AWS Cloud Operations Blog
Manage your fleet at scale using EC2 Systems Manager
This guest post was written by Michael Baker, who works as a DevOps Engineer for the Infrastructure Engineering team at Bulletproof
The Bulletproof Group Limited has spent many years investing in system automation to assist with fleet management at scale. More recently, we have spent a significant amount of time working with Amazon EC2 Systems Manager. In this blog post, I describe how we have utilized Amazon EC2 Systems Manager on two recent customer engagements. Much has been written about the rapid change within managed services for the public cloud, but the requirement for patching operating systems is ever present. With an increasing focus on security, patching is arguably higher up our customers’ list of priorities than ever before. Our customers increasingly focus on improving the agility of their businesses. So in addition to understanding the basics, including patching, we are now designing pipelines to be both rugged and as fast as possible.
Customer One: Extending Amazon Auto Scaling with automated Amazon Machine Image (AMI) patching and deployment
Bulletproof recently has been charged with building a fully automated patching and deployment pipeline as an extension to an existing environment that was built with, among other things, Auto Scaling from AWS. It was important that this pipeline enabled both scheduled and ad hoc operating system and key service patching. During requirements gathering it became clear that owing to governance policy within our customer’s business we were unable to deliver an entirely automated deployment pipeline. A manual approval step was a part of their key requirements.
After a quick review of tooling in-place within the customer build process, we took a mixture of Bulletproof’s current best practice recommendations and elected to use the following primary toolkit:
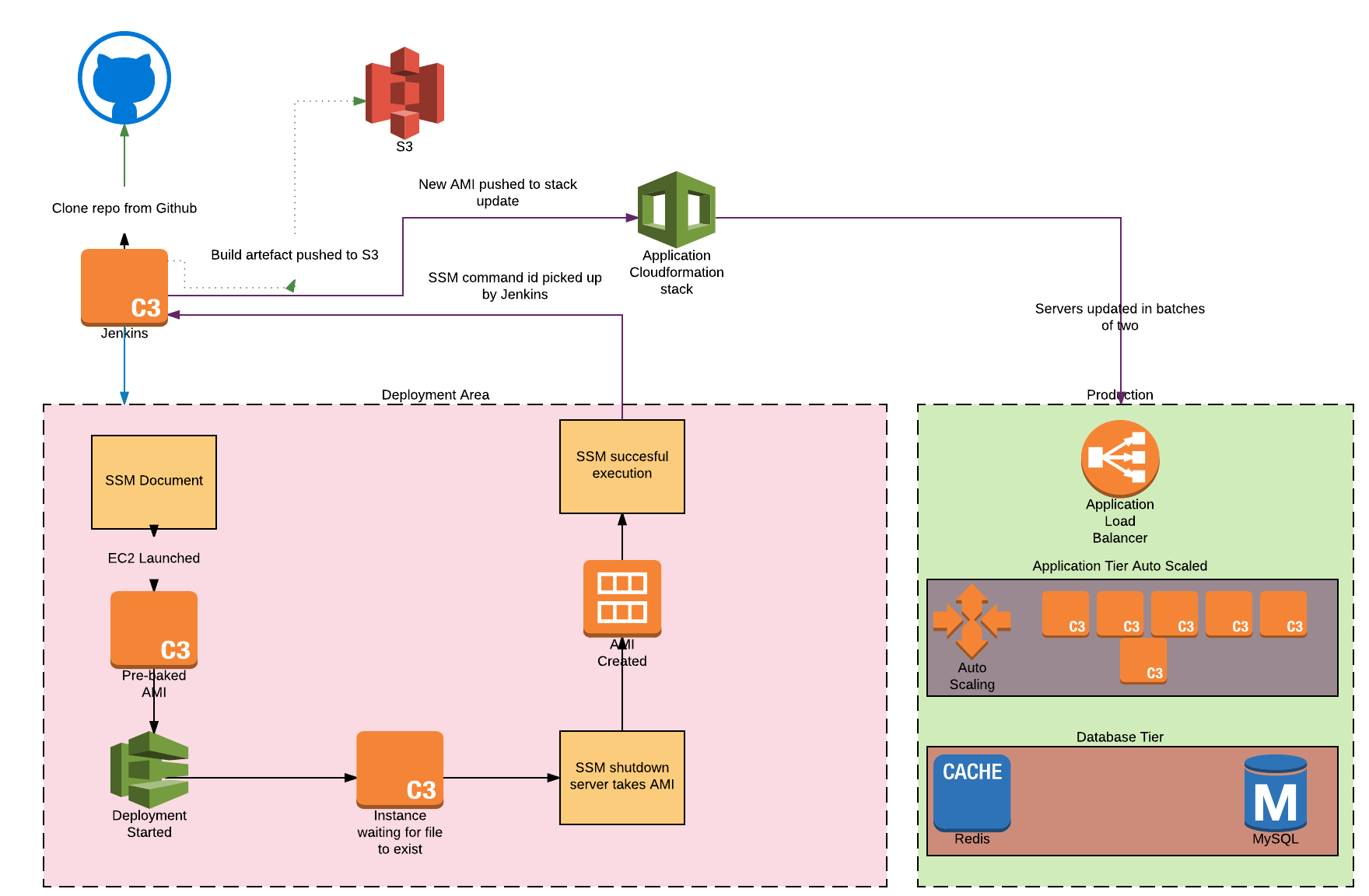
Diving in a little more deeply on the Jenkins configuration, the following key steps occur after our customer initiates the deployment job by logging on to their EC2 instances over VPN:
- We clone the customer’s GitHub repository (to pick up the most recent changes).
