AWS Storage Blog
Easily ingest data into AWS for building data lakes, archiving, and more
An increasing amount of data is being generated and stored each day on premises. The sources of this data range from traditional sources like user or application-generated files, databases, and backups, to machine generated, IoT, sensor, and network device data. Customers are looking for cost optimized and operationally efficient ways to store and access their data. Increasingly, customers are also seeking to enable integration paths for their data so they can do more with it, such as building data lakes to gain deeper insights through analytics.
When customers think of adopting new data storage services to meet requirements like cost and performance optimization, scalability, and operational efficiency, there is usually an element of data migration involved. Take, for example, customers looking to seed their data lakes with historical data so they can enrich their machine learning models and enable greater accuracy for future predictions.
When speaking with our customers, they often look to AWS to invent and simplify optimal data transfer mechanisms to help them on their data migration journey to AWS. Customers want to move away from the complexity of scripts, and custom tooling, to more repeatable design patterns, enabling them to focus their resources on innovation where it matters most to their business.
In this blog, I cover some of the key AWS Storage services that can help you understand the options you have available for your data transfer requirements. I also provide demo videos showing the AWS services in action, so you can visualize their benefits. In addition, I supply links to hands-on workshops that provide guides for deploying, configuring, and transferring data using these services.
Why customers transfer data into the AWS Cloud

Data lakes: Customers are ingesting and centralizing data into the highly available, scalable Amazon S3 storage service to build data lakes and centralize data processing capabilities. By doing so, they can then obtain greater value out of their aggregated data.
Application data migration: Customers migrate application data into AWS so that they can leverage the benefits of fully managed AWS file services, such as Amazon EFS and Amazon FSx for Windows File Server. With these services, customers can increase agility and operational efficiency.
Sharing data: Customers are increasing productivity and business value by sharing data, at local and global scale.
Backups: Customers are storing highly durable and cost effective backups of their data in Amazon S3, to meet business and compliance requirements.
Archiving data: There is an ever growing amount of data, and customers are archiving their long-term retention-based data to AWS. This enables customers to move away from aging, costly, and complex on-premises storage infrastructure to leverage greater cost savings and operational efficiency.
Potential challenges when ingesting data into AWS
Options: There are many options to consider; should you transfer data online over the wire, or offline, or a combination of both using a seed and sync approach? Which option is optimal for your use case, data transfer timelines, and fits into your business process?
Speed: What’s the fastest and simplest way to transfer data, and which method can seamlessly scale to meet varying volumes and dataset characteristics, such as small file vs large file transfers, for optimal transfer speeds?
Time and effort: The time and effort required in building and testing bespoke data transfer code. Then, determining who is going to maintain it, and re-write it for different use cases with the aim of making it a repeatable mechanism is challenging.
Complexity: It can get complex trying to create code to perform functions such as preserving file metadata between source and target, or performing post data transfer integrity verification. It is paramount to ensure that the data you copy across to the target is the same as it was on the source.
As you can see, this can quickly get complicated and can become a time-bound exercise.
What AWS data transfer options are available?
In this blog, I am going to look at three high-level data ingest scenarios and the simple, repeatable AWS services that you can use as data ingest and transfer mechanisms for each scenario:
- Populating your data lake with vast amounts of data, which can originate from different sources
- Ingesting millions of files from your file shares to AWS based file services
- Storing backups and archiving data
Before we look into these three scenarios, let’s get familiar with the AWS Storage services that we are going to discuss.
AWS Storage Gateway: File Gateway
AWS Storage Gateway offers three different types of gateways – File Gateway, Tape Gateway, and Volume Gateway. File Gateway is a service that enables hybrid cloud architectures that allow for low latency access to your hot data in its local cache, while all your data is stored in Amazon S3.
File Gateway can be deployed either as a virtual or hardware appliance. It enables for you to present a network file system (NFS) such as Server Message Block (SMB) in your on-premises environment, which interfaces with Amazon S3. In Amazon S3, File Gateway preserves file metadata, such as permissions and timestamps for objects it stores in S3.

File Gateway asynchronously uploads data from its cache to your Amazon S3 bucket when it is saved by your application to the file share. At the same time, File Gateway provides access to that data via the same file share.
One benefit of using the File Gateway is that it converts files to Amazon S3 objects in your Amazon S3 bucket. In your Amazon S3 buckets, objects can be retrieved and accessed in their native file format, so you can do more with your data. Lastly, the SMB shares can also integrate with Microsoft Active Directory to minimize any changes in your environment.
