AWS Storage Blog
Analyzing request and data retrieval charges to optimize Amazon S3 cost
The demand for data storage has increased with the advent of a fast-paced data environment – creating, sharing, and replicating data at a large scale. Most organizations are looking for the optimal way to store their data cost-effectively, giving them everything they need from their data but without breaking the bank.
Cloud storage provides flexible storage options with a “pay as you go” model. Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance. Moving to Amazon S3 keeps you agile and reduces costs by eliminating over-provisioning, and provides unlimited scale for your storage requirements.
Customers of all sizes leverage Amazon S3 for different workloads and use cases. Many customers are comfortable in identifying the right storage class for their workloads and defining S3 Lifecycle configuration to reduce storage spend. However, customers are looking to deep dive into their Amazon S3 spend and identify new levers to optimize spending without impacting application performance or incurring operational overhead.
In this blog, we discuss how you can go beyond just leveraging the right storage class to optimize your Amazon S3 spend. I detail how to visualize S3 charges related to API requests, identify buckets incurring API request charges, dive deep into API calls being made to S3 buckets, and common steps to optimize API request charges. As is necessary with any cost optimization activities, the information provided should help you understand how the Amazon S3 pricing model works. You should then be able to use or learn more about some of the different tools available to monitor and analyze your spend.
Pricing introduction
Amazon S3 related charges can be broken down into six components:
- Storage charges for data stored in different storage class and is based on per GB data stored.
- Request and data retrieval charges also called API request charges for operations such as GET, PUT, LIST and is based on number of API calls being made.
- Data transfer charges for transferring data out to internet and other Regions.
- Data management and analytics charges for leveraging storage management features and analytics (Amazon S3 Inventory, S3 Storage Class Analysis, S3 Storage Lens, and S3 Object Tagging) that you enable on your account’s buckets.
- Replication charges for charges related to S3 Cross-Region Replication, Same-Region Replication and batch operations.
- Amazon S3 Object Lambda charges.
Apart from storage and data transfer charges, API request charges such as GET, PUT, LIST, HEAD charges are among top contributor to Amazon S3 charges. Most of the current Amazon S3 cost optimization techniques focus on looking into the right storage class and optimizing data transfer charges while API request charges are often ignored.
Request and Data retrieval (API request) charges are based on two factors:
- The kind of API request being made against S3 buckets and objects such as GET, PUT, LIST or Lifecycle transition. Refer to the “Data and retrieval” section of the Amazon S3 storage pricing page for API request charges per 1000 requests.
- The number of API requests being made against the S3 bucket. The API request charges is based on the number of requests made and is irrespective of whether the request is made via console, CLI, or SDK and is irrespective of data size. A GET request charge for an API request made from the console and a GET request charge for an API request made from CLI will be the same. Similarly, a GET request charge for a 1 KB of file and a GET request charge for a 1 MB of file will be the same.
The API request charges are indicated by self-explanatory codes such as PutObject or ListBucket in AWS Cost Explorer and AWS Cost and Usage Report (CUR).
Use AWS Cost Explorer to visualize Amazon S3 charges
AWS Cost Explorer can help to visualize Amazon S3 API request charges and narrow down to the specific API calls contributing the most to your Amazon S3 charges.
- Sign in to the AWS Cost Management and launch Cost Explorer.
- Choose FILTERS – Service and select S3 (Simple Storage Service). Click Apply filters.
- Choose FILTERS – Usage Type Group and select applicable filters such as S3: API Requests – Glacier, S3: API Requests – Standard, S3: API Requests – Standard Infrequent Access and S3: Data Retrieval – Standard Infrequent Access. Click Apply filters.
- As we need to analyze API request, choose Group by –API operation.
- Select Date range for which you would like to analyze the cost and choose Apply.
- This will show a graph with costs and usage for different API request.

- You can choose Download CSV to download the data in a csv format for deeper analysis of API request count and associated charges.
Identify buckets incurring API charges
Once you have identified the top API contributing to Amazon S3 charges, you can use cost and usage data in AWS Cost and Usage Report (CUR) to get bucket-level details. Complete the following steps to analyze the cost and usage data using Amazon Athena and identify buckets for which API calls have been made.
- Enable cost and usage report by following the steps in the creating cost and usage reports documentation.
Select Include resource IDs as you need to get resource level details (bucket details in this case).
- Integrate CUR with Athena to analyze cost and usage data by following instructions in the guide CUR-Athena integration.
- Once the CUR is enabled and integrated with Athena, run the following query to get bucket information and related API request and charges details.