- Then we execute a Systems Manager Automation to launch an EC2 instance running the up-to-date customer code.
- Next we send and store the SSM command ID within the Systems Manager Parameter Store. (We can now use this command ID to view the state of the SSM execution.)
- When the Systems Manager job state reaches complete, we wait 60 seconds and then begin a CodeDeploy run. (The delay is to ensure that the instance is available in time for CodeDeploy.)
- Jenkins queries the parameter store with the command ID of the first job executed and asks Systems Manager for the new AMI ID.
- We then initiate a stack update in the relevant CloudFormation stack. This updates the Auto Scaling group configuration with the new AMI. (This happens in such a way as to reduce the chance of service interruption.)
The final key requirement was to enable rapid deployments. Previously even basic change required multiple stakeholders and a brief service outage. Today our customers create change with confidence, knowing that the integration work is successful and it happens without interruption to service. A side effect of rapid deployment is that both Developer and Operations teams are able to collaborate more closely, without one team being slowed down by the other. Continuous improvement or cloud optimization from both teams now happens on a daily basis.
Customer Two: Migration of internal services onto Amazon EC2 Container Service (ECS)
Bulletproof is currently in the process of migrating a number of internal services from our customer’s environment onto Amazon ECS. Because AWS CodeDeploy doesn’t currently support using SSH keys for access to GitHub, we developed a solution to clone data from GitHub into a container. This container contains a deployment for a private GitHub repository.
First, we use a webhook from GitHub to Amazon API Gateway to initiate a Lambda function. That Lambda function then logs the GitHub pull request information into EC2 Systems Manager Parameter Store and calls Systems Manager to perform the artifact build. Next, the repo is cloned into a container. We then have automation systems in place that will create and push a build artifact into an Amazon S3 bucket. Automated testing ensures the validity of the artifact.
After the artifact is built, it’s copied to Amazon S3, and a Systems Manager Automation document is executed. Next, it calls an Amazon SNS topic, which in turn starts an AWS CodeDeploy task via AWS CodePipeline. AWS CodeDeploy deploys the build artifact onto the underlying EC2 instance onto shared storage currently provided by Amazon EFS. After a successful deployment, the containers will automatically reload the underlying process based on a file change that happens post-deploy.
The patching of the underlying EC2 instances is managed with Amazon CloudWatch Events, AWS Lambda, and Systems Manager. On a monthly basis a scheduled CloudWatch Event will trigger an event that calls a Lambda function. This Lambda function then executes a Systems Manager Automation document to to launch an AMI from a pre-baked image because there have been a number of custom changes made to the base AMI. The underlying EC2 instance is then patched with latest updates. After the updates are complete a notification is sent to Bulletproof and the customer via integrations with collaboration software (HipChat/Slack). Lastly, SSM will shut down the server, create the AMI, and update the AWS CloudFormation stack as appropriate.
With the release of Systems Manager as a target for CloudWatch Events Bulletproof is in the process of migrating the automation across. The workflow for this automation will be a CloudWatch Event schedule that will trigger a Systems Manager Automation document with parameters. These parameters are statically set in the event rule. After each AMI baking process is complete the CloudWatch Events parameters are updated with the new base AMI via a Lambda function that is triggered via Amazon SNS after the Systems Manager Automation has been completed.

Summary
The migration to Amazon ECS has provided Bulletproof Support and our customer with the ability to quickly and automatically or manually deploy updates to services. By leveraging AWS Services such as Systems Manager Automation, CodePipeline, and CloudFormation we have managed to achieve an increase of 40% efficiency over our previous static infrastructure. Bulletproof teams can now work from production-like systems on their local machines both online and offline. Since our teams are global this gives them a solution with minimal latency. The teams know that when they commit changes to production the system will behave in a manner that is identical to their local development environments. If an application terminates while it is running we know that Amazon ECS and Elastic Load Balancing health checks will take care of it and bring up a new one. The same applies to the underlying EC2 instances: if they hit capacity a new EC2 instance will be added to the cluster by Auto Scaling. This reduces operational overhead for our support and operations teams. Development teams are now able to run replicas of production systems within the development environment. This minimizes risk and accelerates change.
About the Author

Michael Baker works as a DevOps Engineer for the Infrastructure Engineering team at Bulletproof Group Limited. Bulletproof is an AWS Premium Partner headquartered in Sydney, Australia.