AWS Public Sector Blog
Build a personalized student companion powered by generative AI on Amazon Bedrock

Personalized learning is a pressing challenge in modern education due to the diverse learning needs of students and the limited resources available to educators. Traditional methods of seeking academic support, such as one-on-one consultations or peer study groups, often fall short in providing tailored guidance and bridging knowledge gaps. Compounding these challenges is the inherent diversity of learners, each with distinct strengths, weaknesses, and learning styles, rendering a one-size-fits-all approach increasingly obsolete.
In this rapidly evolving landscape, the advent of generative artificial intelligence (AI) and large language models (LLMs) present a transformative opportunity to address these long-standing educational challenges. LLMs, trained on massive datasets, can understand natural language, interpret meaning, and generate contextually relevant and human-like responses. Retrieval-Augmented Generation (RAG) further enhances LLM output by referencing authoritative knowledge bases outside of their training data before generating a response.
In this post, we explain how to implement a personalized, self-paced student companion that addresses the challenges of tailored learning support. By combining student profiles with the institution’s learning content corpus, we use generative AI models to personalize the student experience, providing teaching support tailored to each student’s unique strengths and weaknesses. We utilize AWS serverless technology, including Amazon Bedrock for invoking LLMs for content generation, Knowledge Bases for Amazon Bedrock to integrate teaching content, and Amazon Aurora Serverless as an updated data store for student grades. This approach harnesses the power of AI to create a personalized, adaptive learning companion that caters to the diverse needs and skillsets of learners.
Prerequisites
To implement the approach outlined in this post, you must have the following:
- An existing Amazon Simple Storage Service (Amazon S3) bucket containing the institution’s learning content corpus, such as course materials and other educational resources
- An Amazon Aurora database instance in the user account that serves as a store for student enrollment data, including enrolled modules and grades.
- An identity provider service set up to manage student identities and grant access to the application. For example, you may use Amazon Cognito to handle user authentication and authorization, although configuring the service is out of scope for this post.
Solution overview
A personalized learning companion must adapt to the unique profile and skillset of each student. Consider the following scenario: Emma, a science enthusiast, and Michael, who struggles with certain concepts, are enrolled in the same course. While Emma would benefit from advanced insights and challenging questions to further her understanding, Michael requires simplified explanations and additional examples to reinforce the material. A personalized learning companion would tailor its approach accordingly, ensuring both students receive customized support aligned with their respective strengths and areas for improvement.
To demonstrate this workflow, this post outlines the architecture shown in the following figure.
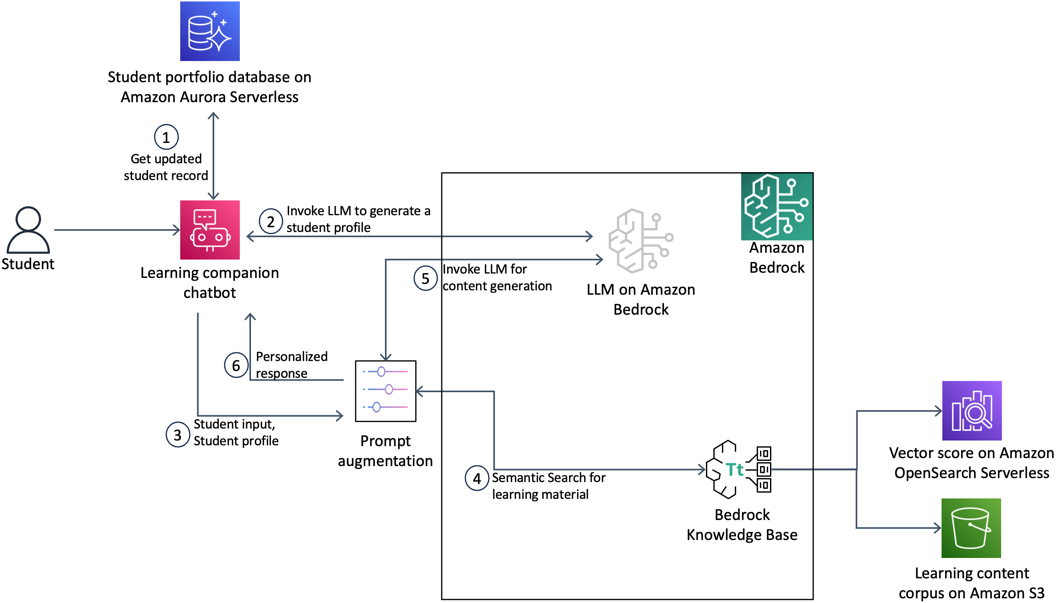
Figure 1. High-level architecture of the personalized learning companion. The main components are the learning companion chatbot, Amazon Bedrock, Amazon Aurora Serverless, Amazon OpenSearch Serverless, and an Amazon S3 bucket.