AWS DataSync
AWS DataSync is an online data transfer service that simplifies and accelerates the transfer of data, where it can be used to transfer data into and out of AWS. DataSync uses a purpose-built protocol that takes advantage of many acceleration techniques.
It’s simple to use. You deploy the DataSync agent as a virtual appliance in a network that has access to AWS, where you define your source, target, and transfer options per transfer task. It allows for simplified data transfers from your SMB and NFS file shares, and self-managed object storage, directly to any of the Amazon S3 storage classes. It also supports Amazon EFS and Amazon FSx for Windows File Server for data movement of file data, where it can preserve the file and folder attributes.
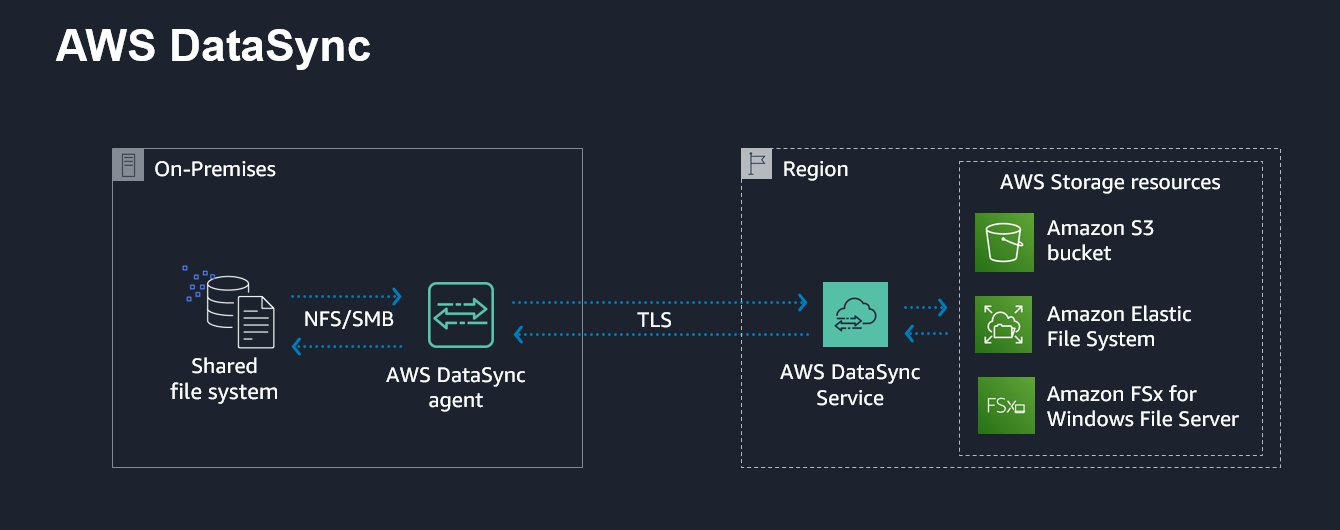
Data security, integrity, and migration visibility are important aspects of any data migration, where DataSync encrypts data in transit and supports encryption at rest. DataSync can validate data transferred in transit and at rest, where it also provides a progress dashboard and is integrated with Amazon CloudWatch for metrics and logs.
Each AWS DataSync agent can be used for different data transfer tasks, so it can be used as a reusable data transfer mechanism across different use cases. Think of the benefits that DataSync can provide when you’re operating at a scale of hundreds of millions of files or have petabytes of data to transfer. With DataSync’s overall simplicity and comprehensiveness, you can move away from bespoke and complex tooling.
Check out the AWS DataSync customers page to get a better understanding of how some of our customers are using DataSync.
AWS Transfer Family – AWS Transfer for SFTP, FTPS, and FTP
AWS Transfer Family offers fully managed support for transferring files over SFTP, FTPS, and FTP directly into and out of Amazon S3. Data transfers using AWS Transfer Family leverage highly available file transfer service endpoints with automatic scaling capabilities, eliminating the need for you to manage file transfer related infrastructure.

