Category: Amazon EC2
차세대 (R4) 메모리 최적화 EC2 인스턴스
인-메모리 기반 서비스는 큰 이슈입니다. 지속적으로 대량화 되는 작업 부하와 CPU 성능 증가와 아울러 메모리에 최적화 기법은 고품질 비즈니스 인텔리전스, 데이터 분석 기술 활용의 전제 조건이 되었습니다. 인 메모리 기반 데이터 마이닝 및 대기 시간에 민감한 기타 실시간 작업 부하를 처리 할 수 있습니다. 분산 캐싱 및 일괄 처리 작업 역시 많은 메모리에 빠르게 사용해야 합니다.
이러한 요구 사항에 맞추어 오늘 차세대 메모리 최적화 EC2 인스턴스를 출시합니다. 기존 보다 큰 L3 캐시, 높은 메모리 속도 및 클라우드 작업 부하에 최적화 된 마이크로 아키텍처를 지원하며, 기존의 R3 인스턴스를 성능을 개선하였습니다. EC2 포트폴리오 내에서 GiB 당 최적의 가격을 갖는 것 외에도 EBS에 전용 처리량 12Gbps와 함께 배치 그룹 내에서 사용할 경우 최대 20Gbps의 ENA 네트워크 대역폭을 지원합니다.
R4 인스턴스의 사양은 아래와 같습니다.
- 고성능 Intel Xeon E5-2686 “Broadwell” 프로세서
- DDR4 메모리
- Hardware Virtualzation (HVM)만지원
아래는 인스턴스 사이즈별 정보입니다.
| 모델 | vCPUs | 메모리 (GiB) | 네트워크 대역폭 |
| r4.large | 2 | 15.25 | Up to 10 Gigabit
|
| r4.xlarge | 4 | 30.5 | Up to 10 Gigabit |
| r4.2xlarge | 8 | 61 | Up to 10 Gigabit |
| r4.4xlarge | 16 | 122 | Up to 10 Gigabit |
| r4.8xlarge | 32 | 244 | 10 Gigabit |
| r4.16xlarge | 64 | 488 | 20 Gigabit |
R4 인스턴스는 온디멘드와 예약 인스턴스 타입으로 US East (Northern Virginia), US East (Ohio), US West (Oregon), US West (Northern California), EU (Ireland), EU (Frankfurt), Asia Pacific (Sydney), China (Beijing), AWS GovCloud (US) 리전에 출시됩니다. 자세한 것은 EC2 요금표를 참고하시기 바랍니다.
Update. 2017년 1월 19일 Asia Pacific (Seoul) 리전에 출시하였습니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 New – Next Generation (R4) Memory-Optimized EC2 Instances의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
신규 T2.Xlarge 및 T2.2Xlarge 인스턴스 출시
많은 AWS 고객들이 비용 효율적이면서 필요시에만 컴퓨팅 용량을 이용할 수 있는 T2 인스턴스를 사용하고 있습니다. 컴퓨팅 용량이 일상적인 업무 즉, 일반적인 웹 서버, 개발 서버, 개발 통합 및 테스트 서버 그리고 작은 데이터베이스 서버 등에 활용하고 있습니다. T2 인스턴스 타입은 적정량의 기본 성능을 보장하고, 갑작스런 트래픽에 맞추어 자동으로 일정량의 컴퓨팅 용량을 추가 사용할 수 있습니다. (자세한 것은 저가 T2 인스턴스 출시 – 급격한 트래픽 처리 가능을 참고하세요.)
오늘 추가로 두 개의 신규 대용량 T2 인스턴스 타입을 소개합니다. – t2.xlarge는 16 GiB 메모리를 가지고 t2.2xlarge는 32 GiB 메모리를 제공합니다. 신규 인스턴스 타입을 통해 T2 용량 버스팅 모델을 그대로 따르면서 메모리를 더 필요로 하는 애플리케이션에 최적화할 수 있습니다. (t2.large 인스턴스를 2016년 6월, t2.nano인스턴스를 2015년 12월에 선보인 바 있습니다.)
아래는 T2 인스턴스 타입의 모든 스펙입니다. (가격은 최근 EC2 가격 할인을 반영하였습니다.)
| 인스턴스 타입 | vCPUs | 기본성능 | 플랫폼 | 메모리(GiB) | CPU크레딧/시간당 | 시간당 가격
(리눅스) |
| t2.nano | 1 | 5% | 32-bit or 64-bit | 0.5 | 3 | $0.0059 |
| t2.micro | 1 | 10% | 32-bit or 64-bit | 1 | 6 | $0.0120 |
| t2.small | 1 | 20% | 32-bit or 64-bit | 2 | 12 | $0.0230 |
| t2.medium | 2 | 40% | 32-bit or 64-bit | 4 | 24 | $0.0470 |
| t2.large | 2 | 60% | 64-bit | 8 | 36 | $0.0940 |
| t2.xlarge | 4 | 90% | 64-bit | 16 | 54 | $0.1880 |
| t2.2xlarge | 8 | 135% | 64-bit | 32 | 81 | $0.3760 |
기존 업무를 새로운 인스턴스 타입에 이전하기 위한 몇 가지 전략을 소개해 드립니다.
- t2.large 애플리케이션 중 좀 더 많은 메모리가 필요하다면, t2.xlarge나 t2.xlarge로 이전합니다.
- c4.2xlarge를 중간 정도 사용하는 애플리케이션이라면 t2.xlarge로 이동하면 비슷한 컴퓨팅 용량에 획기적인 가격 인하 효과를 볼 수 있습니다.
- m4.xlarge를 중간 정도 사용하는 t2.xlarge로 이전 하면 비슷한 컴퓨팅 용량에 약간의 가격 할인 효과를 볼 수 있습니다.
새로운 인스턴스 타입은 오늘 부터 모든 온디멘드 및 예약 인스턴스에 대해 전체 AWS 리전에서 사용 가능합니다.
— Jeff
이 글은 AWS re:Invent 2016 신규 출시 소식으로 New T2.Xlarge and T2.2Xlarge Instances<의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
AWS로 딥 러닝을 위한 프레임워크 MxNet 활용하기
머신 러닝에 대한 관심이 폭발적으로 증가했습니다. 특히, 국내에서는 올해 알파고로 인해 딥러닝(Deep Learning)에 대한 관심이 크게 증가하였습니다. 인공 신경망을 이용한 딥 러닝 기법은 하드웨어 성능의 비약적인 개선과 신경망 알고리즘의 개선으로 인해 실제 활용 가능한 수준으로 빠르게 변화하였습니다.
이러한 관심으로 인해 분산 딥 러닝 프레임워크(distributed deep-learning framework)가 많이 개발되어 오픈소스 형식으로 공개되고 있는 상황입니다. 게임 서비스 영역에서도 차츰 딥 러닝을 활용한 서비스들이 지속적으로 나타나고 있습니다. 인공 지능 연구 및 서비스 개발자의 요구 사항, 지원 언어 및 하드웨어 따라 여러 종류의 딥 러닝 프레임워크가 개발되어 공개되었습니다. 대표적인 것이 MXNet, Caffe , Theano , TensorFlow™, Torch 등이 있습니다.
딥러닝 프레임워크 소개
DeepLearning 4J에서 비교한 딥러닝 프레임워크 비교 기사를 보면 아래와 같은 장단점을 나열할 수 있습니다. (본 자료는 AWS의 공식적인 자료가 아니며, DeepLearning 4J의 의견입니다.)
| 프레임워크 | 장점 | 단점 |
| Theano |
|
|
| Torch |
|
|
| TensorFlow |
|
|
| Caffe |
|
|
| MxNet |
|
|
아마존의 CTO인 Werner Vogels 박사께서는 최근 MXNet – Deep Learning Framework of Choice at AWS라는 글에서 확장 능력, 개발 속도, 이동성 등의 다양한 요인을 비추어 볼 때, MXNet이 가장 좋은 딥러닝 프레임웍이라고 판단하고, 이를 기반한 딥러닝 서비스 개발 지원 및 오픈 소스 지원에 대한 의지를 피력한 바 있습니다.

MxNet은 오픈소스로 여러 언어를 지원하고 모바일부터 서버까지 다양한 디바이스를 지원하는 딥 러닝 프레임워크 입니다. CPU와 GPU 연산을 지원하고, 심볼릭과 명령적(imperative) 프로그래밍의 혼합 방식 까지 지원하며 최적화된 엔진을 사용해서 성능이 뛰어납니다.
또한 실무적으로 많이 사용하는 Python, C++, R, Scala, Julia, Matlab, and JavaScript을 지원하는 등 산업계에서 응용하기에 매우 적합한 딥 러닝 프레임워크입니다.
아래 그림에서 보시다시피, Inception v3 (MXNet 및 P2 인스턴스 사용)를 통해 GPU 숫자를 증가시켰을 때, 다른 라이브러리 보다 빠른 처리량을 가짐과 동시에 GPU 숫자가 증가하는 확장 상황에서도 처리량의 효율이 85%에 달할 정도로 뛰어난 성능을 보여 주고 있습니다.
