AWS Storage Blog
Connecting AWS Outposts to on-premises data sources
Millions of customers such as startups, enterprises, and leading government agencies are using AWS to lower costs, become more agile, and innovate faster. There are some workloads that must remain on-premises in order to interact with data that cannot, for variety of reasons, move to an AWS Region. Enter AWS Outposts.
AWS Outposts is a fully managed service that extends AWS infrastructure, services, APIs, and tools to virtually any data center, colocation space, or on-premises facility for a truly consistent hybrid experience. AWS Outposts is ideal for workloads that require low latency access to on-premises systems or local data storage.
There are a variety of data sources on-premises that you might want to connect to from your AWS Outposts. These data sources include block and file storage arrays accessed over NAS or iSCSI, databases, and mainframes.
In this blog post, I cover different use-cases for connecting AWS Outposts to on-premises data sources. I then cover a specific scenario that highlights a use-case for connecting AWS Outposts to an on-premises storage array.
Use cases
Let’s talk about a few use cases for connecting AWS Outposts to on-premises data sources.
Low Latency to on-premises workloads: Customers have workloads that require real-time processing and need low-latency access to on-premises systems. As an example, many financial institutions use mainframes to process financial transactions. These organizations often look at carefully modernizing their mainframe applications by decoupling components and moving them to the cloud. However, due to increased aggregate latency between calls to the mainframe, they often aren’t able to do so. AWS Outposts allows you to modernize your mainframe applications for AWS while still providing low latency.
Local data processing: Customers that have large datasets, such as IoT device sensor data or sensors from autonomous vehicles, must often process this data locally. AWS Outposts allows you to process data locally without having to send back to an AWS Region. This data can be ingested into services that consume Amazon EBS, such as Amazon EC2 and Amazon EMR. As announced in late 2019, AWS customers will be able to ingest data from on-premises to Amazon S3 on Outposts in late 2020.
