Category: AWS Lambda
Lambda@Edge 정식 출시 – 엣지 기반 HTTP 호출에 대한 지능적 처리 기능
지난해 말 Lambda@Edge의 미리 보기를 발표하여, 고객에게 가까이 있는 (대기 시간 기반) 엣지 로케이션에서 HTTP 요청을 지능적으로 처리하는 방법에 대해 설명했습니다. 미리 보기를 사용해 본 개발자 고객들은 이를 잘 활용하면서 많은 도움이 되는 피드백을 제공했습니다. 미리보기 테스트 중에 HTTP 응답을 생성하고 CloudWatch 통계를 지원하는 기능을 추가했으며, 피드백을 기반으로 향후 로드맵을 수정했습니다.
오늘 부터 Lambda@Edge가 정식 출시 되어 누구나 사용 가능합니다. 아래는 주요 사용 사례 입니다.
- A/B 테스트를 수행하여, 쿠키 검사 및 URL 리다이렉트
- User-Agent 헤더를 기반으로 특정 객체를 사용자에게 전송
- HTTP 요청을 원본으로 전달하기 전에 특정 헤더를 찾아 접근 제어
- HTTP 헤더를 추가, 삭제 또는 수정하여 사용자에게 다른 캐시 정보 사용
- 신규 HTTP 응답 생성
- 레거시 URL 에 대한 지원
- HTTP 헤더 또는 URL을 수정 또는 압축하여 캐시 활용도 향상
Lambda@Edge를 활용하면 풍부한 개인적 웹 기반 사용자 환경을 만들 수 있습니다. 서버리스 기반이 빠르게 표준화 되고 있으므로, 이제 가상 서버를 프로비저닝하거나 관리 할 필요가 없습니다. 프로그래밍 코드 (Node.js로 작성된 람다 함수)를 업로드하고, Amazon CloudFront 배포판과 연결하면 됩니다. 그런 다음 원하는 CloudFront 이벤트와 함께 배포용으로 만든 CloudFront 동작 중 하나를 선택합니다.
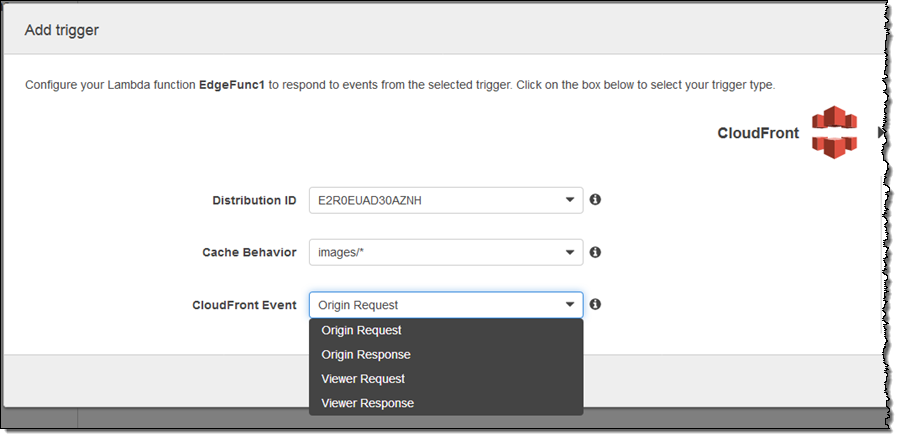
위의 경우, 람다 함수 (가상으로 이름 붙인 EdgeFunc1)는 지정 배포 지점에서 image/*에 대한 원래 요청에 응답하여 실행합니다. 보시다시피 네 가지 CloudFront 이벤트에 대한 응답으로 코드를 실행할 수 있습니다.