AWS Transfer Family is simple to use. You can deploy an AWS Transfer for SFTP endpoint in minutes with a few clicks. Using the service, you simply consume a managed file transfer endpoint from the AWS Transfer Family and configure your users and an Amazon S3 bucket to use as your storage location. It’s secure and compliant, where IAM roles are used to grant access to the Amazon S3 bucket from file transfer clients. Using AWS Transfer Family and its managed endpoints, you can seamlessly migrate your file transfer workflows by maintaining existing client-side configurations for authentication, access, and firewalls. In the end, nothing really changes for your customers, partners, or their applications.
AWS Snow Family
The AWS Snow Family provides highly secure, physical storage devices used to transfer data into and out of AWS when you have limited or no network bandwidth.
The Snow Family includes portable devices such as AWS Snowcone and AWS Snowball Edge, which are secure, ruggedized, physical devices that you can have shipped to your location. Using these Snow devices, you can execute compute applications at the edge, and you can ship the device and your data to AWS for offline data transfer. With Snowcone, you can even transfer data online with AWS DataSync from edge locations. The AWS Snow Family is ideal for bulk data transfers where you don’t need the data immediately or have limited to no network bandwidth. AWS Snow Family devices are also useful if you want compute capabilities for data transformation at the edge.
The Snow Family also includes AWS Snowmobile, which enables very large offline bulk transfers.
You can copy your local data directly to AWS Snowcone devices using the NFS interface, and to AWS Snowball Edge devices through the Amazon S3 or NFS interface. Alternatively, you can use AWS OpsHub, a graphical user interface, to simply drag and drop your data to be transferred. When your data transfer is complete, you send the Snow device back to AWS, where your data is uploaded to your Amazon S3 bucket. The Snowcone and Snowball Edge devices also provide internal compute capacity along with internal storage capacity. This enables customers to pre-process data they are storing on the devices into a format they desire before being ingested into Amazon S3. This capability ensures that the data is ready to be consumed by a data lake or client applications in AWS.
Now that we are familiar with a few of the AWS Storage services, let’s apply them to three common data ingestion scenarios.
Scenario 1: Ingesting data into Amazon S3 to populate your data lake
There are many data ingestion methods that you can use to ingest data into your Amazon S3 data lake. Some applications even support native Amazon S3 integration capability to ingest data into a data lake.
Consider, however, that you wanted to populate your data lake, but the applications that create your data used traditional mechanisms such as SMB or NFS file shares and protocols such as SFTP, FTPS, and FTP for data access. As many organizations still heavily use these mechanisms and protocols in their existing architectures, how could they seamlessly ingest that data into your data lake?
• Consider use cases such as bulk data transfers, end of day batch operations, or automation workflows to enable timely processing in the cloud, where your source data is stored on a file share. In these cases, you could utilize AWS DataSync to transfer your data over a network to your Amazon S3 bucket. By either using its scheduling function, configuring it manually, or by using the DataSync API in your automation workflow, DataSync is perfect for these use cases.
• If your files are generated asynchronously at different times of the day, consider using AWS Storage Gateway. You could present an SMB or NFS file share from a File Gateway back to your existing applications, which can only read or write to file shares, to enable them to upload data to your Amazon S3 bucket.
• If your clients or devices use SFTP, FTPS, or FTP for data access, then you could deploy a fully managed SFTP, FTPS, or FTP file transfer endpoint using the AWS Transfer Family of services. This could enable your existing SFTP, FTPS, and FTP clients to use the AWS Transfer Family endpoints as an interface to upload data into and access data from your Amazon S3 bucket. You can do so without needing to change how they integrate with their architecture. Think of all the different types of network devices and integration applications that use SFTP.
• Consider scenarios where you have a periodic or ad hoc bulk data transfer requirement into your Amazon S3 bucket, yet you have limited network connectivity or your data is not needed immediately. In these cases, you could order an AWS Snowcone or AWS Snowball Edge device. All you would have to do is copy your local data to whichever device and have it sent to AWS for offline data ingestion. Think of the repeated periodic bulk data transfers such as monthly data uploads for your applications waiting to process that data in cloud.
If you want to get hands-on with the services mentioned, check out this hands-on lab. This workshop takes you through deploying, configuring, and using File Gateway, AWS DataSync, and AWS Transfer for SFTP to ingest data to Amazon S3.
Demo: The following is a quick demo video showing these AWS services in action. This particular demo is for a scenario where you may have data stored on various systems using different protocols, and you are seeking to aggregate your data into your Amazon S3 data lake bucket.