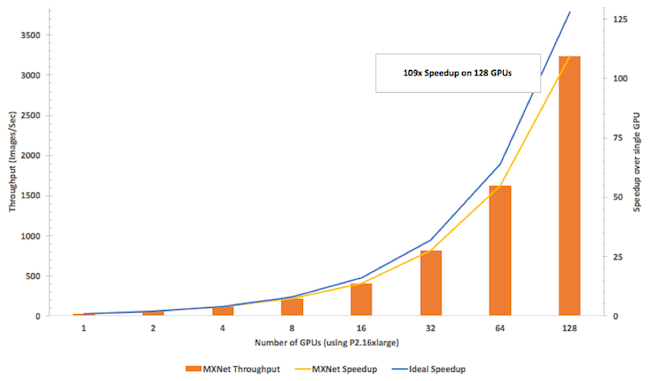
컴퓨팅 처리량 및 효율 뿐만 아니라 메모리 사용량도 중요합니다. MXNet은 1,000개의 신경망 레이어를 사용할 때 4GB 이하의 메모리를 사용하고, 이식성 면에서도 다양한 플랫폼을 지원합니다. 안드로이드나 iOS에서도 활용 가능하고, 심지어 자바스크립트 확장 기능으로 웹 브라우저에서도 실행 할 수 있습니다.
DeepLearning AMI를 통해 MXNet 실행하기
이 글에서는 Amazon EC2의 신규 GPU 기반 P2 인스턴스 및 G2 인스턴스를 통해 딥러닝 API를 기반으로 MXNet을 간단히 실행해 보겠습니다. (P2 및 G2 인스턴스는 시간당 가격이 다른 인스턴스에 비해 높으므로, 짧은 시간 테스트를 위해서는 스팟 인스턴스를 이용해 보는 것도 권장합니다.)

먼저 AWS 마켓 플레이스에서 제공하는 Amazon Deep Learning AMI을 기반으로 인스턴스를 실행합니다. 본 AMI에 설치된 딥 러닝 프레임워크는 Caffe, MxNet, TensorFlow, Theano, Torch 입니다. 우리는 여기서 MxNet을 사용해 보겠습니다. SSH로 접속해서 인스턴스의 src 디렉토리에 있습니다.

인스턴스의 src/mxnet/example 디렉토리를 보면 많은 예제들이 존재합니다. 이와 관련된 튜토리얼은 http://mxnet.io/tutorials/index.html 링크를 참조하면 됩니다.
우리가 실행을 해볼 것은 숫자 이미지를 트레이닝 해서 특정 이미지 내 숫자 데이터가 어떤 것인지 찾아내는 예제입니다. 간단한 Python 코드를 통해 해 볼 수 있습니다. (http://mxnet.io/tutorials/python/mnist.html.)
다만 여기서 플롯팅의 경우 현재 실행 중인 인스턴스에서 구동이 되지 않기 때문에 플롯(plot)을 이미지로 출력하는 부분은 제외하고 실행을 해야 합니다. 문서에는 단계별로 수행을 하게 되어 있습니다만 소스 부분을 고쳐서 한번에 실행하게 수정을 한 것이 다음 Python 소스 입니다.
import mxnet as mx
def to4d(img):
return img.reshape(img.shape[0], 1, 28, 28).astype(np.float32)/255
batch_size = 100
train_iter = mx.io.NDArrayIter(to4d(train_img), train_lbl, batch_size, shuffle=True)
val_iter = mx.io.NDArrayIter(to4d(val_img), val_lbl, batch_size)
# Create a place holder variable for the input data
data = mx.sym.Variable('data')
# Flatten the data from 4-D shape (batch_size, num_channel, width, height)
# into 2-D (batch_size, num_channel*width*height)
data = mx.sym.Flatten(data=data)
# The first fully-connected layer
fc1 = mx.sym.FullyConnected(data=data, name='fc1', num_hidden=128)
# Apply relu to the output of the first fully-connnected layer
act1 = mx.sym.Activation(data=fc1, name='relu1', act_type="relu")
# The second fully-connected layer and the according activation function
fc2 = mx.sym.FullyConnected(data=act1, name='fc2', num_hidden = 64)
act2 = mx.sym.Activation(data=fc2, name='relu2', act_type="relu")
# The thrid fully-connected layer, note that the hidden size should be 10, which is the number of unique digits
fc3 = mx.sym.FullyConnected(data=act2, name='fc3', num_hidden=10)
# The softmax and loss layer
mlp = mx.sym.SoftmaxOutput(data=fc3, name='softmax')
# We visualize the network structure with output size (the batch_size is ignored.)
shape = {"data" : (batch_size, 1, 28, 28)}
mx.viz.plot_network(symbol=mlp, shape=shape)
import logging
logging.getLogger().setLevel(logging.DEBUG)
model = mx.model.FeedForward(
symbol = mlp, # network structure
num_epoch = 10, # number of data passes for training
learning_rate = 0.1 # learning rate of SGD
)
model.fit(
X=train_iter, # training data
eval_data=val_iter, # validation data
batch_end_callback = mx.callback.Speedometer(batch_size, 200) # output progress for each 200 data batches
)
prob = model.predict(val_img[0:1].astype(np.float32)/255)[0]
print 'Classified as %d with probability %f' % (prob.argmax(), max(prob))위의 코드를 실행하면 다음과 같이 모델을 훈련하게 되고, 그 다음에 숫자 7 이미지를 판단해서 결과를 출력합니다.

MxNet 의 Github 레포지터리의 example을 보면 이 외에도 아주 다양한 샘플 코드가 존재합니다.
딥 러닝은 이제 많은 분야에서 빠르게 응용되고 있습니다. 게임 개발자 분들도 이러한 딥 러닝 기법을 활용한 다양한 게임 AI를 만드셔서 활용하시기 바랍니다. 만약 실제 서비스를 위해 클러스터를 구성해야 한다면, AWS CloudFormation를 통해 AWS 자원을 손쉽게 만들고 운영할 수 있는 방식을 통해 딥러닝 클러스터를 만들 수 있는 MXNet의 CF 템플릿을 소개합니다.
이 템플릿을 이용하여 Amazon Deep Learning AMI을 Amazon EC2의 신규 GPU P2 인스턴스에 구성하여, 자동 스케일링을 지원하는 분산 딥러닝 클러스터를 만들어 운영할 수 있게 됩니다. (자세한 것은 AWS를 통한 분산 딥러닝(Deep Learning) 구성하기를 참고하세요.)
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 박선용 솔루션즈 아키텍트께서 작성해주셨습니다.

Amazon EC2 가격 인하 – C4, M4, T2 인스턴스 타입
2016년 12월 1월 부터 Amazon EC2 가격 인하를 시작합니다. 연말 대목 서비스를 맞아서 여러분에게 조금이나마 도움이 되시길 바랍니다. 저희는 기술 투자를 통한 확장성 및 가용성 그리고 이를 통한 컴퓨팅 용량의 효율적 관리를 통해 절감된 비용을 여러분에게 되돌려 드리고 있습니다.
이번 가격 인하에는 C4, M4, and T2 인스턴스 타입에 대해 온디멘드, 예약 인스턴스 (표준 및 전환 가능), 전용 호스팅 가격을 적용 리전 및 플랫폼(Linux, RHEL, SUSE, Windows 등) 따라 최대 25%까지 제공됩니다.
예를 들어, 리눅스 플랫폼의 경우
- C4 – 5% 인하 / US East (Northern Virginia), EU (Ireland), 20% 인하 /Asia Pacific (Mumbai) 및 Asia Pacific (Sydney)
- M4 – 10% 인하 / US East (Northern Virginia), EU (Ireland), EU (Frankfurt), 25% 인하 / Asia Pacific (Singapore).
- T2 – 10%까지 인하 / US East (Northern Virginia), 25% 인하 / Asia Pacific (Singapore).
늘 그렇지만, 온디멘드 가격 인하에 대해서는 여러분이 추가로 하실 일은 없습니다. 만약 빌링 알람이나 새로운 예산 기능을 사용하신다면, 여러분의 가격 예상치를 하향 조정 하실 필요는 있습니다.
업데이트: 본 가격 인하는 각 리전 및 인스턴스 타입에 따라 다르게 적용되며, 자세한 것은 12월 1일 EC2 가격 페이지를 참고하시면 됩니다. (리눅스 및 윈도우 포함) 서울 및 도쿄 리전의 가격 인하율은 아래와 같습니다.
- 온디멘드 인스턴스: C4-5%, M4/T2- 20%
- 1년 예약 인스턴스: C4-5%, M4- 15% (도쿄리전은 20%), T2- 20%
- 3년 예약 인스턴스: C4-5%, M4/T2- 20%
이번은 2006년 AWS 서비스 시작 이후, 53번째 가격 인하입니다.
— Jeff
이 글은 EC2 Price Reduction (C4, M4, and T2 Instances)의 한국어 번역입니다.
AWS를 통한 분산 딥러닝(Deep Learning) 구성하기
기계 학습(Machine Learning) 분야는 명시적인 프로그래밍이 없더라도 컴퓨터를 통해 학습을 할 수 있도록 도와주는 전산 분야입니다. 알고리즘을 통해 스스로 배워서 데이터로 부터 예측을 할 수 있습니다.
최근에는 기계 학습의 분류로 딥러닝(Deep Learning)이라 불리는 방식으로 전통적인 기법보다 더 정확하고 성공적으로 음성 인식, 이미지 인식 및 비디오 분석 등의 분야에서 서비스를 제공할 수 있게 되었습니다. 하지만, 많은 컴퓨팅 용량이 필요하기 때문에 학습 모델의 비용에 크다는 단점이 있었습니다.
클라우드 컴퓨팅이 제공하는 가용성을 통해 이러한 작업을 더 빠르게 진행할 수 있습니다. 인공 지능 기반 뉴럴 네트워크 훈련에는 시간이 많이 소요되고 ResidualNet 같은 네트워크 방식으로 가장 최신의 GPU 하드웨어를 사용하더라도 몇 일에서 몇 주간이 필요합니다. 이 때문에 스케일-아웃(Scale-out) 확장은 필수적이라 하겠습니다.
학습 속도를 빠르게 하면 다음과 같은 장점이 있습니다.
- 더 빠르게 여러번 실험 및 연구를 할 수 있어서 컴퓨터 비전 또는 음성 인식 분야의 현재 상태를 개선 할 수 있게 됩니다.
- 인공 지능 애플리케이션의 시장이 원하는 시점에 AI 서비스를 빠르게 만들어서 배포하고 새롭게 개선할 수 있습니다.
- 새로운 데이터를 더 빠르게 흡수하고 학습 모델을 개선할 수 있습니다.
AWS CloudFormation를 통해 AWS 자원을 손쉽게 만들고 운영할 수 있는 방식을 통해 딥러닝 클러스터를 만들 수 있는 새로운 템플릿을 소개합니다. 이 템플릿을 이용하여 Amazon Deep Learning AMI (MXNet, TensorFlow, Caffe, Theano, Torch, CNTK 프레임웍 지원)을 Amazon EC2의 신규 GPU P2 인스턴스에 구성하여, 자동 스케일링을 지원하는 분산 딥러닝 클러스터를 만들어 운영할 수 있게 됩니다.
딥러닝용 EC2 클러스터 아키텍처 구성
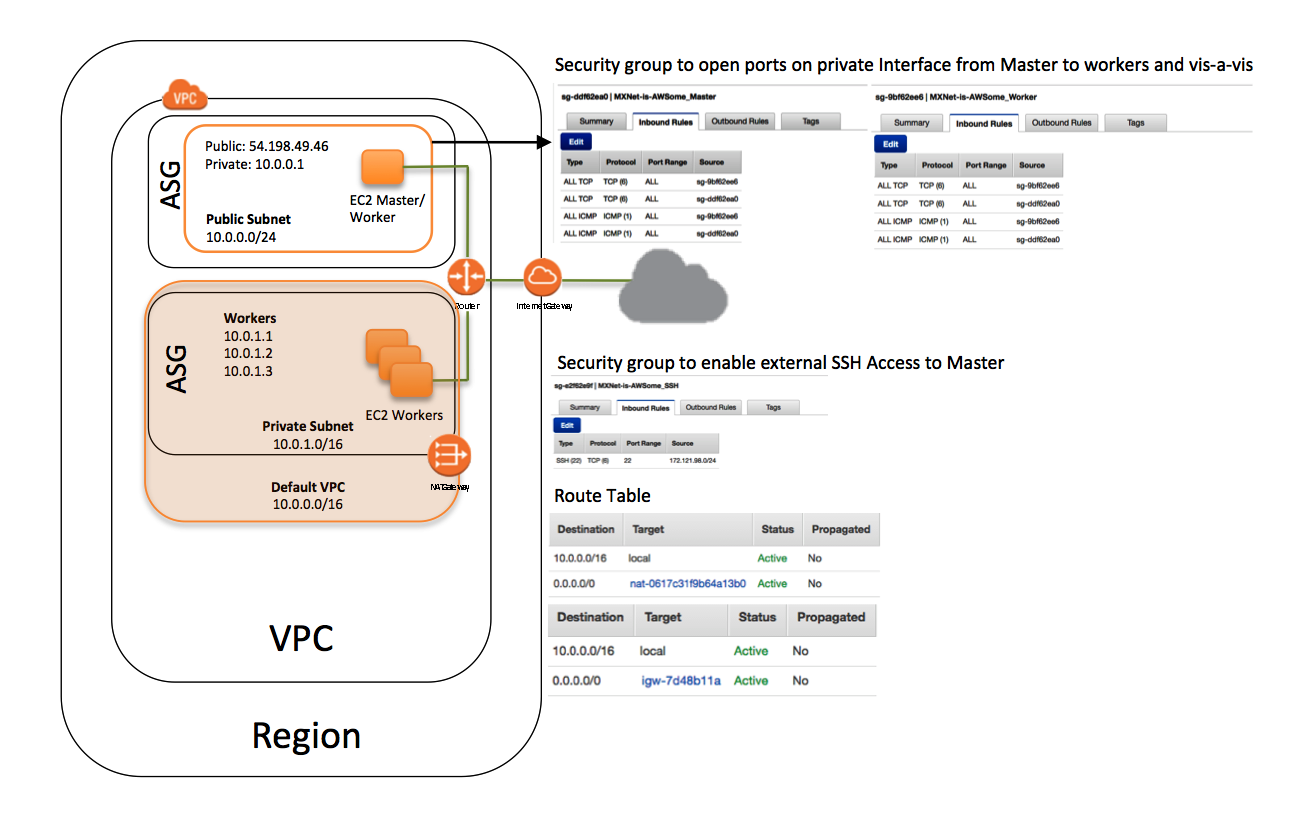
본 딥러닝용 CF 템플릿은 아래의 AWS 리소스를 생성하게 됩니다.
- 고객 계정에 VPC 설정
- 고객이 원하는 숫자의 인스턴스를 VPC 내에 자동 스케일링 그룹 에 사설망에 생성
- 마스터 인스턴스를 자동 인스턴스 그룹에 별도로 생성하여 SSH로 접속할 수 있게 생성
- 마스터 인스턴스에 SSH 접근이 가능하도록 보안 그룹 설정
- 두 개의 보안 그룹 포트 설정을 통해 마스터 인스턴스와 워커 인스턴스 사이의 통신 제공
- IAM 역할을 설정하여 자동 스케일링 그룹과 사설망 내 EC2 인스턴스 조회 기능 제공
- 외부에서 접근할 수 있도록 VPC 내에 NAT 게이트웨이 설정
실행 스크립트는 모든 호스트에 대해 SSH를 지원합니다. MXNet 같은 프레임웍을 사용하기 때문에 SSH 사용이 필수적이며, 이를 통해 분산 학습 동안 워커 인스턴스와 마스터 사이의 통신을 합니다. 스크립트를 실행하면 스택 내의 모든 호스트에 대한 사설 IP를 조회하고 이를 /etc/hosts에 추가한 후 , /opt/deeplearning/workers에 워커 인스턴스 목록을 작성합니다.
실행 스크립트는 아래와 같은 환경 변수를 가집니다.
$DEEPLEARNING_WORKERS_PATH:워커 목록을 가진 파일 경로$DEEPLEARNING_WORKERS_COUNT:총 워커 인스턴스 수$DEEPLEARNING_WORKER_GPU_COUNT:인스턴스 내 GPU 수
딥러닝용 EC2 클러스터 실전 운영
원하는 인스턴스 숫자를 사용하려면, 기술 지원 센터에 기본 제한 숫자 증가를 요청하시기 바랍니다.
- MXNet GitHub repo에서 딥러닝용 CF 템플릿을 다운로드 합니다.
- CloudFormation 콘솔을 열고, Create New Stack을 선택합니다.
- Choose File을 눌러 다운로드한 템플릿을 업로드 한 후, Next를 누릅니다
- For Stack name 원하는 이름을 입력합니다.
- GPU InstanceType을 선택합니다. 예) P2.16xlarge.
- KeyName에는 자신의 EC2 key pair를 입력합니다.
- SSHLocation에는 SSH에 접근 하려는 CIDR IP 주소를 입력합니다.
- Worker Count에는 스택에서 사용할 초기 인스턴스 숫자를 입력합니다. 그리고 Next를 누릅니다.