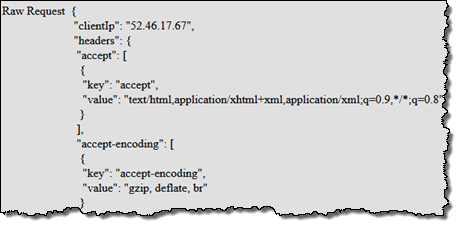
뷰어 요청 (Viewer Request) -이 이벤트는 뷰어 (HTTP 클라이언트, 일반적으로 웹 브라우저 또는 모바일 앱)에서 이벤트가 도착하고 들어오는 HTTP 요청에 접근할 때 동작합니다. 각 CloudFront Edge 로케이션은 반복되는 요청에 효율적으로 응답 할 수 있도록 객체 캐시를 유지합니다. 이 특정 이벤트는 요청 된 개체가 이미 캐시되어 있는지 여부에 관계없이 동작합니다.
오리진 요청(Origin Request) -이 이벤트는 요청된 객체가 엣지 로케이션에 캐시되지 않기 때문에 오리진으로 다시 요청하려고 할 때 동작합니다. 오리진 요청 (종종 S3 버킷 또는 EC2 인스턴스에서 실행되는 코드)에 접근할 수 있습니다.
오리진 응답 (Origin Response) -이 이벤트는 오리진이 요청에 대한 응답을 반환 한 후에 동작합니다. 오리진의 응답에 접근할 수 있습니다.
뷰어 응답 (Viewer Response) – 엣지 로케이션 뷰어에 응답을 반환하기 전에 이벤트가 동작합니다. 응답에 대한 액세스 권한이 있습니다.
람다 함수는 중국을 제외한 모든 AWS 엣지 로케이션과 공개 리전에 자동 복제됩니다. HTTP 요청은 자동 실행을 위해 최적의 위치로 라우팅됩니다. 프로그램 코드를 한번에 배포하여, 전 세계 사용자가 낮은 지연 시간으로 실행할 수 있습니다.
소스 코드에는 HTTP 헤더, 쿠키, 메소드 (GET, HEAD 등) 및 URI를 비롯한 요청 및 응답에 대한 모든 접근 권한이 있습니다. 몇 가지 제한 사항에 따라 기존 헤더를 수정하고 새 헤더를 삽입 할 수 있습니다.
Lambda@Edge 직접 사용해 보기
뷰어 요청 이벤트에 응답하여 실행되는 간단한 함수를 작성해 보겠습니다. 람다 콘솔을 열고 새로운 함수를 만듭니다. Node.js 6.10 런타임을 선택하고 cloudfront 예제를 검색합니다.
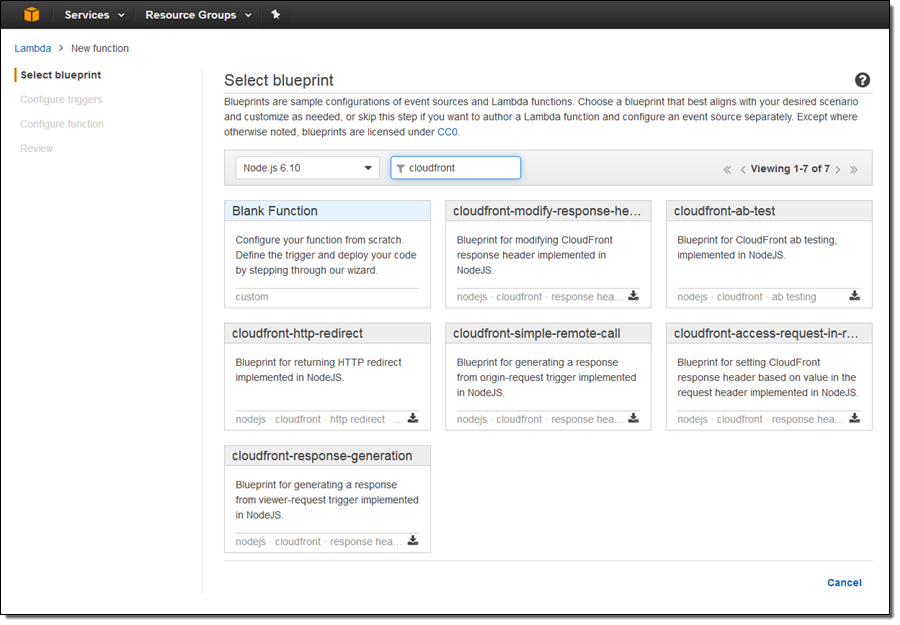
cloudfront-response-generation을 선택하고 함수를 호출하는 트리거를 구성합니다.