Scenario 2: Ingesting file data into AWS file services
Consider a scenario where you have application data sitting on NFS or SMB file shares that you want to ingest into AWS Storage services. In this scenario, you want a simple approach to transfer that data without having to write any scripts or code.
• You could use AWS DataSync to accelerate the transfer of SMB or NFS file share data to a fully managed Amazon FSx for Windows File Server or Amazon EFS. In such a transfer, you would be enabled to preserve your folder and file attributes. Think of a scenario where you could be using AWS DataSync to migrate file share data to your new target file share or creating a copy of your data. This also applies if you are simply ingesting data into one these fully managed services for upstream applications to consume.
• If you wanted your application’s file share data to be backed by Amazon S3, you could present a file share from File Gateway to your applications, and copy or migrate your data to that share to enable the application data migration to your S3 bucket. Using File Gateway can also provide your application with low latency access to hot data via the local cache, and use the same file share for visibility and access to that application data.
• If data transfer speed is a priority as part of migrating your local file data to an Amazon S3 backed File Gateway file share, you could also transfer your file share data using AWS DataSync to your Amazon S3 bucket. Then, share that same data from your Amazon S3 bucket back to your application using file shares from File Gateway.
• When you can’t transfer data over a network to AWS, you could use the AWS Snow Family of devices to ingest file data into your Amazon S3 bucket. Then, you could share the data in that same Amazon S3 bucket back to your application using file shares from File Gateway.
Check out this blog that takes you through how you can use AWS DataSync to seamlessly migrate file data to Amazon FSx for Windows File Server.
If you want to get hands-on with AWS DataSync and file migration to Amazon FSx for Windows File Server, then check out this workshop.
Scenario 3: Storing backups or archiving data
Lastly, consider a scenario where you have applications that don’t have native Amazon S3 support. Despite this, you want your data backed up or archived to Amazon S3 or one of its storage classes, so you can leverage highly durable, scalable, and cost-effective data storage. What are some simple methods that you can use?
• Using AWS DataSync, you can transfer your file share data over a network directly to any of the Amazon S3 storage classes, from S3 Standard to S3 Glacier Deep Archive. This means you can directly store your hot access data in S3 Standard or archive directly to S3 Glacier Deep Archive to meet your backup or cost-effective long term archive requirements. From a backup or archive perspective, you could also look to schedule AWS DataSync transfers to run periodically.
• You can create file shares from your File Gateway to act as a backup or archive target interface. This enables you or your applications to write to these shares as a means of sending your backup or archive data to Amazon S3. When your data is uploaded to Amazon S3, you can use S3 Lifecycle policies to tier out your aged data to cost-effective archive storage classes like S3 Glacier Deep Archive. Then simply use the Amazon S3 console or S3 API to restore your archived data from the S3 Glacier storage classes, for online access when you require it, while still having visibility to your data via the file share. You could follow the instructions in this blog to automate the restore of archived objects through File Gateway.
• You could deploy an AWS Transfer Family service endpoint and have your SFTP/FTPS/FTP clients, such as network devices, write their logs and other data you want to backup or archive directly to Amazon S3. In Amazon S3, your file transfer clients still have visibility to that data via SFTP, FTPS, or FTP. From a cost optimization point of view, you can also leverage S3 Lifecycle policies to tier out aged data to Amazon S3 Glacier storage classes.
• In situations where you have limited network connectivity, you could order an AWS Snow device to transfer your on-premises backup and archive data to your Amazon S3 bucket. At that point, you can apply S3 Lifecycle policies to tier out aged data. Think of your large monthly or yearly backups, or archive datasets that you may need to transfer to S3.
Demo: The following is a demo video showing the migration of 10,000 very small files into an Amazon S3 bucket, using a copy script and then using AWS DataSync. The demo also breaks down the differences between each method.
Conclusion
In this blog post, I explored a few common data ingestion scenarios and highlighted some AWS Storage services that can be utilized as simple, cost-effective, and repeatable data transfer and ingestion mechanisms. Whether you are building a data lake, migrating application data, or creating backup and archive copies of your data, you should be able to use some guidance in this post to help with your strategy. I also provided demo videos as further educational material to help you visualize the AWS services in action. To go along with those videos, I supplied links to hands-on workshops that enable you to try out these AWS services so you can build your own solutions faster.
Thanks for reading this blog post! If you have any comments or questions, please don’t hesitate to leave them in the comments section.
To learn more about the services mentioned, check out the following links: