AWS Storage Blog
Maximizing price performance for big data workloads using Amazon EBS
Since the emergence of big data over a decade ago, Hadoop – an open-source framework that is used to efficiently store and process large datasets – has been crucial in storing, analyzing, and reducing that data to provide value for enterprises. Hadoop lets you store structured, partially structured, or unstructured data of any kind across clusters of storage in a distributed fashion using Hadoop Distributed File System (HDFS), as well as parallel processing of the data stores in HDFS using MapReduce. For use cases where you are hosting a Hadoop cluster on AWS, like running Amazon EMR or an Apache HBase cluster, processing intermediate data on block storage is required for optimal performance while balancing costs.
In this post, we provide an overview of our block storage service at AWS – Amazon Elastic Block Store (Amazon EBS), and recommend the EBS st1 volume type that is best suited for big data workloads. Then, we discuss the advantages of st1 volumes and the optimal st1 configuration that maximizes price and performance for HDFS. We set up a test environment that compares three clusters with each having a different st1 volume configuration. By leveraging Amazon CloudWatch metrics, we can monitor the performance of st1 volumes attached to these three clusters and then conclude which cluster with its respective volume configuration delivers the optimal performance. From these observations, you can optimize st1 volumes by using a validated configuration to balance cost performance for big data workloads.
Amazon Elastic Block Store
Amazon Elastic Block Store (Amazon EBS) is an easy-to-use, scalable, and high-performance block-storage service designed for Amazon Elastic Compute Cloud (Amazon EC2). Amazon EBS provides multiple volume types that are supported by either solid state drives (SSD) or hard disk drives (HDD). These volume types differ in performance characteristics and price, letting you tailor your storage performance and cost to the needs of your applications. The SSD-based volumes (io2 Block Express, io2, io1, gp3, and gp2) are optimized for transactional workloads involving frequent read and write operations with small input/output (I/O) size, where the dominant performance attribute is I/O operations per second (IOPS). The HDD-based volumes (st1 and sc1) are optimized for large streaming workloads where the dominant performance attribute is throughput. All EBS volumes work well as a storage for file systems, databases, or any applications that require access to raw, unformatted, block-level storage, and support dynamic configuration changes.
As customers continuously look to optimize their cloud spend, it is also important to identify not only the correct Amazon EBS storage volume type, but also the optimal volume configuration to meet the performance needs of workloads while reducing costs. Amazon EBS Throughput Optimized HDD (st1) volume type provides a fraction of the cost of SSD-based volume types, and it can burst up to 250 MiB/s per TiB with a maximum of 500 MiB/s per volume and a baseline throughput performance of 40 MiB/s per TiB. Due to its performance attributes, st1 is a good fit for large, sequential workloads such as Amazon EMR, ETL (extract, transform, load), data warehouses, and log processing.
HDFS and Amazon EBS st1 volumes
HDFS consists of NameNodes and DataNodes. Because DataNodes run on hardware that utilize raw disks, the chance of any of the nodes failing is high. HDFS can replicate data across several nodes depending on the replication factor. HDFS has a default replication factor of 3, i.e., the data is replicated three times across the DataNodes.
In HDFS, any file is chunked into a default value size of 128MB of data blocks and the I/O is sequential. Then, these data blocks are stored across the DataNodes in a distributed manner and replicated across the nodes. Due to this nature of large block sizes and sequential I/O, st1 volumes are a good fit because they provide high sustained throughput for sequential I/O at a lower cost than other EBS volume types.