Solution walkthrough
The workflow to build a personalized student companion follows these steps:
- The application retrieves the student records, including their grades and enrolled modules, from the institution’s database.
- The application combines the student data with a prompt and invokes the LLM to create a personalized student profile.
- The prompt augmentation process integrates the student profile and the input question to tailor the model’s output according to the student’s unique strengths and areas for improvement.
- The application searches the institution’s learning content corpus for material relevant to the student’s input question.
- The LLM is invoked to generate a personalized answer that incorporates both the relevant learning material and the customized student profile.
- The personalized answer, tailored to the student’s individual profile and needs, is delivered to the student.
Step 1 – Retrieve student records
Generating a personalized student profile requires analyzing structured data from the student’s academic record, grades, and enrolled modules. This data typically includes transactional information that is continuously updated throughout the student’s journey within the institution. To effectively utilize this data while invoking the LLM for profile generation, employ the RAG technique. RAG enables the LLM to retrieve and incorporate relevant information from the student record database, ensuring that the generated profile accurately reflects the student’s current academic standing and learning requirements.
The following simple database scheme illustrates the use case, using Amazon Aurora PostgreSQL-Compatible Edition as a database.
CREATE TABLE student ( /* Students table, including student Id and name */
id SERIAL PRIMARY KEY,
name TEXT
);
CREATE TABLE module ( /* Modules table, including module ID and label */
id SERIAL PRIMARY KEY,
label TEXT
);
CREATE TABLE enrollment ( /* Students’ enrolled modules and grades */
id SERIAL PRIMARY KEY,
student_id INTEGER REFERENCES student(id),
module_id INTEGER REFERENCES module(id),
grade INTEGER
);The following code snippet serves to retrieve the student grades from the database.
import psycopg2
def get_student_modules_and_grades(connection_string, student_id):
modules_and_grades = []
conn = psycopg2.connect(connection_string)
cursor = conn.cursor()
query = """
SELECT module.label, enrollment.grade
FROM module
JOIN enrollment ON module.id = enrollment.module_id
WHERE enrollment.student_id = %s
"""
cursor.execute(query, (student_id,))
for row in cursor:
module = {
"label": row[0],
"grade": row[1]
}
modules_and_grades.append(module)
conn.close()
return modules_and_gradesStep 2 – Create a personalized student profile
Based on the output from the previous step, the application invokes the LLM to generate a student profile. The following code snippet illustrates this step using the new Claude 3 Sonnet model that is now available on Amazon Bedrock.
import boto3
import json
PROFILE_PROMPT = """
You are a student companion chatbot tasked with generating a unique profile for a student based on their enrolled modules and grades. The profile should have three parts:
Domain of Speciality: Based on the modules the student is enrolled in, identify their likely domain or field of speciality.
Main Strengths: Based on the grades obtained, determine the student's main strengths or areas of academic excellence.
Areas of Improvement: Based on the relatively lower grades, suggest areas where the student could potentially improve.
Here are the modules the student is enrolled in and the grades they have obtained: {modules_and_grades}
Generate a student profile with the three parts mentioned above, keeping in mind the input modules and grades.
Assistant:
"""
def create_user_profile(connection_string, student_id):
PROFILE_PROMPT = PROFILE_PROMPT.format(
modules_and_grades = get_student_modules_and_grades(
connection_string, student_id))
bedrock = boto3.client(service_name='bedrock-runtime')
messages = [ { "role": "user", "content":
[ { "type": "text", "text": PROFILE_PROMPT} ] } ]
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000, "messages": messages })
response = bedrock.invoke_model(
modelId="anthropic.claude-3-sonnet-20240229-v1:0",
contentType='application/json',
accept='application/json',
body=body )
response_body = json.loads(response.get('body').read()
return response_bodyThis code returns a personalized student profile based on the student’s enrolled modules and grades, structured into three parts: student speciality, strengths, and areas of improvement.
Step 3 – Tailor learning materials with student profiles
Once the unique student profile is generated, you can use prompt engineering to augment the student’s input query with the profile data, enabling the generation of personalized learning content tailored to their academic needs and strengths. This allows the LLM to understand the student profile and adjust the response accordingly. The following is a template for a prompt:
AUGMENTED_PROMPT = """
You are a personalized student companion chatbot. Your task is to provide a detailed answer to the following question while tailoring the response based on the given student profile:
Student Profile: {student_profile}
Learning material: {learning_corpus}
Question: {input_question}
When generating the answer, keep the following in mind:
- Adjust the level of complexity and depth based on the student's strengths and areas of improvement identified in the profile.
- Provide examples and explanations that align with the student's domain of specialty.