SELECT
"line_item_operation" as API,
"line_item_resource_id" as Bucket,
SUM("line_item_blended_cost") as Cost
FROM <<CUR_TABLE_NAME>>
WHERE "product_product_name" = 'Amazon Simple Storage Service'
AND "line_item_usage_type" not like '%Byte%'
AND "line_item_resource_id" != ''
AND line_item_usage_start_date >= CAST('YYYY-MM-DD 00:00:00' AS TIMESTAMP)
AND line_item_usage_start_date < CAST('YYYY-MM-DD 00:00:00' AS TIMESTAMP)
GROUP BY
"line_item_operation",
"line_item_resource_id"
ORDER BY
SUM("line_item_blended_cost") DESCPut your CUR_TABLE_NAME and date range to get the API charge across different buckets. The information will help you identify the bucket and associated API request charges.
The result should look like the following table:
| API | Bucket | Cost |
S3-GlacierTransition |
Bucket 1 | $$$ |
ListBucket |
Bucket 2 | $$$ |
PutObject |
Bucket 3 | $$$ |
Analyzing API calls made against a bucket
Amazon S3 server access logging provides detailed records for the requests that are made to a bucket. You can enable server access logging and make use of Athena to analyze API calls being made.
- Enable server access log and integrate with Athena. Refer to the documentation on analyzing Amazon S3 logs using Athena.
- Run the following query to identify top IPs making API calls.
SELECT remoteip,requester,useragent,COUNT(*) AS remote_count
FROM <<access_log_bucket>>
WHERE Operation = 'api_call_to_review' AND
parse_datetime(RequestDateTime,'dd/MMM/yyyy:HH:mm:ss Z')
BETWEEN parse_datetime('2021-08-08:00:00:00','yyyy-MM-dd:HH:mm:ss')
AND
parse_datetime('2021-10-08:00:00:00','yyyy-MM-dd:HH:mm:ss')
GROUP BY remoteip,requester,useragent
order by remote_count descYou need to provide access_log_bucket as per step 1 and provide api_call_to_review to track thing such as REST.GET.BUCKET, REST.GET.LIFECYCLE, REST.GET.OBJECT, REST.PUT.OBJECT, and REST.HEAD.OBJECT. Also provide time range for which you want to analyze API calls.
Refer to the documentation on server access log format to understand different columns available for further analyzing API calls.
Different ways to optimize API charges
Once you have identified the API calls and buckets for cost optimization, refer to the following common strategies for optimization.
- GetObject & PutObject:
GetObjectandPutObjectAPI operations are used to retrieve objects from S3 buckets and to add objects to S3 buckets, respectively, and are frequently used API operations. As the cost of GET and PUT API calls are dependent on the number of objects added or retrieved irrespective of object size, you need to refine your strategy:- A large number of small objects can escalate the costs for Get and Put API calls. Review application architecture and consider creating a larger object instead of smaller objects. Alternatively, create a batch for small objects that are uploaded and downloaded at the same time. Example: creating a file based on longer duration such as changes captured in the last 15 minutes or last 30 minutes instead of creating a file every 1 minute.
- Pack objects into a smaller number of files by creating a .tar or .zip file. However, ease of identifying and accessing individual objects within a pack should be considered before creating a .tar or .zip file.
- Use S3 Block Public Access feature to block public access to all of your objects at the bucket or the account level and prevent unauthorized access and unexpected API charges.
- Consider using Amazon CloudFront to reduce the number of get request if most of the objects are static objects. A cost-benefit analysis needs to be done to analyze if adding a CloudFront will reduce cost and meet cost saving expectations.
- Compare S3 bucket storage charges versus S3 bucket API request charges (Get/Put/List) using AWS Cost and Usage report. In case API request charges are a significant part of bucket charges, you will need to analyze if you are using the optimal storage class or if alternate options like DynamoDB will be a good fit for your workload.
- ListBucket: ListBucket is used to list all the objects of a particular bucket. If the ListBucket cost is high for a particular S3 bucket, review your application design to understand why there is a need to use this operation frequently. Depending on need to list bucket, check if the requirement can be met by HEAD request.
- S3 Lifecycle transition: S3 Lifecycle transition rules are used to move objects from one storage class to another storage class or expire objects. There are two types of charges that will be incurred depending on lifecycle transition rules:
- Transition charges: Transition charges are based on the number of objects moved from one storage class to another.
- Early delete charges: Delete charges for not meeting the minimum storage duration of an existing storage class.
