.
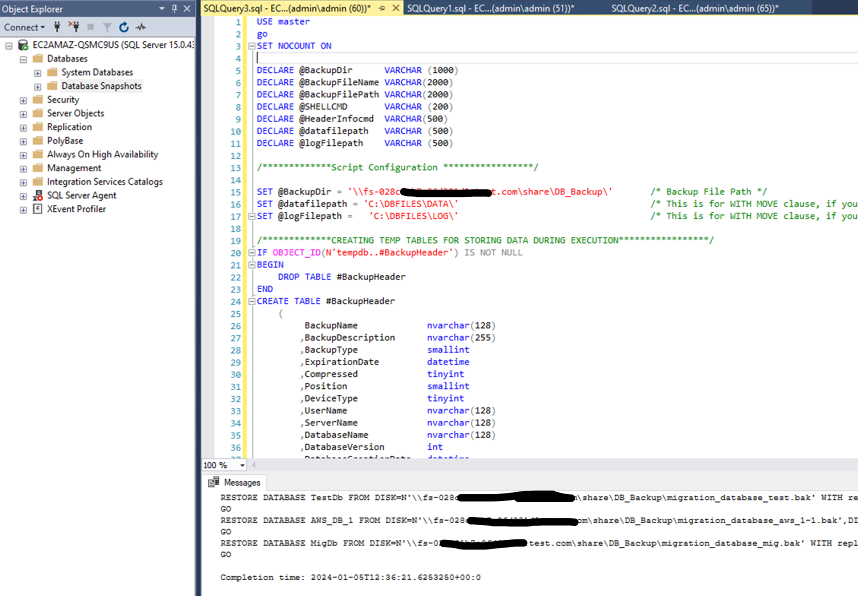
Figure 7: -T-SQL script to for taking database backup at source
You can copy the restore database commands generated as output of the query executed in the previous steps from the query message window and run it at your target database instance to restore databases.
Figure 8 shows the progress of the databases restored on the target after executing the output from the previously executed script.
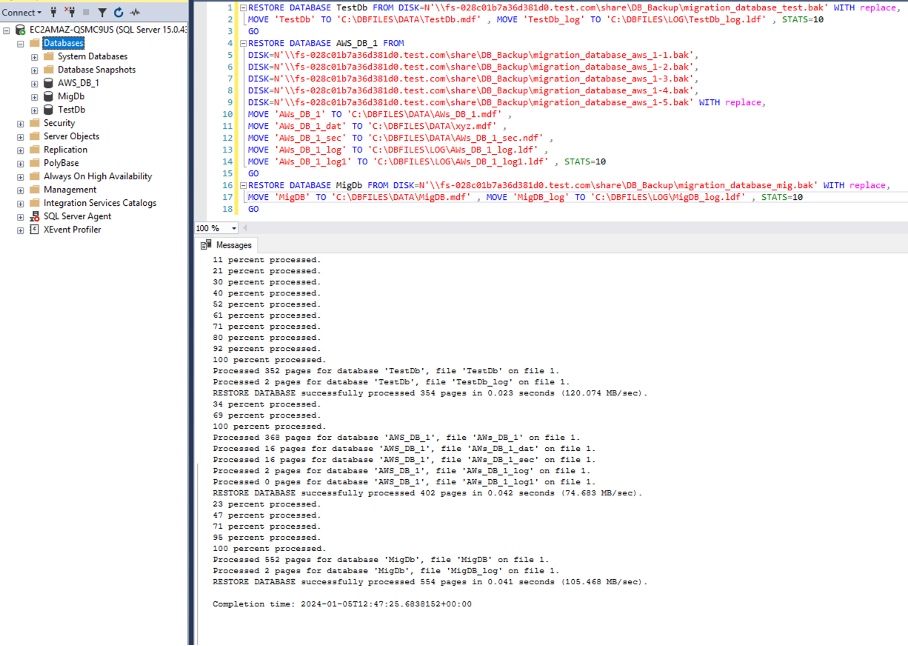
Figure 8: Restoring database with command generated by running the T-SQL script and copying the output from the query message window
Cleanup
Remove all services and components created as part of this solution to avoid incurring charges:
- Sign into the AWS Management Console.
- Choose the AWS Region where your resources are hosted.
- Navigate to the Amazon EC2 console, and select the EC2 instances that you created for this solution. On the Instance state menu, choose Terminate instance.
- Navigate to the AWS Directory Service console and select the AWS Managed Microsoft AD you created. Choose Delete directory from the Actions menu.
- Navigate to the Amazon FSx console. Select the file system you created for this solution and choose Delete file system from the Actions menu.
Conclusion
This blog post emphasizes optimizing the large-scale migration of SQL Server databases from on-premises to Amazon EC2 through the use of backup metadata. The approach tackles typical challenges in the restoration process, particularly in mass migrations, providing a dependable solution via a T-SQL script. We exhibited the practical application of the provided T-SQL script to overcome common challenges associated with restoring databases from backup files.
The solution employs backup header information to retrieve details like the original database name. It then generates a database restore command that users can apply to restore the database at the target, thus making the database migration easier.
You can learn more about backup and restore procedures on SQL Server on AWS in this blog post. You can also learn about additional SQL Server options on AWS.
AWS has significantly more services, and more features within those services, than any other cloud provider, making it faster, easier, and more cost effective to move your existing applications to the cloud and build nearly anything you can imagine. Give your Microsoft applications the infrastructure they need to drive the business outcomes you want. Visit our .NET on AWS and AWS Database blogs for additional guidance and options for your Microsoft workloads. Contact us to start your migration and modernization journey today.