- Offer suggestions or additional resources to help the student improve in areas where they may be struggling.
Your personalized answer: """Step 4 – Retrieve content from the institution’s learning corpus
To retrieve content that is relevant to the student input, you will need to create a knowledge base in Amazon Bedrock and upload your institution’s learning content corpus to it. Refer to Create a knowledge base for step-by-step instructions on creating a knowledge base for Amazon Bedrock. Then you can use the Bedrock retrieve API to query the knowledge base and retrieve relevant material related to the student’s input question. The code snippet that implements this step is illustrated, together with the code to invoke the LLM, in step 5.
Step 5 – Invoke the LLM for personnalized content generation
When you have the student profile, the input question, and the relevant material retrieved from the knowledge base, you can use the LLM to generate a personalized answer tailored to the student’s unique needs and strengths. First, create an augmented prompt by aggregating the student profile, the retrieved learning material, and the student’s input question into a single prompt, using the augmented prompt template in step 3. Then, invoke the LLM through the Amazon Bedrock API, using the augmented prompt, to generate a personalized response.
The following code snippet illustrates this process.
def question_answering_and_generation(kb_id, profile, question, prompt):
# Retrieving contextual learning material from Bedrock Knowledge Base
kb_client=boto3.client(service_name='bedrock-agent-runtime')
response = knowledge_client.retrieve(
knowledgeBaseId=kb_id,retrievalQuery={ 'text': question })
answer = response['retrievalResults'][0]['content']
# Augmenting the prompt for LLM invocation
full_prompt = prompt.format(
student_profile=profile, learning_corpus= answer, input_question=question)
runtime_client = boto3.client('bedrock-runtime')
messages = [ {
"role": "user", "content": [ {
"type": "text", "text": full_prompt
} ]
} ]
body = json.dumps({ "anthropic_version": "bedrock-2023-05-31", "max_tokens": 300, "messages": messages })
# Invoke Claude with the agumented prompt
response = runtime_client.invoke_model(
modelId="anthropic.claude-3-sonnet-20240229-v1:0",
contentType='application/json',
body=body
#body=json.dumps({ "prompt": full_prompt })
)
# Return the generated response
return json.loads(response.get('body').read())Finally, return the personalized answer in step 6 to the student.
Example
To illustrate the solution, we will use the example of Emma and Michael previously mentioned in this post. Let’s suppose that both Emma and Michael are enrolled in a mathematics module, and have just attended a geometry course where they have learned about Pythagoras’ Theorem. Emma’s grades state that she is fluent in natural sciences and mathematics, while she can still improve in arts and foreign languages. On the opposite, Michael excels in art and literature but has some difficulties in mathematics and applied sciences. Both will use the student companion chatbot to better understand Pythagoras’ Theorem just seen in the course.
In the following screenshots, we show Emma’s view and Michael’s view about the learning student companion.
The first screenshot illustrates Emma’s experience with the personalized student companion.

Figure 2. Personalized response to Emma’s question about Pythagoras’ Theorem.
The first part of the screenshot illustrates how the learning companion application updated Emma’s student profile based on her current grades extracted from the database in step 2. In the second part, the application used this personalized profile, along with the content from the institution’s learning corpus, to personalize the answer according to her strong background in math and science.
The following screenshot illustrates Michael’s experience with the personalized student companion. Michael’s personalized response caters to his need for improvement in mathematics by taking a visual approach that appeals to his strength in art.

Figure 3. Personalized response to Michael’s question about Pythagoras’ Theorem.
This example illustrates how the same input query results in distinct personalized responses tailored to the unique strengths, weaknesses, and domains of specialization for each student.
Conclusion
In this post, we described a solution that delivers personalized learning content tailored to students’ unique profiles and needs using generative AI. By integrating Amazon Bedrock to invoke large language models with AWS serverless services like Amazon Aurora Serverless and Amazon Bedrock Knowledge Bases, we architected an adaptive system that generates customized explanations based on each student’s strengths, weaknesses, and areas of specialty. This enables educational institutions to provide self-paced, AI-powered academic support at scale, addressing the challenges of diverse learning requirements and limited educator resources. While demonstrated with a simple example from a mathematics course, the principles outlined can be applied across disciplines and learning environments. Overall, this post showcased how AWS’s comprehensive AI and serverless offerings can be leveraged to transform personalized education through the powerful capabilities of generative AI available on Amazon Bedrock.
Read more:
- Develop generative AI applications to improve teaching and learning experiences.
- Watch the fifth episode of the AWS Behind the Cloud vodcast to learn more about how generative AI is influencing the global education space.
- Learn more about how AWS helps education to be always available, personal, and lifelong for everyone.
- Learn more about innovation drivers in higher education and how AWS helps higher education institutions innovate.