Amazon Web Services ブログ
Category: Analytics

Amazon OpenSearch Service のセマンティック検索で注文履歴検索を改善する
Amazon の注文履歴検索チームが、Amazon OpenSearch Service と Amazon SageMaker を使ってレキシカル検索にセマンティック検索機能を追加し、顧客体験を改善した方法を紹介します。セルベースアーキテクチャによるスケーラビリティ向上、エンベディングモデルの評価と選定、ハイブリッド検索の実装について解説します。

アプリケーションを変更せずに Amazon SageMaker Catalog でデータメッシュパターンを実装する
Amazon SageMaker Catalog を使用してデータメッシュパターンを実装する方法を説明します。既存のアプリケーションやデータリポジトリを変更せずに、Amazon SageMaker Unified Studio でデータをオンボード、公開、サブスクライブする手順を紹介します。

Integral Ad Science における Amazon OpenSearch Service を使った日次 1 億件超のドキュメント処理の紹介
Integral Ad Science (IAS) が Amazon OpenSearch Service を活用し、日次 1 億件以上のドキュメントを処理するスケーラブルな SaaS 型 ML プラットフォームを構築した事例を紹介します。ベクトル検索の最適化により、複雑な検索オペレーションで 40〜55% のパフォーマンス向上を達成しました。

Amazon DynamoDB データに対する検索を Amazon OpenSearch Service とのゼロ ETL 統合を使用して実装する
この記事では、Amazon DynamoDB データに対する検索を Amazon OpenSearch Ser […]

AWS Weekly Roundup: Amazon EC2 M8azn インスタンス、Amazon Bedrock の新しいオープンウェイトモデルなど (2026 年 2 月 16 日)
2021 年に AWS に入社して以来、私は Amazon Elastic Compute Cloud (Am […]

BMW Group が AWS 上のエージェンティック検索でペタバイト規模のデータからインサイトを引き出す
BMW Group が AWS 上でエージェント検索ソリューションを構築し、ペタバイト規模のデータからインサイトを引き出す取り組みを紹介します。同社の Cloud Data Hub は 20 PB のデータを保存し、1 日平均 110 TB を取り込んでいますが、従来は専門知識がないユーザーにとってデータ分析が困難でした。AWS Professional Services と協力し、Amazon S3 Vectors、Amazon Bedrock、Strands Agents を組み合わせたソリューションを開発。ハイブリッド検索、網羅的検索、SQL クエリの 3 つのアプローチにより、技術スキルに関係なく自然言語でデータにアクセス可能になりました。サーバーレスアーキテクチャによりコスト効率も実現しています 。

Amazon Managed Service for Apache Flink でよく使われるストリーミングデータエンリッチメントパターン
本記事では、Amazon Managed Service for Apache Flink でよく使われるストリーミングデータエンリッチメントパターンを解説します。参照データの事前ロード、レコード単位の非同期ルックアップ、外部キャッシュの活用、別ストリームとの結合、Table API の利用など、各パターンの利点と欠点を比較し、ユースケースに応じた最適な選択を支援します。

OpenSearch のクエリパターンに合わせたインデックス戦略の選択
Amazon OpenSearch Service でオートコンプリート機能を効率的に実装する方法を紹介します。Edge n-gram トークナイザーを使ったカスタムインデックスアナライザーにより、ワイルドカードを使わずにプレフィックスクエリをマッチさせ、検索パフォーマンスを向上させる手法を解説します。
【寄稿】SIEMからデータ基盤へ – 三井物産デジタルアセットマネジメントのAWS Security Lake活用事例
こんにちは。ソリューションアーキテクトの松本 敢大です。三井物産デジタル・アセットマネジメント株式会社(以下、 […]
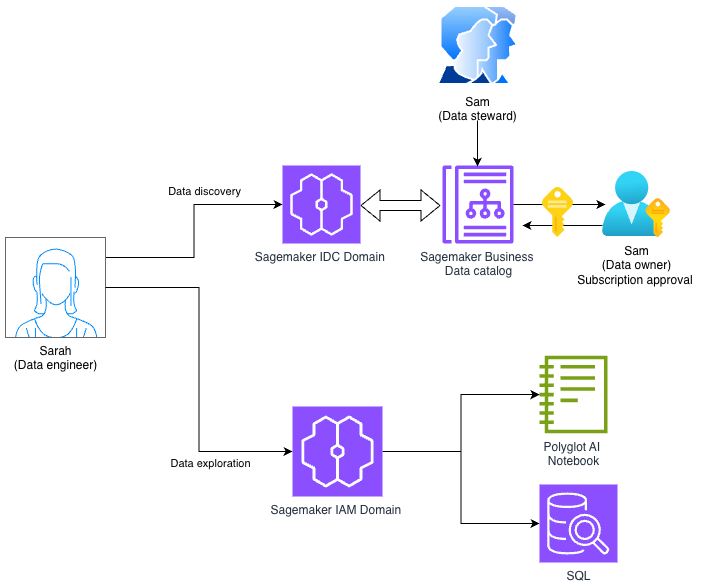
Amazon SageMaker Unified Studio の Identity Center (IDC) ベースドメインと IAM ベースドメインを併用する
Amazon SageMaker Unified Studio で、IDC ベースドメインと IAM ベースドメインの 2 種類のドメイン構成が利用可能になりました。本記事では、IAM ロールの再利用と属性ベースのアクセス制御 (ABAC) を使って、IDC ベースドメインの既存のガバナンスフレームワークを維持しながら、IAM ベースドメインの最新開発ツールを活用する方法を紹介します。