You can reduce transition charges by defining S3 Lifecycle configurations for your whole bucket, or for a subset of your objects by filtering based on prefixes, object tags, or object size. Refer to the following options to manage S3 Lifecycle transition-related costs:
-
- Reduce the number of objects to be transitioned:
- Identify the right S3 bucket and prefixes and the right storage class based on access pattern for applying lifecycle transition rules. Use tools such as S3 Storage Class Analysis and S3 Storage Lens to observe data access patterns and to review different metrics such as object size and total object count before defining lifecycle transition configuration.
- Object tags are key-value pairs associated with S3 objects. You can limit the number of objects to be transitioned or expired by defining filters in lifecycle transition rules based on object key prefix, one or more object tags, or both. Refer to the documentation on defining S3 Lifecycle rules based object tags (example: If you want to transition only objects with key=transition and value=glacier to one of the Amazon S3 Glacier storage classes).
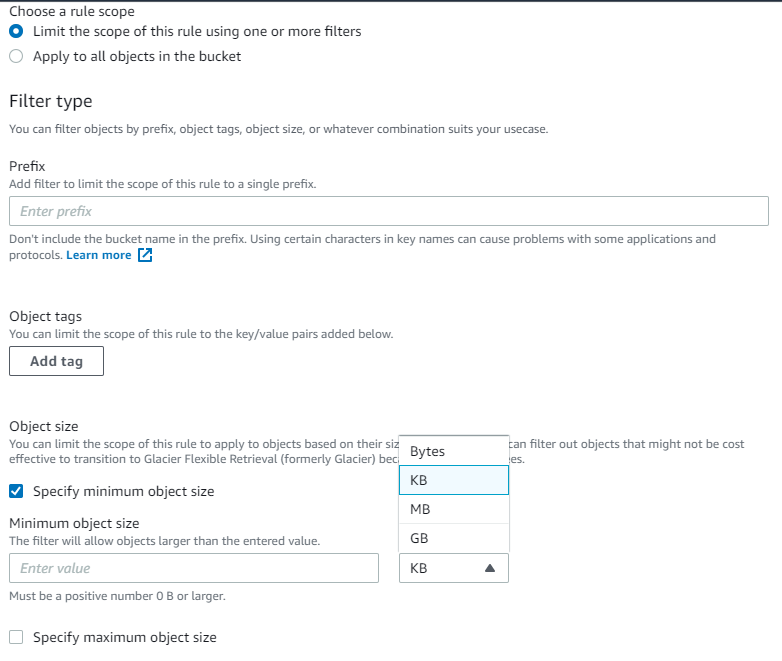
- Launch the S3 console, locate the bucket, and select the Management
- Select Create lifecycle rule.
- Specify filters by selecting Limit the scope of this rule using one or more filters under Choose a rule scope.
- Add filter to limit the scope of this rule to a single prefix by specifying prefix name under section Filter type.
- Select Add tag under Object tags Each tag must match both key and value-optional exactly. The rule applies to a subset of objects that has all the tags specified in the rule. If an object has additional tags specified, the rule still applies.
- Before adding tags for transition purposes, perform a cost-benefit analysis to estimate net savings after including object tag charges. Refer to the Amazon S3 pricing for additional information on costs related to object tags.
- Reduce the number of objects to be transitioned:

-
-
- Leverage options like packing smaller objects into a larger file (.tar, .zip etc.) before transitioning. As transition cost is based on the number of objects transitioned, packing smaller objects into a larger object can reduce the transition charges. Consider retrieval criteria when packing multiple objects into a larger file.
-
-
- Understand the minimum object size and billing requirement for a storage class before applying lifecycle transition rules. S3 Standard-Infrequent Access (S3 Standard-IA) and S3 One Zone-IA storage have a minimum billable object size of 128 KB. As such, transitioning objects smaller than 128 KB to S3 Standard-IA and S3 One Zone-IA will not meet cost saving expectations. Refer to S3 storage classes Performance chart to understand Minimum capacity charge per object for different storage classes.
- You can define lifecycle transition rules with filters based on object size. You may not want to transition small files to save on costs, so you can leverage filters based on Minimum and Maximum object size.
- Understand the minimum object size and billing requirement for a storage class before applying lifecycle transition rules. S3 Standard-Infrequent Access (S3 Standard-IA) and S3 One Zone-IA storage have a minimum billable object size of 128 KB. As such, transitioning objects smaller than 128 KB to S3 Standard-IA and S3 One Zone-IA will not meet cost saving expectations. Refer to S3 storage classes Performance chart to understand Minimum capacity charge per object for different storage classes.