We used TestDFSIO benchmark to simulate the read and write test. In the following, you can find the test results across three cluster sizes. We used an R5.xlarge (4vCPUs and 32 GiB Memory) as the EC2 instance type, with a cluster configuration of 1 NameNode and 5 DataNodes. In the first two columns in the following table, you can see that each node has a different configuration of st1 volumes with total cluster size of 10TiB. The test configuration includes 400 files of 4GB each.
| St1 volumes* attached to each DataNode | Size of storage of entire cluster | Test execution time for reads (seconds) | Test execution time for writes (seconds) | Cluster read throughput
(MiB/s) |
Cluster write throughput
(MiB/s) |
Cost/month |
|---|---|---|---|---|---|---|
|
4 Volumes of
|
4*512MiB*5
= 10 TiB |
1452 | 1794 | 1128.37 | 913.26 | $90 |
|
2 Volumes of
|
2*1 TiB * 5
|
1384 |
1673 |
1183.81 |
979.31 |
$90 |
| 1 Volume of
2TiB each |
1*2 TiB * 5
= 10TiB |
1249 | 1503 | 1311.76 | 1090.08 |
$90 |
*A 512 GiB st1 volume provides a baseline throughput of 20 MiB/s and can burst to 125MiB/s. A 1 Tib st1 volume provides a baseline throughput of 40 MiB/s and can burst to 250 MiB/s. A 2 TiB st1 volume can support a baseline of 80 MiB/s of throughput and can burst to 500 MiB/s

Note that as the size of the individual EBS st1 volume increases, it can start supporting longer sustained throughput performance. However, beyond 2 TiB, since the burst throughput is now 500MiB/s, the advantages of utilizing burst performance will plateau. However, it can still sustain at least a consistent baseline throughput of 40 MiB/s per TiB up until 12.5 TiB. As the size of the volume reaches 12.5 TiB, the baseline throughput performance is equal to the burst throughput of 500 MiB/s for this volume. Therefore, the performance beyond this volume size remains the same.
Reviewing performance using Amazon CloudWatch metrics
AWS provides a monitoring tool in the form of Amazon CloudWatch metrics, which let you monitor Amazon EBS performance metrics and contextualize the application behavior. You can find these metrics by first logging into the AWS Management Console, then searching for CloudWatch in the search bar, and finally navigating to All metrics > EBS.
To calculate the Read and Write throughput of an EBS volume, we are using custom CloudWatch maths as follows:
- Read Throughput = SUM(VolumeReadBytes)/ Period (in seconds)
- Write Throughput = SUM(VolumeWriteBytes)/ Period (in seconds)
In the following section, we compare the throughput performance of st1 volumes across three configurations to determine which configuration provides the best price performance.
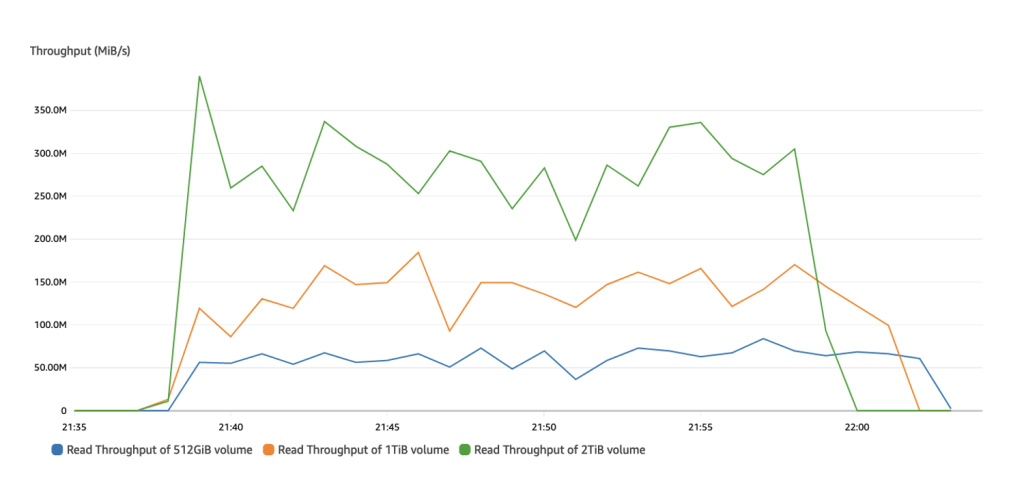
Read throughput of st1 volumes across three configurations
By looking at the read throughput, the 512 GiB volume can achieve a peak of ~75 MiB/s, the 1-TiB volume can achieve a peak ~180 MiB/s, and the 2-TiB volume can achieve a peak of 375 MiB/s of read throughput.