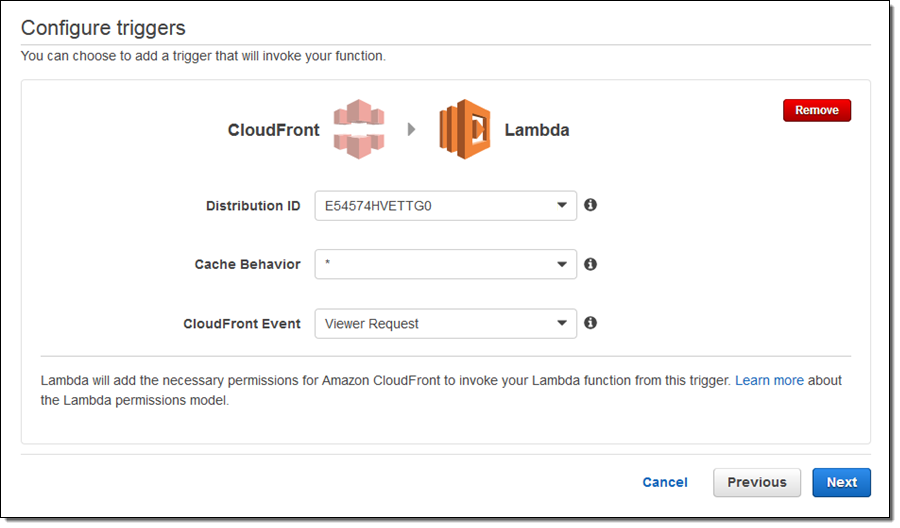
람다 콘솔은 본 함수를 위한 운영 환경에 대한 몇 가지 정보를 제공합니다:
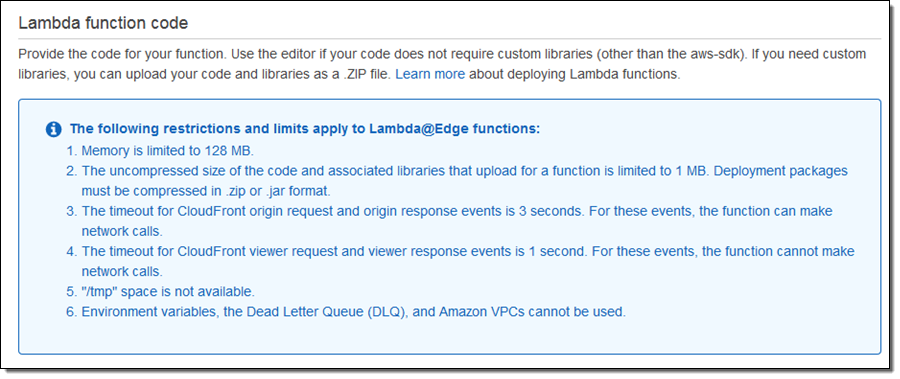
평소대로 함수에 대한 이름과 설명을 입력합니다.
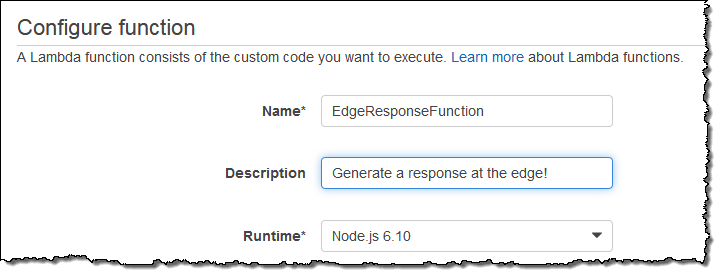
예제에는 완전한 기능이 작동되도록 되어 있습니다. “200” HTTP 응답에 대한 간단한 동작을 생성합니다.
