AWS Storage Blog
Easily store your SQL Server backups in Amazon S3 using File Gateway
Last year, we published a blog showing you how to set up AWS Storage Gateway to store SQL Server backups in Amazon S3, using cloud-backed Server Message Block (SMB) shares on File Gateway. Customers with growing on-premises backup costs and increasing operational overhead have used this solution to store their SQL Server backups durably and reliably in AWS, simplifying their backup operations while saving money and reducing their on-premises storage infrastructure.
File Gateway provides SMB and Network File System (NFS) access to data stored in your S3 buckets, using local caching to provide low-latency access to your data. Since our last blog post, AWS has launched a number of features for Storage Gateway that provide added resiliency, performance, and functionality. These features include high availability for VMware deployments, audit logging for SMB shares, increased performance, integrated CloudWatch alarms, and support for S3 Intelligent-Tiering.
In this post, we are going to build upon our previous blog and discuss best practices around File Gateway configuration, monitoring, and performance. We will show results of SQL Server backup tests that we ran in various File Gateway configurations. We’ll also show you how you can extrapolate from these results to plan for your own SQL Server environments. After reading this blog, you will be better equipped to design a scalable, durable solution for your SQL Server backup workloads.
How File Gateway handles writes
Before we discuss best practices, it’s good to understand how File Gateway handles writes from clients. When you deploy File Gateway, you specify how much disk space you want to allocate for local cache. This local cache acts as a buffer for writes and provides low latency access to data that was recently written to or read from Amazon S3. When a client writes data to a file via File Gateway, that data is first written to the local cache disk on the gateway itself. Once the data has been safely persisted to the local cache, only then does the File Gateway acknowledge the write back to the client. From there, File Gateway transfers the data to the S3 bucket asynchronously in the background, optimizing data transfer using multipart parallel uploads, and encrypting data in transit using HTTPS.
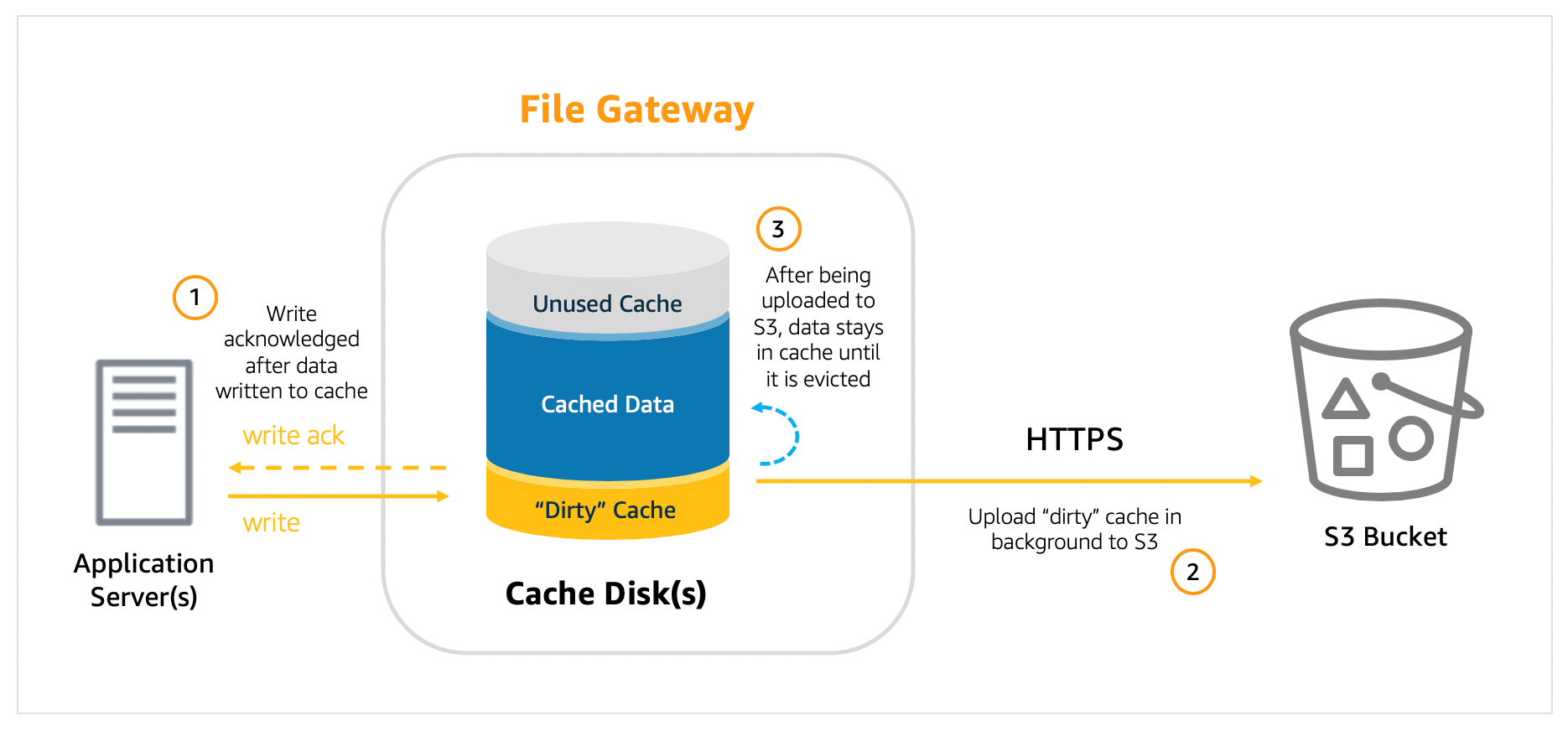
What does this mean for your backup solution?