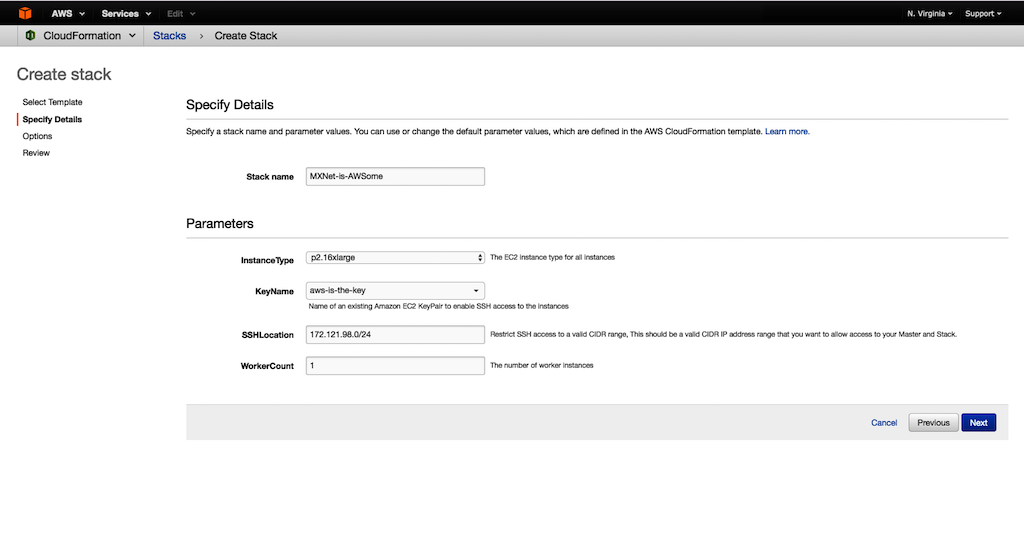
- (선택 사항) Tags에는 여러분이 생성하는 자원에 대한 이름과 명칭을 Key 및 Value에 넣으시면 좋습니다. Permissions에는 CloudFormation이 사용할 IAM 역할을 적당하게 선택하신 후 Next를 선택합니다.
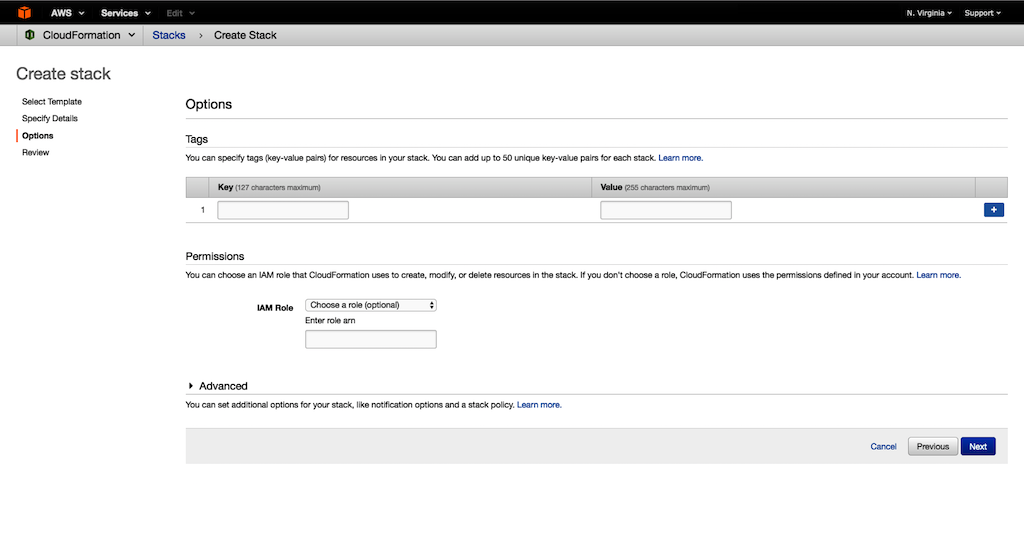
- Capabilities에는 CloudFormation이 생성하고자 하는 IAM 역할을 선택합니다. 스택에 맞는 IAM 역할을 선택하셔야 합니다.
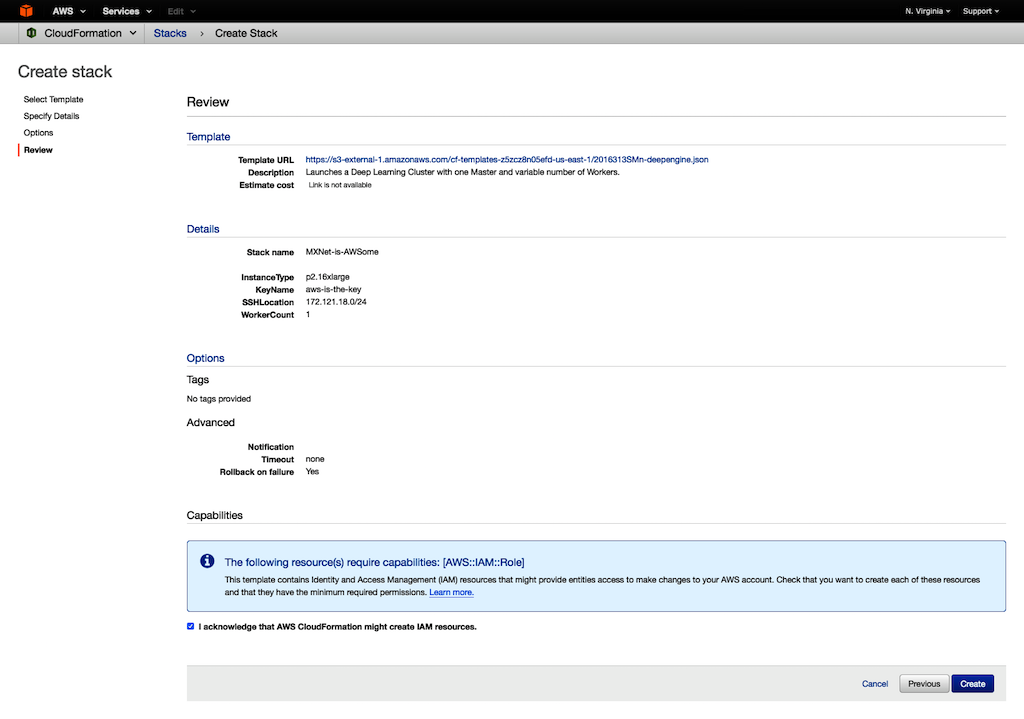
- 마지막으로 Create를 누릅니다.
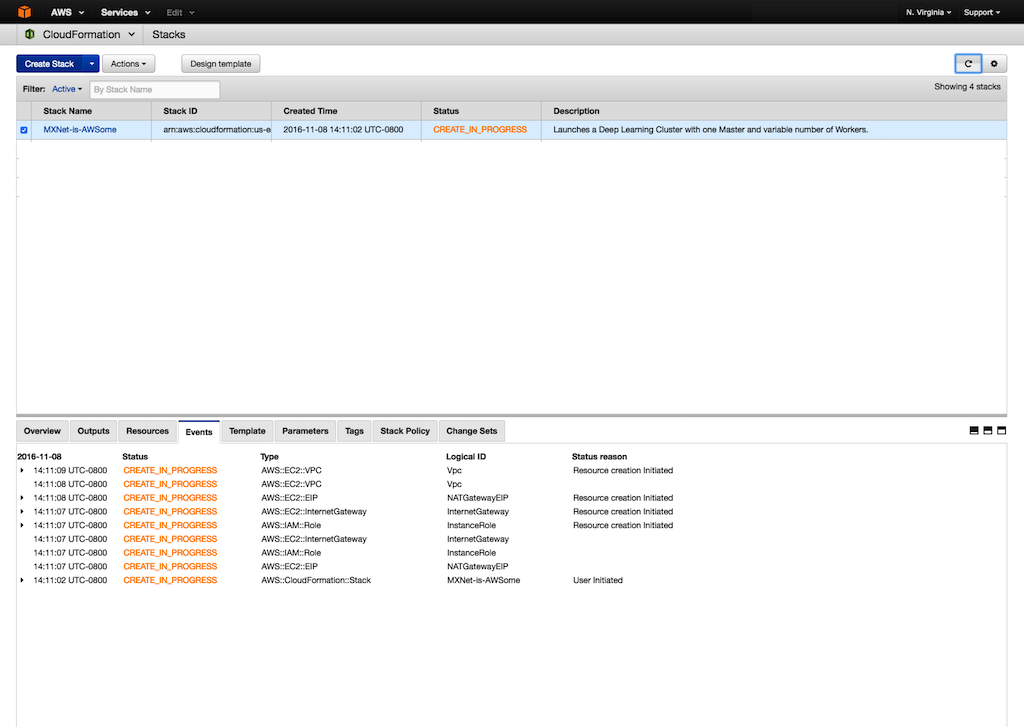
- 스택에 대한 상태를 보시려면, Events을 보시면 됩니다. 만약 구성이 실패하면, (예를 들어 워커 숫자 제한 등) 문제 해결을 할 수 있습니다. 좀 더 자세한 사항은 AWS CloudFormation 문제 해결이나 한국어 기술 지원 포럼을 이용하세요.
- (선택 사항) Tags에는 여러분이 생성하는 자원에 대한 이름과 명칭을 Key 및 Value에 넣으시면 좋습니다. Permissions에는 CloudFormation이 사용할 IAM 역할을 적당하게 선택하신 후 Next를 선택합니다.
마스터 인스턴스 접속하기
SSH 에이전트를 통해 사설망 내 VPC 내부 인스턴스에 안전하게 접속하기 위해서는 Securely Connect to Linux Instances Running in a Private Amazon VPC. 문서를 참고하시기 바랍니다.