Local data processing use case
Let’s start with a scenario using the local data processing use-case described in the previous section.
An autonomous vehicle company wants to perform analytics on sensor data they get from their fleets. They ingest 5 PB of data every week to existing storage arrays on-premises. Their data warehouse and analytics reside in an AWS Region. Depending on the file size, this dataset could take 18 hours (or more) to transfer to the Region over a 10 Gbps AWS Direct Connect network connection. They use Amazon EMR to process the data, which takes the dataset from 5 PB down to 800 TB. From there, they use other services such as Amazon Athena to perform analytics. We can stop the scenario here. With AWS Outposts, you can process that 5 PB of data with Amazon EMR locally. This would reduce the 5 PB of raw data down to 800 TB, effectively decreasing the time between data ingest to analysis by 600% (from 18 hours to just under 3 hours).
Now let’s look at what this scenario technically looks like on AWS Outposts. We don’t go into the basic architecture of AWS Outposts or how it connects back to an AWS Region in this post, but click here to read about that. The following diagram depicts how AWS Outposts connects to your on-premises network:
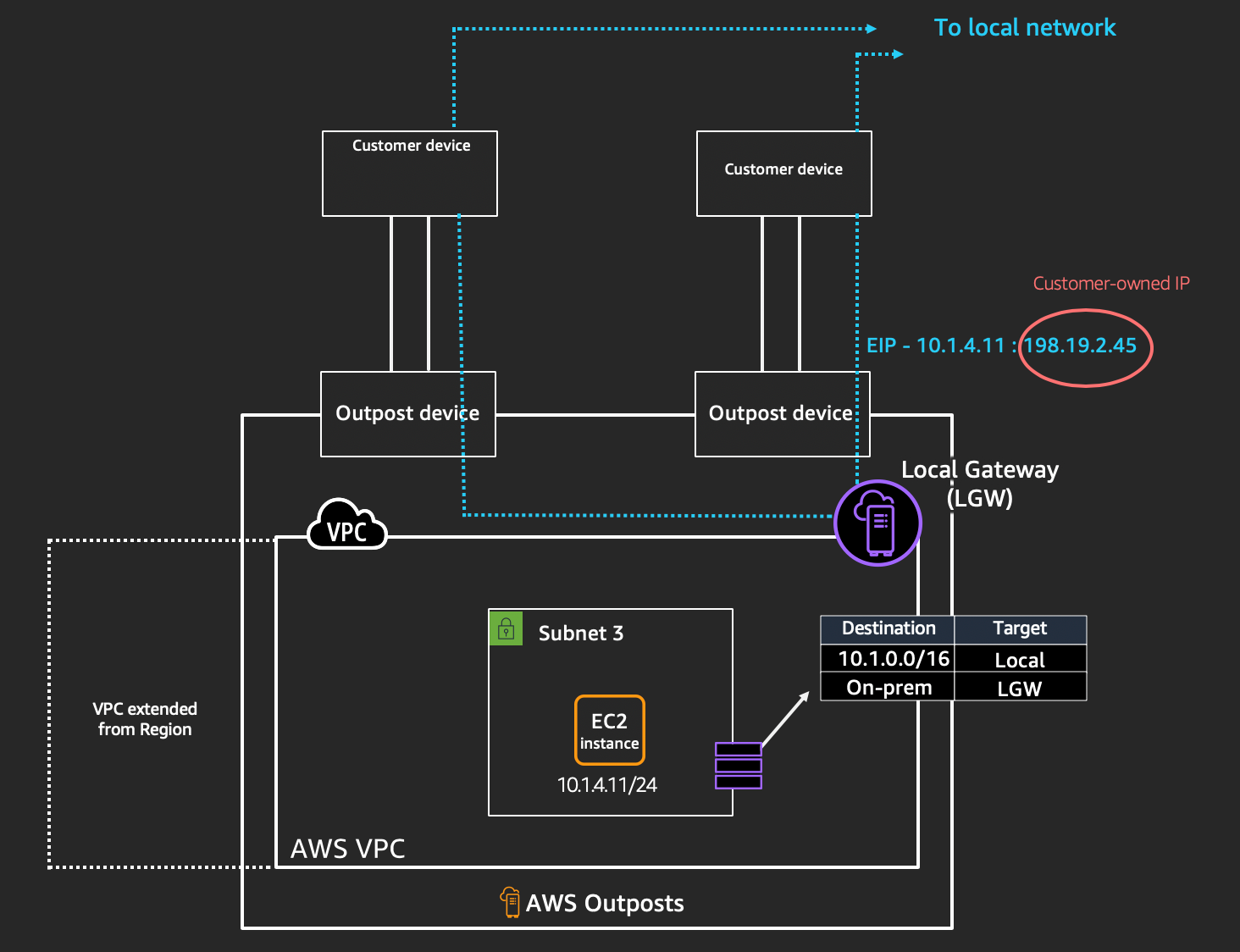
In this diagram, you can see that when instance Y (10.1.4.11) wants to talk to an on-premises data source, it traverses the local gateway (LGW) and gets translated (NAT) to the customer-owned IP (CoIP) (198.19.2.45). The reverse is also true, when you have an on-premises data source or workload that wants to talk to instance Y, it flows through your on-premises network using the same CoIP. Once it hits the LGW, it translates to the Amazon Virtual Private Cloud (VPC) IP (10.1.4.11) and gets sent to the instance.
A few things to note here:
- An entry in the route table points hosts running in your VPC on AWS Outposts to your local area network (LAN) via the LGW. You can read more about the LGW here.
- The LGW performs a 1:1 network address translation (NAT) between the VPC and LAN networks. This operation requires that you assign a block of addresses on your LAN to the LGW, we call these blocks CoIP.