First, it’s important to recognize that data written to File Gateway is not committed to Amazon S3 immediately, rather it takes time to upload data from the cache into S3. The time required for the upload can vary and depends upon both your network speed and your cache disk configuration. We show you which Amazon CloudWatch metrics you can monitor to see how long uploads take.
Second, you want to size your cache appropriately. More discussion regarding cache sizing is to follow, but a good rule of thumb is to allocate enough cache for your active dataset, which in this case would be the amount of data being backed up within your backup window. We also talk about how you can use CloudWatch metrics to monitor cache usage and determine if or when more cache must be allocated.
Third, if you have a large number of SQL Server databases to back up, you may need to deploy more than one File Gateway to provide enough local cache and performance to meet your backup timeframes. We talk more about sizing the number of File Gateways in the section on performance.
Setup and configuration
Our customers use File Gateway to back up their SQL Server databases running both on-premises and in AWS. If your SQL Servers are running on-premises, you can deploy File Gateway as a virtual or physical machine in your on-premises environment. If your SQL Servers are running in AWS on Amazon EC2, you can deploy File Gateway as an Amazon EC2 instance. Regardless of which environment you deploy into, make sure you follow our guidance on system requirements when setting up your File Gateway. Avoid using File Gateway deployed in EC2 with on-premises systems, or vice versa, as the increased network latency severely degrades the performance of your backup workload.
Considerations when deploying on Amazon EC2
For SQL Server backup workloads running in EC2, we recommend using either an m5.2xlarge or r5.2xlarge instance type. As shown in the performance section of this post, these provide a good balance of I/O performance vs. cost. When you create your gateway, the EC2 instance running the File Gateway should be deployed in the same Availability Zone as your SQL Server EC2 instances to avoid cross-Availability Zone network charges.
Some of our customers use EC2 instance types such as i3en for File Gateway because they provide fast local NVMe storage for cache. However, be aware that if the instance is stopped or terminated, then all data on the local instance storage is lost because every block of storage in the instance store is reset before it is made available to a new instance. If you choose to use instance storage for your gateway cache, you must consider whether your backup workflow can tolerate such an event.
If you require higher levels of availability on your File Gateway, consider deploying in a VMware vSphere cluster, either on-premises or in VMware Cloud on AWS. Doing so enables you to take advantage of File Gateway integration with vSphere HA capabilities. With vSphere HA, File Gateway automatically recovers from most service interruptions in under 60 seconds with no data loss. This protects your storage workloads against hardware, hypervisor, network failures, or software errors such as connection timeouts and file share or volume unavailability.
Sizing the cache
Once you’ve decided how to deploy your File Gateway, you must then consider how much cache disk to allocate. For SQL Server backup workloads, we recommend deploying enough cache to handle the volume of backups you are generating during your backup window. A small cache may result in poor performance, failures during write operations if there is no free cache space to store data locally while pending upload to Amazon S3, or partial file uploads that would be stored as S3 objects. When you write more data than the cache can hold at any given time, the gateway writes partial file uploads to Amazon S3 as a way to free up cache space. In this case, if versioning is configured on your S3 bucket you end up with partial file uploads stored as object versions.
You can always add more cache disk to your gateway (up to the current quotas on File Gateway). However, once you have added cache capacity, it can’t be removed. With this in mind, we recommend starting with the smallest cache capacity that meets your application needs, and then growing the cache as required.
Configuring Amazon S3
File Gateway stores all data in Amazon S3, so configuring your S3 bucket is an important step. One important consideration is bucket versioning. You may enable versioning to protect against accidental overwrites of data in your bucket, or versioning may be enabled as part of using S3 Object Lock or bucket replication. If versioning is enabled on your S3 bucket, File Gateway may create multiple versions of the same object in a short period of time. This occurs for a variety of reasons but it occurs primarily because of the mutable nature of working with files vs. the immutable nature of S3 objects. With versioning enabled, you want to monitor the number of versions being created for each object and consider creating an expiration policy to delete older versions of an object after a certain period of time.