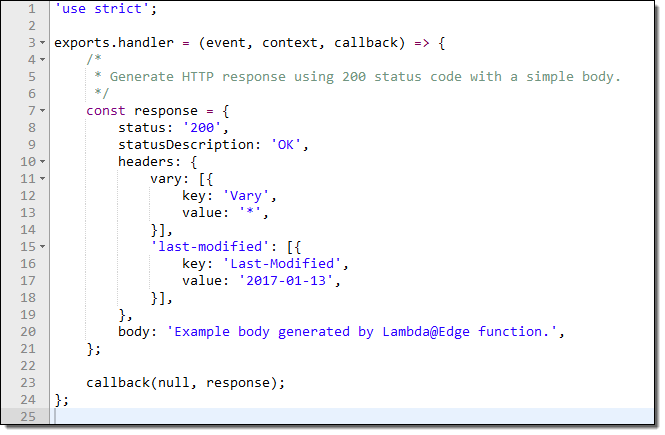
소스 코드를 내 자신 코드의 시작점으로 사용하여 HTTP 요청에서 흥미로운 값을 가져 와서 테이블에 표시합니다.
핸들러를 구성하고 Basic Edge Lambda 권한을 사용하여 새 IAM 역할을 만들도록 요청합니다.
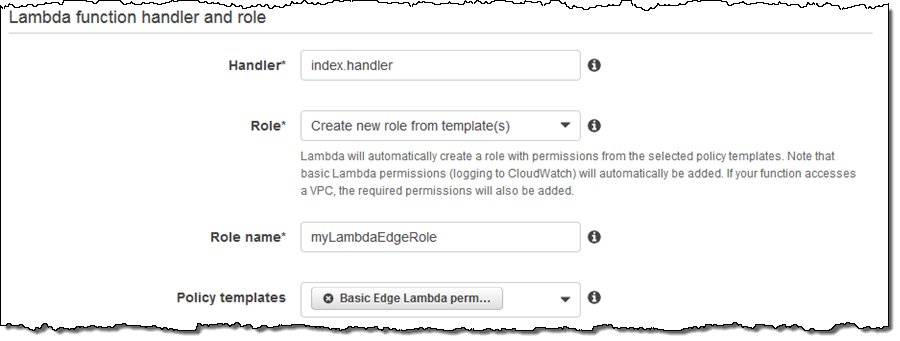
다음 페이지에서 (일반적인 람다 함수처럼) 설정을 확인하고 Create function을 클릭한다.