Configuring CoIP
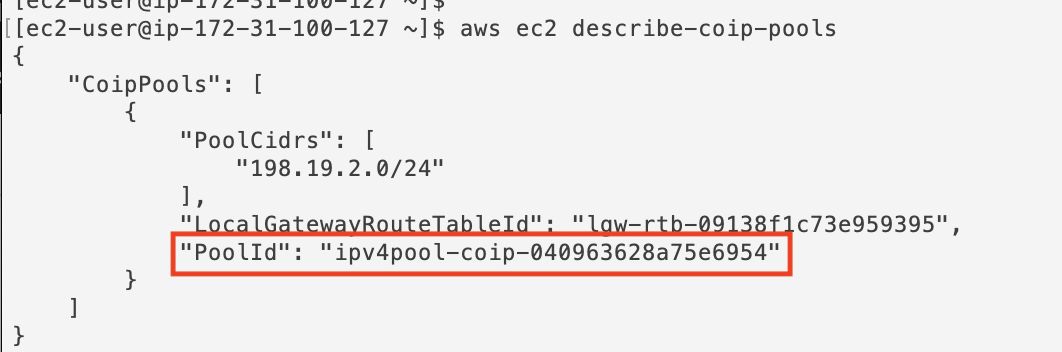
How does an Amazon EC2 instance running on AWS Outposts get a CoIP? Today, this is something you must manually set. To assign a CoIP to an EC2 instance, you must first allocate an address from your CoIP pool. This is done through the AWS Management Console or the EC2 API. In this example, we are using the API via AWS CLI. To allocate an IP address, you must know the CoIP pool ID.
To get your CoIP pool ID, you must run aws ec2 describe-coip-pools:
To allocate a new IP address, you must run aws ec2 allocate-address --customer-owned-ipv4-pool <pool id>:

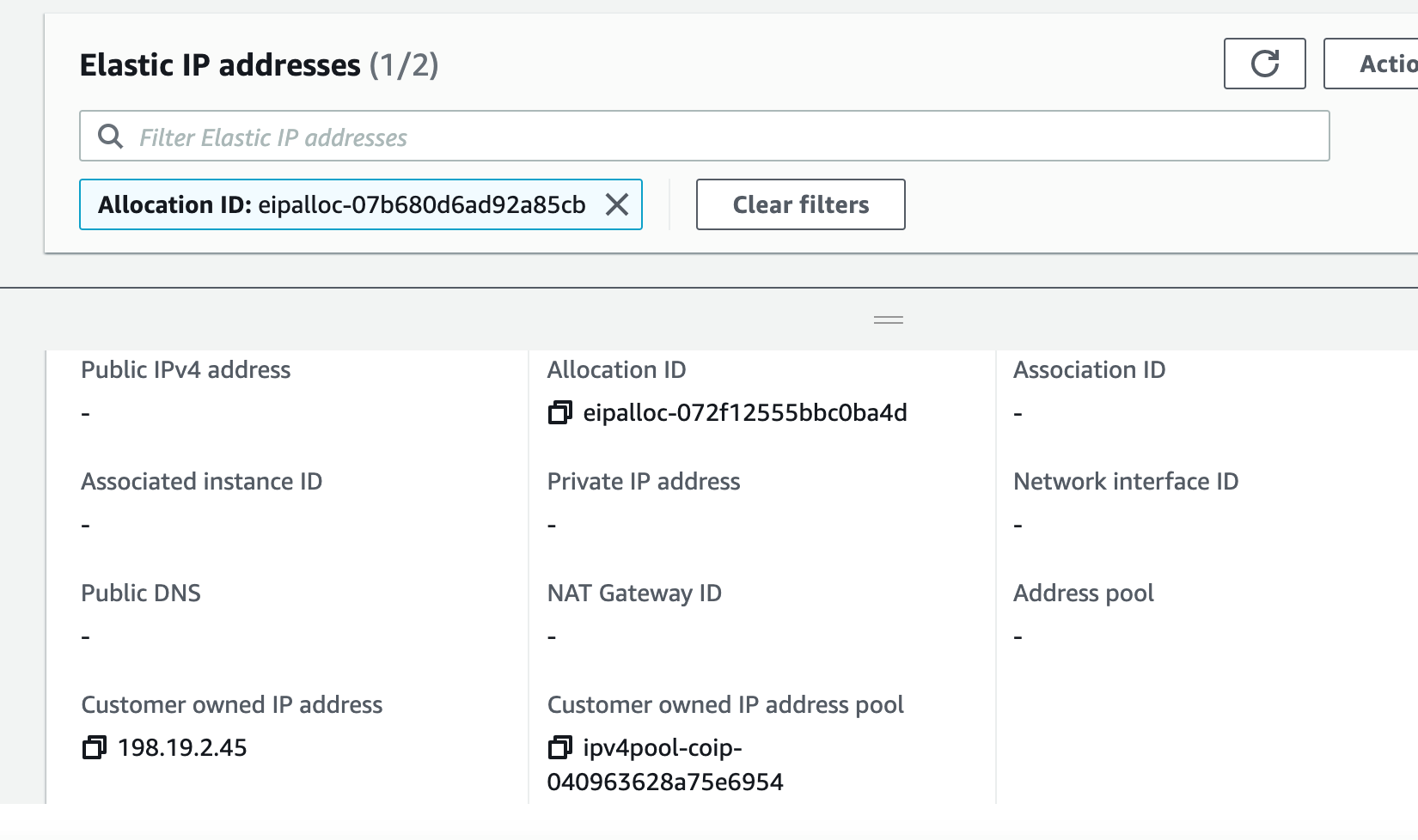
You can’t to use the AWS Management Console to allocate a specific IP address from the CoIP pool. To allocate a specific IP address, use the allocate-address command, as we did previously, and use the --address option.