Also consider which Amazon S3 storage class to use based upon your application access patterns. File Gateway supports the following storage classes: S3 Standard, S3 Standard-Infrequent Access (S3 Standard-IA), S3 One Zone-Infrequent Access, and S3 Intelligent-Tiering. The storage class you use depends upon how often the data will be accessed. If you access data frequently, then choose S3 Standard. If you access data infrequently, then use one of the Infrequent Access storage classes, keeping in mind the additional access charges associated with these classes. If you don’t know your access patterns, then S3 Intelligent-Tiering is the ideal choice. S3 Intelligent-Tiering automatically selects the right access tier for your data, based upon access over time without performance impact or operational overhead. For SQL Server backup workloads, you will likely access your backup files infrequently, so S3 Standard-IA or S3 Intelligent-Tiering may be a good choice.
Monitoring
File Gateway provides a number of ways to monitor your systems. You can use CloudWatch Logs to get information about the health of your gateway and related resources, and you can use CloudWatch Metrics and CloudWatch Alarms to monitor the performance and state of your gateway. Both CloudWatch Metrics and Alarms can be monitored directly from the Storage Gateway console. There are metrics both for the gateway, as well as for individual file shares. Let’s review some of the key metrics that File Gateway provides.
CachePercentDirty: this metric is available for both the gateway and file shares. It defines what percentage of the cache is being used to hold “dirty” data, which is data that has not been uploaded to Amazon S3. If this metric reaches 100%, then the gateway will not accept any new data and clients receive an I/O error until the dirty data gets uploaded and cache becomes available. It’s a good idea to set a CloudWatch alarm at 70%, configured to trigger after three data points to prevent false alarms. If the alarm gets triggered regularly, that may be a good indication that the cache on the gateway must be increased.
WriteBytes: this metric indicates how much data is being written by the on-premises application via the NFS or SMB protocol. You can use this to monitor the performance of your SQL Server backup jobs to make sure you are hitting your desired RPO/RTO targets.
CloudBytesUploaded: this metric shows how much data is being uploaded to Amazon S3 from the cache. You can use this metric with WriteBytes to compare how fast data is being ingested by your applications vs. how fast the data is being uploaded to the cloud. If data is being written faster than it is being uploaded, then you may exhaust available cache, leading to I/O errors. To address this, you may need to increase available cache or increase network bandwidth available to the gateway.
IoWaitPercent: this metric reports the percent of time the gateway is waiting on a response from the local disk. We recommend setting an alarm at 10%, triggered after four data points. If this metric regularly exceeds 10%, then your gateway may be bottlenecked by the speed of the local cache disk. We recommend local solid state drive (SSD) disks for your cache, preferably NVM Express (NVMe). If such disks aren’t available, try using multiple cache disks from separate physical disks for a performance improvement.
In addition to CloudWatch Metrics, File Gateway also supports audit logging for SMB shares. With audit logs, you can monitor user activities and take action if inappropriate activity patterns are identified. File Gateway audit logs provide a number of attributes that can be monitored, giving IT administrators and compliance managers information they need about user access to files and folders. For your SQL Server backup workloads, you can use audit logging to meet compliance needs, monitor access to backup files, and troubleshoot any access errors that may occur.
Sometimes, customers lifecycle older backups to Amazon S3 Glacier or S3 Glacier Deep Archive to reduce storage costs while meeting long-time retention requirements for compliance. If File Gateway attempts to read a file that has been moved to Amazon S3 Glacier or S3 Glacier Deep Archive, then it responds with an I/O error. However, you can use CloudWatch Events to automatically retrieve archived backup files so they can be restored to your database servers.
Performance
We ran some basic backup tests to give you an idea of what performance looks like in various File Gateway configurations, both for on-premises and in-cloud backup scenarios. For all of our tests, we used SQL Server 2017 and performed a full, uncompressed backup of one or more 20-GiB databases to a single SMB share on a File Gateway. In all cases, the backup time was averaged over five separate runs.
We used three types of gateway cache configurations: EC2 with instance storage (i3en.2xlarge), EC2 with Amazon EBS storage (c5.2xlarge, m5.2xlarge, r5.2xlarge), and on-premises VMware with SSD storage. For the EC2 with EBS configuration, we used three 1 TiB gp2 volumes per instance for the cache storage, using multiple volumes for increased throughput.
Our first test compared the time to back up a single 20-GiB database to our various File Gateway configurations.