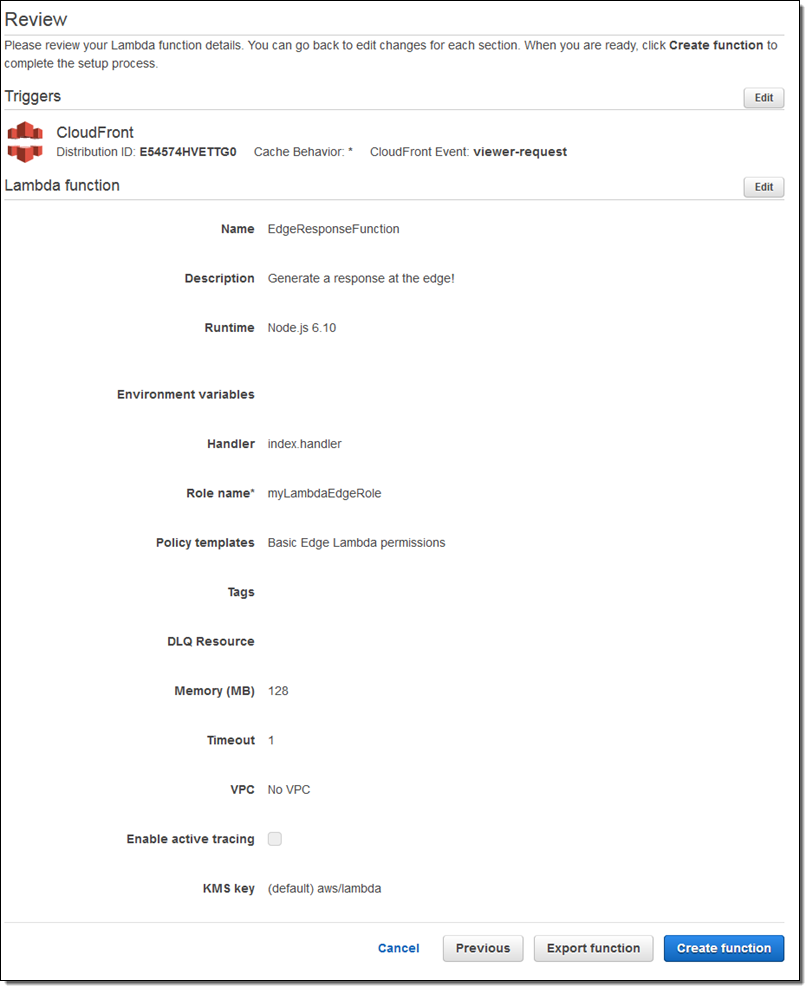
이렇게 하면 람다 함수가 만들어지고, 코드 배포 기능이 실행되어 각 CloudFront에 함수 복제가 시작됩니다. 내 배포 상태가 복사 기간 동안 In Progress으로 변경됩니다 (일반적으로 5-8 분).
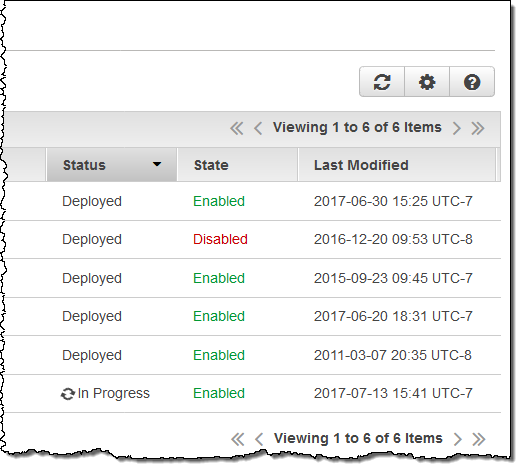
복제가 완료되면 즉시 상태가 Deployed로 변경됩니다.
그런 다음 배포본 (https://dogy9dy9kvj6w.cloudfront.net/) 루트에 접근하면 함수가 실행되는 것을 볼 수 있습니다.
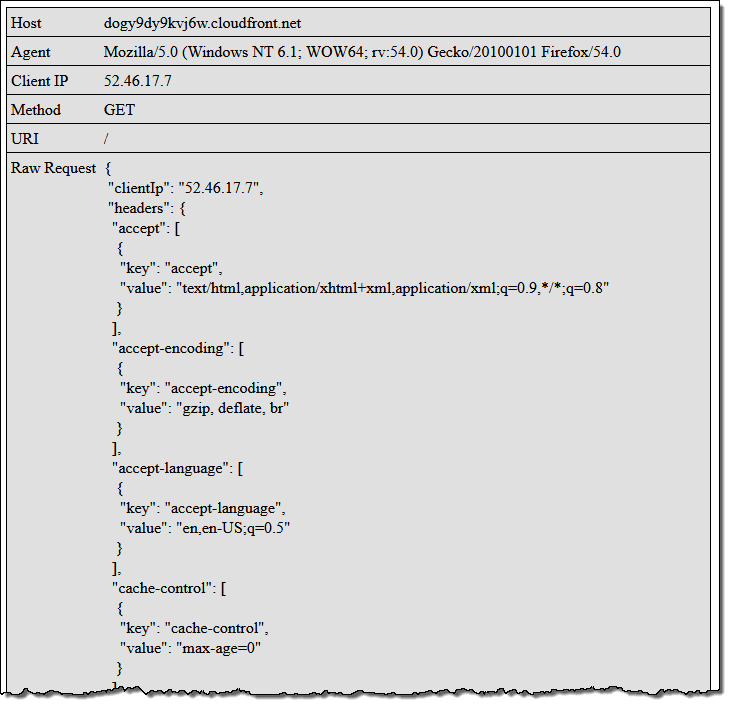 코드를 실행하려면 이미지를 클릭하십시오 (내 배포판의 루트에 링크되어 있음)!