- 먼저 마스터 인스턴스의 공개 DNS/IP를 찾습니다. 생성한 CloudFormation 스택의 output 탭을 보시면 마스터 인스턴스 정보가 있습니다. 자동 스케일링 그룹 아이디는 MasterAutoScalingGroup입니다.
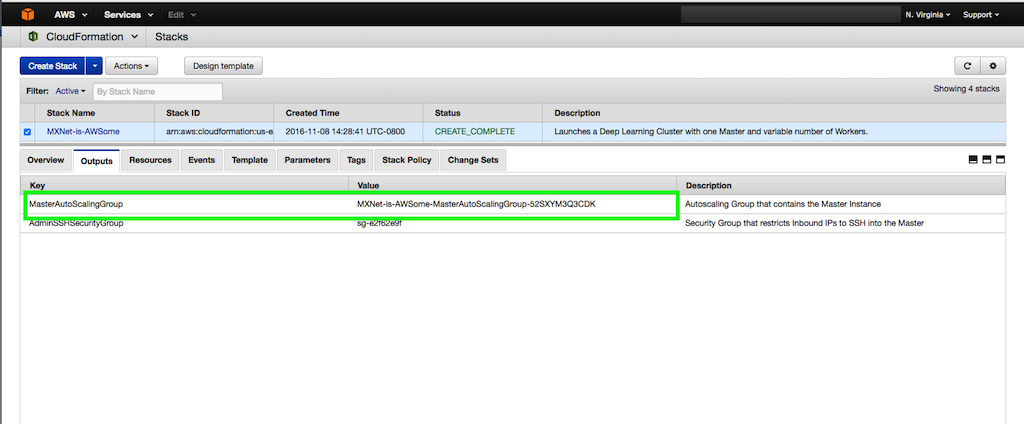
- Amazon EC2 콘솔을 엽니다.
- 왼쪽 네비게이션 패널에서 Auto Scaling를 클릭하고, Auto Scaling Groups을 선택합니다.
- Auto Scaling 페이지에서 그룹 ID를 찾아 선택합니다.
- Instances 탭에서 마스터 인스턴스 ID를 선택합니다.
- 마스터 인스턴스의 공개 DNS/IP를 찾아 접속합니다.
- SSH 에이전트 포워딩을 시작: 사설망 내에 모든 인스턴스와 통신을 할 수 있습니다. 단계 1의 DNS/IP 주소를 통해 아래 Bash의 SSH 설정을 변경합니다.
Bash
Host IP/DNS-from-above ForwardAgent yes - MXNet 분산학습 시작하기: 아래 예제는 병렬 데이터 처리를 위해 MNIST 실행 방법입니다. 환경 변수 중
DEEPLEARNING_*를 사용합니다.Bash#terminate all running Python processes across workers while read -u 10 host; do ssh $host "pkill -f python" ; done 10<$DEEPLEARNING_WORKERS_PATH #navigate to the mnist image-classification example directory cd ~/src/mxnet/example/image-classification #run the MNIST distributed training example ../../tools/launch.py -n $DEEPLEARNING_WORKERS_COUNT -H $DEEPLEARNING_WORKERS_PATH python train_mnist.py --gpus $(seq -s , 0 1 $(($DEEPLEARNING_WORKER_GPU_COUNT - 1))) --network lenet --kv-store dist_sync
좀 더 자세한 학습 훈련 방법을 알아보시려면 Run MXNet on Multiple Devices를 참고하시기 바랍니다.
자주 묻는 질문
1. 마스터 인스턴스의 SSH 접속 IP 주소를 어떻게 바꾸나요? CloudFormation 스택 Output에는 마스터 인스턴스에 SSH 접근하는 IP 주소를 관리하는 보안 그룹이 있습니다. 이 보안 그룹에서 인바운드 IP 주소 변경이 가능합니다.
2. 인스턴스가 바뀔때 IP 주소의 설정이 변경되나요? 아니요. 수동으로 바꾸어야 합니다.
3. 마스터 인스턴스도 학습에 사용되나요? 네. 딥러닝 학습에는 GPU가 사용되므로 학습 및 검증 작업에 함께 사용됩니다.
4. 왜 자동 스케일링 기능을 사용하나요? 자동 스케일링 그룹은 기존 인스턴스에 문제가 생기더라도 원하는 인스턴스 갯수를 항상 맞추는 기능을 제공합니다. 여기에는 두 개의 그룹이 필요한데, 하나는 마스터에 대한 것 그리고 워커에 대한 것입니다. 마스터는 공개 접근 경로를 가지고 있고 학습 작업에 대한 제어가 가능합니다.
5. 새 워커 인스턴스가 추가되거나 기존 인스턴스가 교체되면 마스터 인스턴스 IP주소를 업데이트하나요? 아니오. 이 템플릿은 대체 IP주소를 자동으로 업데이트할 수 있는 기능이 없습니다.
이 글은 Distributed Deep Learning Made Easy의 한국어 번역입니다.
Amazon Linux 콘테이너 이미지 신규 제공
Amazon Linux AMI는 EC2에서 실행 중인 응용 프로그램을 위한 안전하고 안정적인 고성능 실행 환경을 제공합니다. 원격 접근을 제한하며(SSH키로만 접근 가능), AMI는 뛰어난 보안을 자랑합니다.
많은 고객이 Amazon Linux 이미지를 사내에서 특히 개발 작업과 테스트 작업에서 사용하고 싶다는 요청을 하였습니다.
클라우드 뿐만 아니라 온-프레미스에서 사용에 적합한 Amazon Linux Container Image를 오늘 출시합니다. 본 이미지는 EC2 Container Registry에서 구할 수 있습니다 (자세한 것은 Pulling an Image를 참조하십시오). AMI와 같은 소스 코드 같은 패키지로 구성되어 있기 때문에 콘테이너 도입을 쉽게 실행할 수 있습니다. 그대로 사용하거나 자신의 이미지를 만들기 위한 기초로 사용할 수 있습니다.
그것을 시도 때문에 나는 방금 EC2 인스턴스를 시작하고 Docker를 설치하고 새로운 이미지를 가져 와서 실행 해 보았습니다. 그 후, cowsay과 lolcat(종속성)를 설치하고 위의 이미지를 만들었습니다.
자세한 내용은 Amazon Linux Container Image를 읽어 보시기 바랍니다.
본 이미지는 Amazon EC2 Container Service에서 사용할 수 있습니다. 자세한 내용은 Amazon ECR 이미지를 Using Amazon ECR Images with Amazon ECS를 참조하십시오.
— Jeff;
이 글은 New Amazon Linux Container Image for Cloud and On-Premises Workloads의 한국어 번역입니다.
Amazon EC2에서 윈도 서버 2016 실행하기
Amazon Elastic Compute Cloud (EC2)에서 Windows Server 2016 운영체제를 사용할 수 있습니다. 본 운영 체제는 새로운 신규 기능을 많이 포함하고 있으며, Docker 지원 및 Windows 콘테이너를 제공합니다. 오늘 부터 AWS 모든 리전에서 사용 가능합니다.
- Windows Server 2016 Datacenter 데스크톱 버전– 윈도 서버의 주요 버전으로서 기존 윈도우 앱 및 클라우드 네이티브 앱을 모두 지원하고 확장성 및 보안이 높아진 운영 체제로서 더 자시한 것은 The Ultimate Guide to Windows Server 2016를 참고하세요.(등록 필요)
- Windows Server 2016 Nano Server – 클라우드에 최적화된 최소 사양 운영체제로서 데이터센터 버전 보다 디스크 용량 및 부팅을 위한 최소한의 자원만 사용합니다. 나머지 자원은 앱을 구동하기 위한 용도로 사용할 수 있고, 더 자세한 사항은 Moving to Nano Server를 참고하세요. 나노 서버는 데스크톱 UI를 지원하지 않으며 외부에서 PowerShell이나 WMI로 접근할 수 있습니다. 자세한 사항은 Connecting to a Windows Server 2016 Nano Server Instance 문서를 참고하세요.
- Windows Server 2016 with Containers – Docker 및 윈도 콘테이너를 포함한 Windows Server 2016 운영 체제
- Windows Server 2016 with SQL Server 2016 – SQL Server 2016을 이미 포함한 Windows Server 2016 운영 체제
Windows Server 2016을 EC2에 운용하기 위해 몇 가지 알아두셔야 할 점입니다.
- 메모리 – Microsoft는 윈도 서버 운용을 위해 최소 2 GiB 메모리를 권장합니다. EC2 인스턴스 타입를 참고하셔서, 애플리케이션 실행을 염두해 둔 적당한 인스턴스 타입을 선택하시기 바랍니다.
- 가격 – 표준 윈도 EC2 가격이 적용되며, 온디멘드 및 스팟 인스턴스 그리고 예약 인스턴스를 구매할 수 있습니다.
- 라이선스 – (Microsoft의 저작권 규정에 따라) AWS에서 MS 라이선스 SW 사용(BYOL)이 가능합니다.