Write throughput of st1 volumes across the three configurations
Next, we look at the write throughput. The 512-GiB volume can achieve a peak of ~125 MiB/s, the 1-TiB volume can achieve a peak of ~250 MiB/s, and the 2-TiB volume can achieve a peak of 500MiB/s of write throughput.

As a result of our observations from the above CloudWatch graphs on read/write throughput performance, we can conclude that larger st1 volumes can drive higher performance. This is because st1 volume’s performance is directly proportional to the configured storage at 40 MiB/s per TiB. This is also in line with the data we observe from the table mentioned above, where cluster throughput increases as the size of individual st1 volumes in that cluster increases.
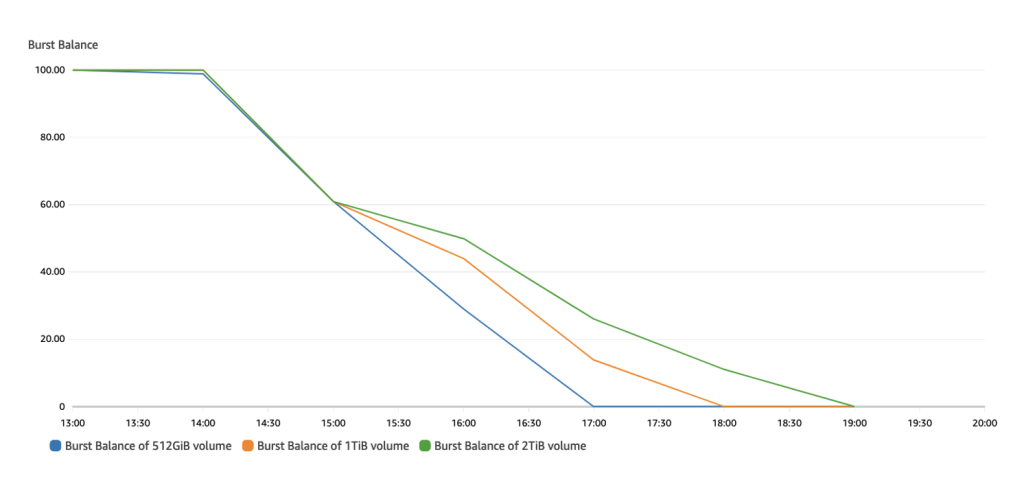
Burst balance of st1 volumes across the three configurations
Burst balance tells us about the remaining throughput credits of st1 volumes in the burst bucket that allows the volumes to burst above their baseline performance. This indicates how quickly st1 volumes exhaust their burst throughput credits over time. From the following graph, we can see that the 512-GiB volume was the first to drop to 0 followed by the 1-TiB volume and then the 2-TiB volume. This shows that larger st1 volumes can sustain higher throughput performance compared to smaller st1 volumes.
Conclusion
In this post, we set up three Amazon EMR clusters with each having a different st1 volume configuration in a test environment and compare their performance results of running HDFS. From the CloudWatch metrics, we can conclude that by using larger st1 volumes on Amazon EMR cluster running HDFS, you can drive a higher throughput performance at the same cost of multiple smaller st1 volumes, thereby optimizing price performance. Amazon EBS gives customers the flexibility to select the storage solution that meets and scales with their HDFS workload requirements. St1 is available for all AWS Regions and you can access the AWS Management Console to launch your first st1 volume or convert existing volumes by following this guide.
Thank you for reading this post. If you have any comments or questions, then don’t hesitate to leave them in the comments section.