From the chart, you can see that the i3en.2xlarge performed the best (meaning, it had the lowest backup time). This is expected given the local NVME drives that are attached directly to the instance. However, both the m5.2xlarge and r5.2xlarge also performed well with gp2 EBS volumes.
We then tested running multiple backup jobs in parallel, scaling from one to three jobs. We focused on the m5 and r5 instance types given their close performance in the previous test. The time reported was the time to back up all databases together.
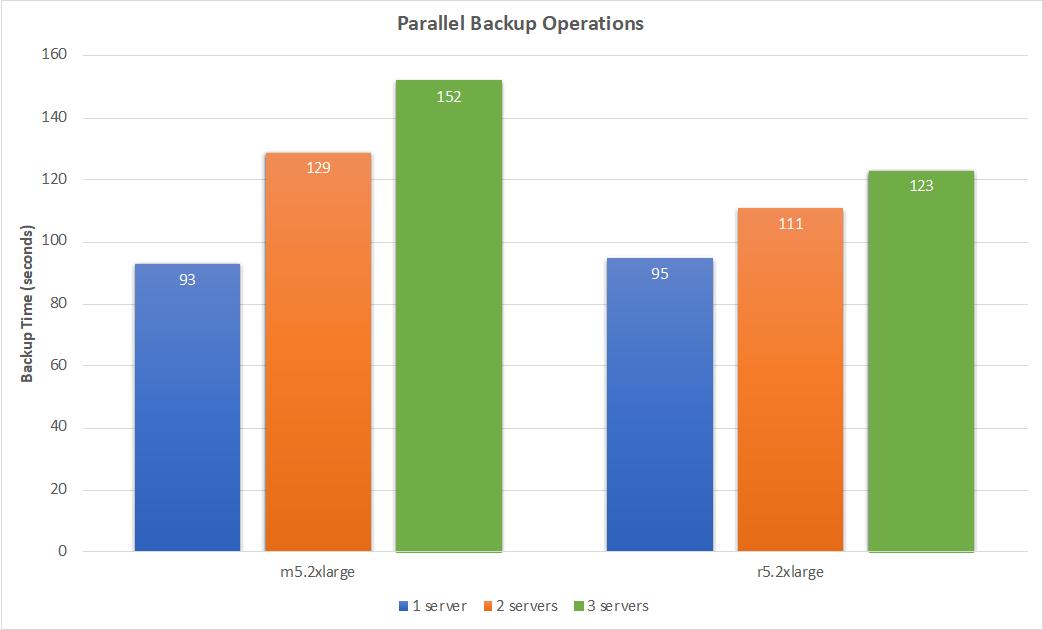
From the chart, you can see that the r5.2xlarge instance provides generally better performance as the number of backup jobs scale up. For the three server results on the r5 instance type, it took 123 seconds to back up 60 GiB, which is a throughput of 499 MB/s. Using this result, we can extrapolate to 10 servers, each with one 20-GiB database, and expect a full back of all servers to take about 7 minutes.
Your results may vary and we recommend you run tests in your own environment with database sizes that are typical of your workloads.
Backing up large databases
If you must back up large, multi-TiB SQL Server databases, remember that the maximum size of an Amazon S3 object is 5 TiB. Because File Gateway writes all files directly to S3, this means that a database backup file cannot exceed 5 TiB in size. One way to address this is to enable compression on your backups. An additional option is to split your backup file into multiple sub-files. As shown in the preceding multi-server performance graph, File Gateway scales throughput as more files are written in parallel, so we recommend writing the sub-files to the same gateway. To maximize performance and avoid some of the issues mentioned earlier, make sure to size the cache on your File Gateway accordingly so all backup files can fit.
Deploying multiple File Gateways
Depending on the number of SQL Servers in your environment, the size of your SQL databases, and your backup windows, you may need to deploy multiple File Gateways. The number of gateways you need is a factor of how many databases you can back up within your window. You can start with the preceding performance numbers and then adapt according to your needs, using the metrics to monitor gateway performance and cache utilization.
You can configure multiple gateways to use the same S3 bucket so long as each SQL database backup is going to a unique file.
Conclusion
In this blog post, we’ve highlighted some best practices when using File Gateway for SQL Server database backups, running either on-premises or in AWS. We detailed how File Gateway handles writes, by writing data to the local cache and asynchronously uploading to Amazon S3. We also looked at File Gateway setup and configuration, how to monitor your gateway, and some performance profiles to help you in sizing the number of gateways required for your environment.
By using File Gateway for your SQL Server backups, you can simplify your backup operations and reduce your storage costs by moving your backup files to S3 and taking advantage of the durability and reliability that Amazon S3 provides.
To learn more about File Gateway, check out the following links:
Thank you for reading and feel free to leave any comments in the comments section.