- SSM 에이전트 – 업그레이드된 SSM 에이전트를 통해 EC2Config를 사용할 수 있고, 자세한 것은 SSM API 가이드를 참고하십시오.
콘테이너 실행해 보기
아래 화면은 Windows Server 2016 with Containers AMI를 통해 실행한 화면입니다.
PowerShell을 열어서 docker run microsoft/sample-dotnet를 실행하면, 도커 이미지를 다운로드해서 실행하게 됩니다.
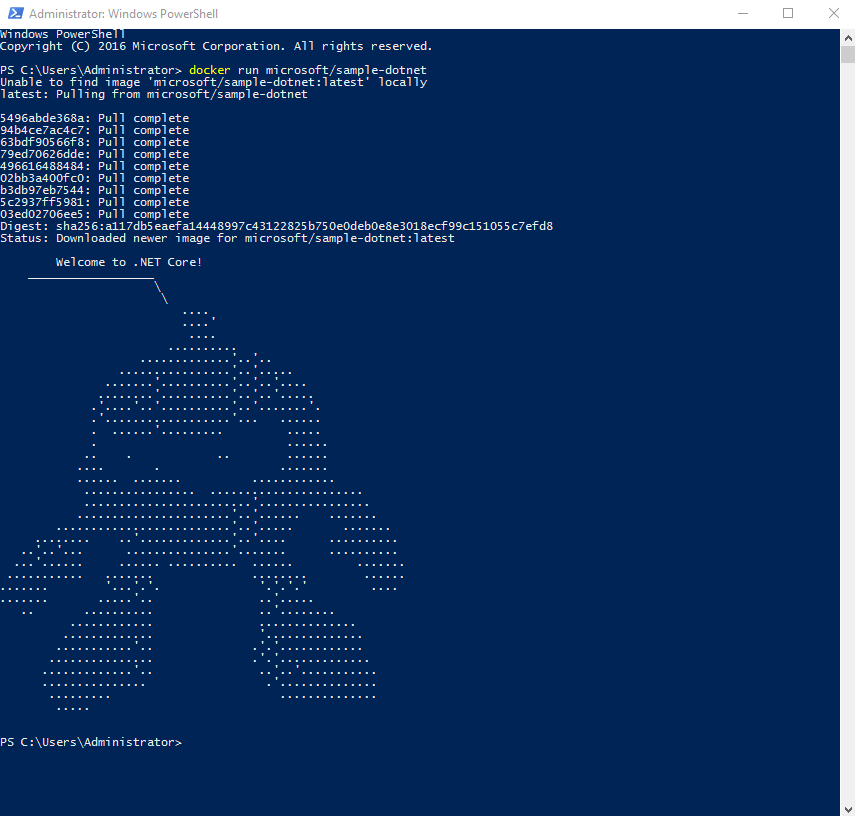
2016년 연말까지 Amazon ECS에 윈도 콘테이너를 지원할 예정입니다. 더 자세한 것은 윈도 ECS 지원 페이지를 참고하세요.
정식 출시
오늘 부터 윈도 서버 2016을 Amazon EC2 인스턴스에서 실행할 수 있으며, 지금 부터 시도해 보시고 의견 있으시면 전달해 주시면 감사하겠습니다!
— Jeff;
이 글은 Run Windows Server 2016 on Amazon EC2의 한국어 번역입니다.
X1 인스턴스 업데이트 – X1.16xlarge 추가 및 서울 리전 출시
작년 가을 저희는 새로운 X1 인스턴스 타입에 대한 계획을 발표하였고, 올해 5월에 x1.32xlarge을 신규 출시하였습니다.

본 인스턴스 타입은 메모리가 많이 소요되는 빅데이터, 캐싱 및 분석 업무를 클라우드에서 실행하면서 더 많은 메모리를 필요로 하는 IT 업무에 최적화 되어 있습니다. 특히, 많은 고객이 SAP HANA 인-메모리 데이터베이스, 대용량 Apache Spark 및 Hadoop 업무와 고성능 컴퓨팅 분야에 활용하고 있습니다.
오늘 두 가지 새로운 소식을 업데이트하게 되었습니다.
- 신규 인스턴스 타입 – 오늘 출시하는 x1.16xlarge 인스턴스는 조금 작은 1TB 메모리 사이즈를 지원
- 서울 리전 출시 – X1 인스턴스는 서울 리전을 포함해서 3개의 추가 리전에서 사용 가능
x1.16xlarge 신규 인스턴스 타입
- 프로세서: 2 x Intel™ Xeon E7 8880 v3 (Haswell) running at 2.3 GHz – 32 cores / 64 vCPUs.
- 메모리: 976 GiB with Single Device Data Correction (SDDC+1).
- 인스턴스 스토리지: 1,920 GB SSD.
- 네트워크 대역폭: 10 Gbps.
- 전용 EBS 대역폭: 5 Gbps (추가 비용 없이 EBS 최적화)
x1.32xlarge처럼 Turbo Boost 2.0 (up to 3.1 GHz), AVX 2.0, AES-NI, 및 TSX-NI를 지원하며 온디멘드, 스팟 인스턴스, 및 전용 호스팅을 지원 합니다. 예약 인스턴스 및 전용 호스팅 예약.도가능합니다.
서울 리전 포함 신규 리전 출시
두 가지 X1 인스턴스 타입 모두 Asia Pacific (Seoul), Asia Pacific (Mumbai), AWS GovCloud (US)에서 새로 출시하였으며, 총 10개의 리전에서 현재 사용 가능합니다.
— Jeff;
이 글은 X1 Instance Update – X1.16xlarge + More Regions의 한국어 번역입니다.
Amazon CloudWatch를 위한 collectd 플러그인 공개
대부분 고객들은 Amazon CloudWatch에 많은 애플리케이션 통계 데이터를 저장해 왔습니다. (자세한 내용은 New – Custom Metrics for Amazon CloudWatch 참고) 이 블로그에서 “사용자의 AWS 자원을 CloudWatch를 통해 통계 수치를 통해 그래프로 표시하거나 알림을 설정하거나, 자동화 작업을 할 수 있다.”라고 소개하였습니다.
오늘 부터 collectd 기반 새로운 CloudWatch 플러그인를 사용하여 사용자 시스템에서 통계를 수집하여, CloudWatch에 저장할 수 있습니다. 다양한 유형의 통계를 수집하는 collectd 기능과 저장 및 표시 그리고 경고를 알릴 수 있는 CloudWatch 기능을 결합하여 EC2 인스턴스의 상태와 성능, EC2에서 실행하는 온프레미스 하드웨어나 응용 프로그램에 대해 자세히 파악할 수 있습니다. 본 플러그인은 오픈 소스 프로젝트로 시작하였고, 여러분의 피드백을 기다리고 있습니다.
collectd 데몬은 성능을 위해 C로 작성되어 있습니다. 현재 100개 이상의 플러그인을 지원하고 Apache 및 Nginx 웹 서버 성능, 메모리 사용량, 가동 시간 통계를 수집 할 수 있습니다.
collectd 설치 및 설정
실제 동작을 살펴보기 위해 collectd과 새로운 플러그인을 EC2 인스턴스에 설치하고 구성해 보았습니다.
먼저 CloudWatch에 통계 데이터를 쓸 수 있는 권한을 제공하기 위한 IAM 정책(Policy)을 만듭니다.
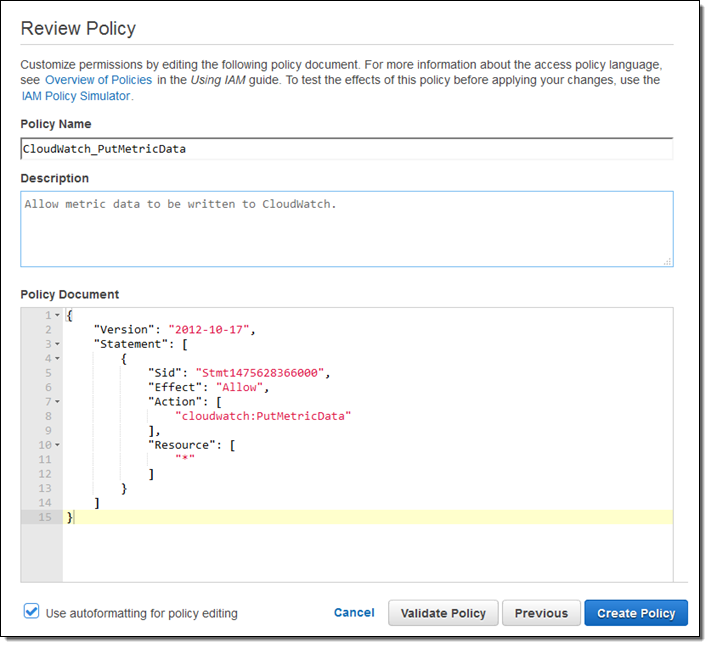
이 정책을 활용하여 만들어진 EC2에 접근할 수 있는 IAM 역할(Role)을 만들었습니다.