-
- Apart from access pattern, review your data retention requirements and the minimum storage duration of each storage class before creating an S3 Lifecycle rule to transition or expire objects. S3 Standard-IA and S3 One Zone-IA storage are charged for a minimum storage duration of 30 days, while S3 Glacier Instant Retrieval and S3 Glacier Flexible Retrieval have a minimum storage duration of 90 days. Refer to the S3 storage classes performance chart to understand the minimum storage duration for different storage classes. Transitioning and expiring objects before the minimum storage duration of a storage class is met leads to
DeleteObjectcharges, which are based on pro-rated charges for minimum storage duration defined.
- Apart from access pattern, review your data retention requirements and the minimum storage duration of each storage class before creating an S3 Lifecycle rule to transition or expire objects. S3 Standard-IA and S3 One Zone-IA storage are charged for a minimum storage duration of 30 days, while S3 Glacier Instant Retrieval and S3 Glacier Flexible Retrieval have a minimum storage duration of 90 days. Refer to the S3 storage classes performance chart to understand the minimum storage duration for different storage classes. Transitioning and expiring objects before the minimum storage duration of a storage class is met leads to
- Use Amazon S3 Storage Lens to get visibility into object storage usage and activity trends. S3 Storage Lens delivers more than 30 individual metrics, including object count, average object size, put requests, get requests, and list requests, which can help you fine-tune lifecycle transition rules as well optimize API request charges.
- Enable your Amazon S3 storage lens dashboard as per the steps given in this S3 Storage Lens blog post.
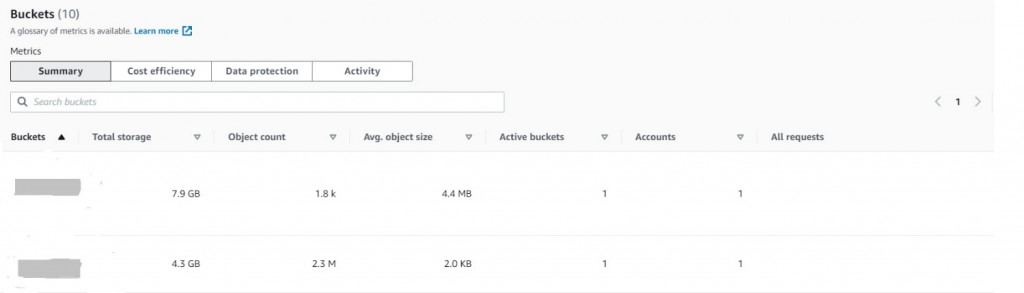
- Launch the dashboard and select the Buckets. If you want to analyze a particular prefix, select the Prefixes tab.
- Review metrics like Total storage, object size, and Object count to estimate transition cost and finalize lifecycle transition rules.
-
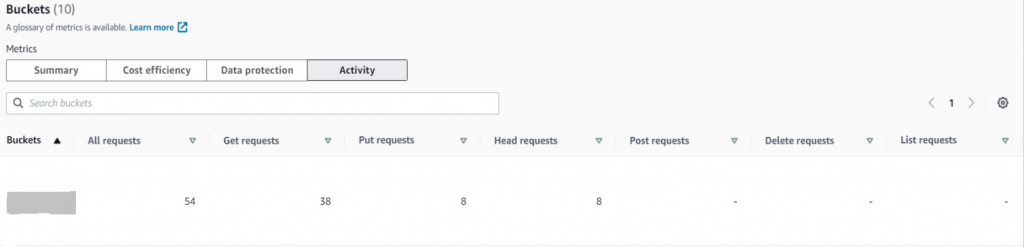
- Analyze API Request using metrics such as Get requests, Put requests, Head requests, List requests, and more.
Cleaning up
To avoid ongoing charges to your account, delete the resources you created in this walkthrough.
- Stop Amazon S3 server access logging.
- Stop Amazon S3 management and analytics tools used, such as S3 storage class analysis and Amazon S3 Storage Lens.
Conclusion
In this blog, I covered visualizing and understanding charges associated with different Amazon S3 API requests. I also demonstrated how to identify API request charges associated with different S3 buckets using cost data, usage data, and server access logs, and reviewed some of the strategies to optimize API request related charges.
Amazon S3 customers have long been optimizing cost using right S3 storage classes and by performing data cleanup. Now you can take it a step further; understanding how Amazon S3 request and data retrieval operations (API request) are charged and common approaches to reduce API request charges allows you to explore further optimizing your Amazon S3 costs. Awareness of API request charges can help administrators and development team members to make the right architectural and design decisions while preventing any cost-related shock.
Thanks for reading this blog post on optimizing request and data retrieval charges to reduce Amazon S3 cost. If you have any comments or questions, don’t hesitate to leave them in the comments section.