Once you’ve allocated the IP address, it shows up as available in the console (198.19.2.45):
Given our scenario, here’s what the dataflow looks like:
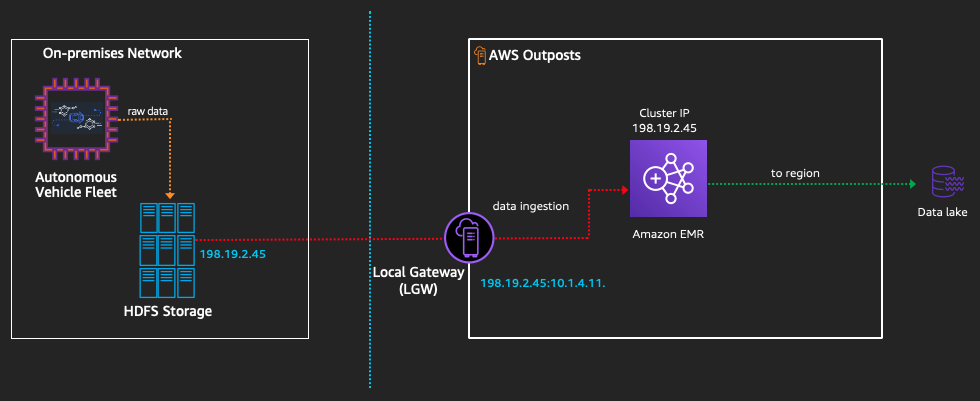
Dataflow in this case is as follows:
- Data from the autonomous vehicle fleet is pushed into a Hadoop Distributed File System (HDFS) compatible storage array (5 PB).
- Data is ingested from the HDFS compatible storage array into Amazon EMR on AWS Outposts via the LGW. The LGW then translates the on-premises IP of the HDFS array, 198.19.2.45, to the CoIP IP for the EMR cluster, 10.1.4.11.
- Once the data is processed (now 800 TB), it’s pushed to the data lake in the AWS Region.
Considerations for connecting AWS Outposts to your LAN
- Data sources must be accessible via IP address and domain name system (DNS) name.
- Ensure that your end-to-end uplinks from the AWS Outposts through to your on-premises data source is sized properly.
- Make sure that your instances are sized properly to get required network speed.
- Make sure you have DNS resolution between instances on the AWS Outposts and data sources on-premises and vice versa.
Conclusion
In this post, I outlined use cases for connecting your on-premises data sources to AWS Outposts. I walked through a scenario for how data flows from an AWS Outpost to your on-premises network, and how using AWS Outposts can solve for local data processing requirements. With AWS Outposts, you can now move workloads to AWS that weren’t able to move due to a dependency on data sources that must remain on-premises. For more information on AWS Outposts, you can view the AWS Outposts user guide. For an in-depth look at AWS Outposts networking, check out this video:
Thanks for reading this blog post. If you have any comments or questions, please don’t hesitate to leave them in the comments section.