기존 서버에서 통계를 수집하기 위해 플러그인을 사용하려는 경우, (이미 EC2 인스턴스를 실행하는 경우) 이러한 단계를 진행하지 않고 적절한 접근 권한을 사용하여 IAM 사용자를 생성 합니다.
이제 IAM 정책 및 역할이 준비 되면, EC2 인스턴스를 시작하고 관련 역할을 선택합니다.
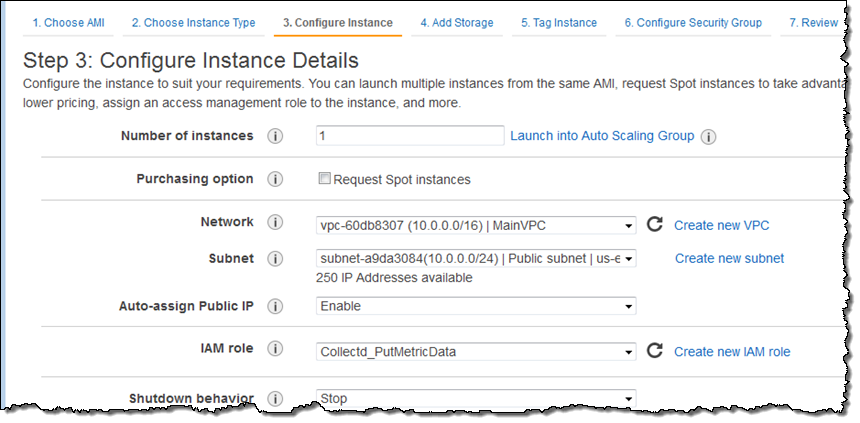
로그인 후, collectd를 설치합니다.
$ sudo yum -y install collectd플러그인을 설치할 스크립트의 실행 권한을 설정한 뒤 실행합니다.
Then I fetched the plugin and the install script, made the script executable, and ran it:
$ chmod a+x setup.py
$ sudo ./setup.py
몇 가지 질문에 응답한 후, 문제없이 설정을 수행 할 수 있습니다. collectd 설정 완료 후 시작합니다.
Installing dependencies ... OK
Installing python dependencies ... OK
Copying plugin tar file ... OK
Extracting plugin ... OK
Moving to collectd plugins directory ... OK
Copying CloudWatch plugin include file ... OK
Choose AWS region for published metrics:
1. Automatic [us-east-1]
2. Custom
Enter choice [1]: 1
Choose hostname for published metrics:
1. EC2 instance id [i-057d2ed2260c3e251]
2. Custom
Enter choice [1]: 1
Choose authentication method:
1. IAM Role [Collectd_PutMetricData]
2. IAM User
Enter choice [1]: 1
Choose how to install CloudWatch plugin in collectd:
1. Do not modify existing collectd configuration
2. Add plugin to the existing configuration
Enter choice [2]: 2
Plugin configuration written successfully.
Stopping collectd process ... NOT OK
Starting collectd process ... OK
$
collectd을 수행할 플러그인 설치와 설정이 완료되면, 다음 단계는 필요한 통계 항목을 결정하여 CloudWatch로 보내도록 플러그인을 설정하는 것입니다 (각 통계마다 요금이 발생할 수 있으므로, 이것은 중요한 단계입니다).
/opt/collectd-plugins/cloudwatch/config/blocked_metrics는 수집한 통계 목록이 포함되어 있으나 CloudWatch에 보내지는 않습니다.
$ cat /opt/collectd-plugins/cloudwatch/config/blocked_metrics
# This file is automatically generated - do not modify this file.
# Use this file to find metrics to be added to the whitelist file instead.
cpu-0-cpu-user
cpu-0-cpu-nice
cpu-0-cpu-system
cpu-0-cpu-idle
cpu-0-cpu-wait
cpu-0-cpu-interrupt
cpu-0-cpu-softirq
cpu-0-cpu-steal
interface-lo-if_octets-
interface-lo-if_packets-
interface-lo-if_errors-
interface-eth0-if_octets-
interface-eth0-if_packets-
interface-eth0-if_errors-
memory--memory-used
load--load-
memory--memory-buffered
memory--memory-cached
메모리 사용량에 대한 로그를 남기기 위해 /opt/collectd-plugins/cloudwatch/config/whitelist.conf를 추가합니다.
memory--memory-.*collectd 설정 파일 (/etc/collectd.conf)는 collectd와 플러그인 설정을 포함하고 있습니다. 이번 경우는 변경할 필요는 없습니다.
전체 변경을 사항을 적용하기 위해, collectd를 다시 시작합니다.
$ sudo service collectd restart
메모리를 사용량을 높이기 위해, 인스턴스를 조금 사용하고 CloudWatch 콘솔을 열어 필요한 부분을 표시했습니다.
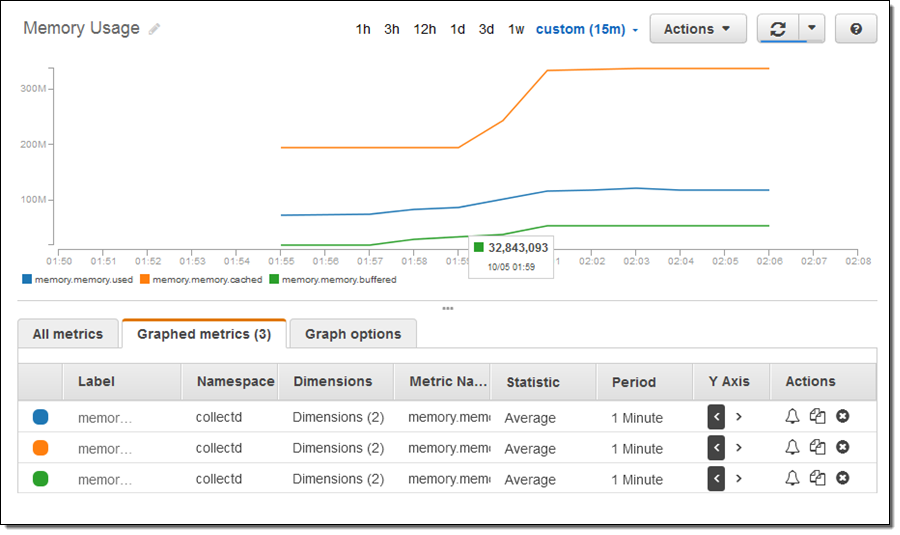
위의 스크린샷은 CloudWatch 콘솔에 탑재된 미리 보기 기능에 포함되어 있으므로 자신의 화면에 같은 것이 표시되지 않더라도 놀라지 마세요. (자세한 내용은 향후 알려드립니다).
정식 서비스 중인 인스턴스를 모니터링하는 경우, collected 플러그인을 하나이상 설치할 수 있습니다. Amazon Linux AMI에서 사용할 수 있는 목록은 아래를 참조하십시오.
$ sudo yum list | grep collectd
collectd.x86_64 5.4.1-1.11.amzn1 @amzn-main
collectd-amqp.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-apache.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-bind.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-curl.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-curl_xml.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-dbi.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-dns.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-email.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-generic-jmx.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-gmond.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-ipmi.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-iptables.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-ipvs.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-java.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-lvm.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-memcachec.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-mysql.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-netlink.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-nginx.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-notify_email.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-postgresql.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-rrdcached.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-rrdtool.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-snmp.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-varnish.x86_64 5.4.1-1.11.amzn1 amzn-main
collectd-web.x86_64 5.4.1-1.11.amzn1 amzn-main
알아 두실 점
collectd 버전 5.5 이상을 사용하는 경우, 아래 네개의 통계를 기본적으로 지원합니다.
- df-root-percent_bytes-used – 디스크 속도
- memory–percent-used – 메모리 사용량
- swap–percent-used – swap 사용량
- cpu–percent-active – cpu 사용량
원하지 않는 경우, whitelist.conf 파일에서 제거 할 수 있습니다.
현재 Amazon Linux AMI, Ubuntu, RHEL, CentOS 기본 저장소는 이전 버전의 collectd를 제공하고 있습니다. 사용자 저장소에서 설치하거나, 소스에서 직접 빌드한 경우 기본 설정이 다른 점을 유의하시기 바랍니다.
참고 사항
추가적인 collectd 플러그인도 whitelist.conf 파일을 설정하여, 더 많은 통계 데이터를 CloudWatch에 제공할 수 있습니다. CloudWatch 알람을 생성하고 사용자 정의 대시 보드 등을 할 수 있습니다.
시작은 GitHub의 AWS 연구소 를 방문하여 collectd의 CloudWatch 플러그인 을 다운로드하십시오.
더 자세한 사항은 GitHub에서 collectd CloudWatch 플러그인를 다운로드 하세요.
— Jeff;
이 글은 New – CloudWatch Plugin for collectd의 한국어 번역입니다.
EC2 예약 인스턴스 업데이트 – RI 변환 기능 및 리전 단위 적용
Amazon EC2 예약 인스턴스(Reserved Instance, RI) 구매 옵션은 8 년 전에 발표 되었습니다. 2009년에 시작 된 이 구매 모델에는 두 가지 장점이 있습니다. 먼저, 컴퓨팅 용량을 미리 예약함으로서 가용 영역(AZ) 내 특정 인스턴스 사용에 적용하는 대폭적인 할인율입니다. 몇 년 동안 고객 의견과 요구에 따라 이 모델을 개선하여 일정 기반 예약 인스턴스, 예약 수정 기능, Reserved Instance Marketplace를 통한 RI 매매 기능을 추가하였습니다. 오늘 두 가지의 기능을 강화하고자 합니다.
- 리전(Region) 단위 할인 – 많은 AWS 고객이 용량 예약보다 할인율이 더 중요하며, 유연성이 증가한다면 할인율은 내려가도 무방하다는 의견을 주셨습니다. 그래서, 표준 RI에 용량을 예약하지 않고, 리전 내 중 하나의 AZ에서 실행한 인스턴스에 RI 할인이 자동으로 적용되도록 선택할 수 있습니다.
- 변환 가능한(Convertible) 예약 인스턴스 – 변환 가능 RI는 유연성와 함께 높은 할인 (On-Demand에 비해 일반적으로 45%할인) 받을 수 있습니다. 예약 인스턴스와 연관된 인스턴스 패밀리 및 기타 매개 변수는 언제든지 변경할 수 있습니다. 예를 들어, 새로운 인스턴스 유형을 활용하기 위해 C3 RI를 C4 RI로 변환하거나, 응용 프로그램으로 인해 메모리 증가가 필요한 경우, C4 RI를 M4 RI로 변환 할 수 있습니다. 또한, EC2 가격 인하 를 계속 활용하기 위해 Convertible RI를 사용할 수 있습니다.
각각에 기능에 대해 자세히 살펴 보겠습니다.
리전(Region) 단위 적용
예약 인스턴스 (표준 또는 변환 가능)를 리전 내 모든 가용 영역(AZ)에 자동으로 적용하도록 설정할 수 있습니다. 이러한 리전 단위 적용을 통해 모든 가용 영역 내 RI 모델이 각 인스턴스에 자동으로 적용됨으로서, RI 할인 적용 범위가 넓어집니다. 이를 위해 별도의 용량 예약을 할 필요 없이, 인스턴스 가용 영역 선택이 필요합니다. 자주 인스턴스를 시작하고, 사용 및 종료하는 동적 환경에서는 이를 통해 컴퓨팅 용량 유연성이 증가하고 RI를 적용하는 최적 인스턴스 선택에 걸리는 시간이 짧아집니다. Auto Scaling를 통해 시작되어, Elastic Load Balancing의해 연결되는 인스턴스에서 수평적 확장이 가능한 아키텍처에서 큰 도움이 될 것입니다.
AWS Management Console 에서 Purchase Reserved Instances를 클릭 한 후 Search를 선택하면, 가능한 RI가 표시됩니다.
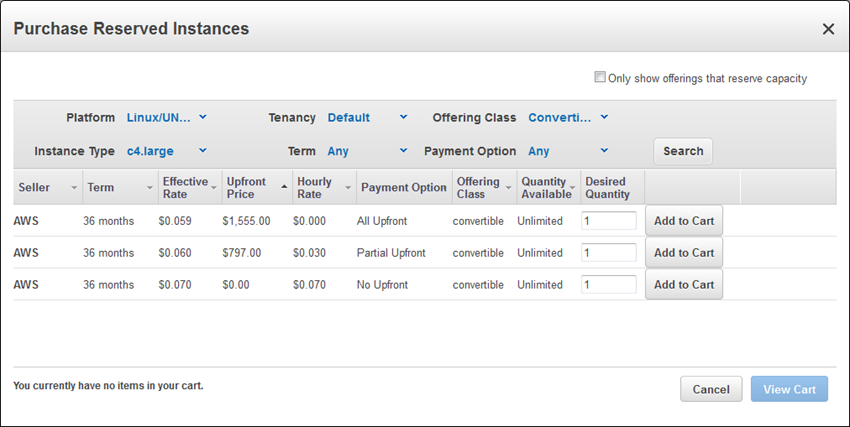
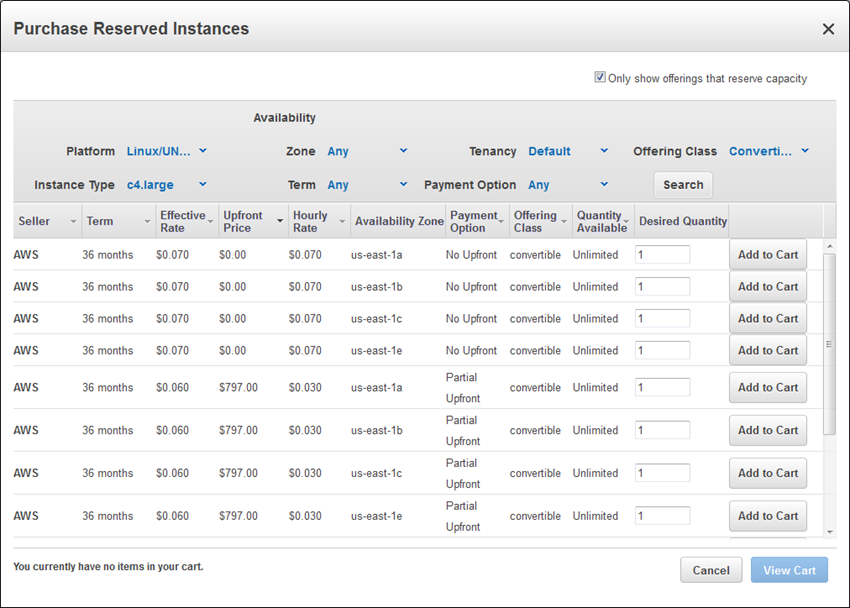
기존 처럼 하나의 가용 영역에 적용하는 용량 예약하는 RI를 구입하는 경우 Only show offerings that reserve capacity에 체크를 선택합니다.
RI 변환 기능
RI를 구입하는 고객의 목적은 일정하게 각 사용량에 맞는 인스턴스를 사용함으로서, 할인을 통한 가격적 이점을 보기 위함입니다. 그러나, 장기적인 관점에서 요구 사항에 따라 이에 대한 변경이 있을 경우, RI 인스턴스 타입의 변경이 필요합니다. 이를 위해서, RI 변환 기능을 사용할 수 있습니다. 요구 사항이 변경되는 경우, 변환 가능한(Convertible) 예약 인스턴스로 교체하면 됩니다. 계약 조건을 재설정하지 않고 새로운 인스턴스 유형 및 운영 체제를 설정한 변환 가능한 RI로 교체 할 수 있습니다. 교환은 무료로 언제든지 가능합니다.
교체 할 때, 원래 RI와 같거나 그 이상의 새로운 RI를 선택해야 하며, 경우에 따라서는 차액을 지불할 수 있습니다. 교환 프로세스는 각 Convertible RI의 정가를 기준으로 합니다. 이 가격은 교환하고자 하는 원본 RI 잔존 기간의 지불 금액 합계입니다.
Convertible RI를 구입하려면, Search를 클릭하기 전에 Offering Class를 Convertible로 변경하십시오.
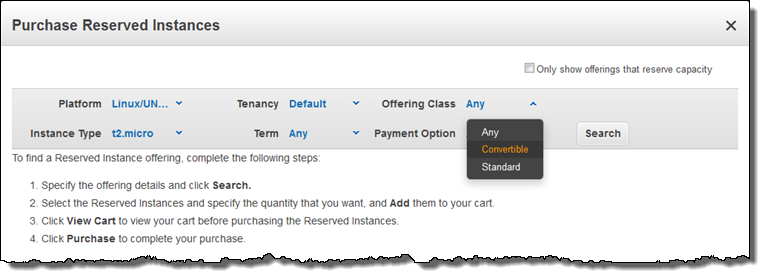
Convertible RI는 용량 예약 뿐만 아니라 On-Demand에 비해 일반적으로 45% 할인 받을 수 있습니다. Convertible RI는 3년 계약에 대한 모든 EC2 인스턴스 타입에 적용할 수 있습니다. 3개의 모든 지불 옵션 (선불없음, 일부 선불, 전액 선불)를 사용할 수 있습니다.
정식 출시
위의 구입 및 교환 옵션은 AWS Management Console, AWS Command Line Interface (CLI), AWS Tools for Windows PowerShell 또는 Reserved Instance APIs (DescribeReservedInstances, PurchaseReservedInstances, ModifyReservedInstances 등)에서 설정할 수 있습니다.
AWS Management Console , CLI, AWS Tools for Windows PowerShell 또는 Reserved Instance APIs ( DescribeReservedInstances , PurchaseReservedInstances , ModifyReservedInstances 등)에서 액세스 할 수 있습니다.
Convertible RI 및 리전 단위 적용 기능은 AWS GovCloud (US) 와 China (Beijing)을 제외한 모든 AWS 리전에서 사용할 수 있습니다. 이 두 리전에서도 곧 사용할 수 있을 예정입니다.
— Jeff;
이 글은 EC2 Reserved Instance Update – Convertible RIs and Regional Benefit의 한국어 번역입니다.