코드를 실행하려면 이미지를 클릭하십시오 (내 배포판의 루트에 링크되어 있음)!
늘 그렇듯이 간단한 예이며, 이 후 여러분이 훨씬 더 잘할 수 있다고 확신합니다. 다음은 시작하기 위한 몇 가지 아이디어입니다.
- 복구 사이트 관리 – 전체 동적 웹 사이트를 오프라인으로 전환하고, 유지 관리 또는 재해 복구 작업 중 중요한 페이지를 Lambda@Edge 기능으로 대체 할 수 있습니다.
- 대용량 정적 콘텐츠 – 스코어 보드, 일기 예보 또는 공공 안전 페이지를 작성하여, 엣지에서 빠르고 비용 효율적으로 사용할 수 있습니다.
멋진 것을 만들고 의견이나 블로그 게시물에서 공유하십시오. 그러면 살펴 보겠습니다.
알아 두어야 할 점들
Lambda@Edge를 응용 프로그램에서 사용하는 방법을 생각할 때 염두에 두어야 할 몇 가지 사항이 있습니다.
- Timeouts – Origin Request 및 Origin Response 이벤트를 처리하는 함수는 3 초 이내에 완료되어야 합니다. 뷰어 요청 및 뷰어 응답 이벤트를 처리하는 기능은 1 초 이내에 완료되어야합니다.
- 버전 관리 – 람다 콘솔에서 코드를 업데이트 한 후에는 새 버전을 게시하고 이에 대한 새로운 트리거 세트를 설정 한 다음 복제가 완료 될 때까지 기다려야합니다. 버전 번호를 사용하여 항상 코드를 참조해야합니다. $LATEST 및 별칭은 적용되지 않습니다.
- 헤더 – 내 코드에서 볼 수 있듯이 HTTP 요청 헤더는 배열로 액세스 할 수 있습니다. 헤더는 네 가지 범주로 나뉩니다.
- 액세스 가능 – 읽기, 쓰기, 삭제 또는 수정할 수 있음
- 제한됨 – 원본으로 전달 필요
- 읽기 전용 – 읽을 수는 있지만 어떤 방식 으로든 수정할 수는 없음
- 블랙 리스트 – 코드에서 볼 수 없으며 추가 할 수 없음
- 런타임 환경 – 런타임 환경은 각 기능에 128MB의 메모리를 제공하지만 내장 라이브러리 나 / tmp에 대한 액세스는 제공하지 않습니다.
- 웹 서비스 접근 – Origin Request 및 Origin Response 이벤트를 처리하는 기능이 3 초 이내에 완료되어야 AWS API에 액세스하고 HTTP를 통해 컨텐츠를 가져올 수 있습니다. 이러한 요청은 항상 원본 요청 또는 응답에 대한 요청과 동 기적으로 이루어집니다.
- 함수 복제 – 앞에서 언급했듯이 함수는 중국의 AWS 영역을 제외한 모든 공용 AWS 영역에 복제됩니다. 복제본은 람다 콘솔의 “기타”영역에서 볼 수 있습니다.
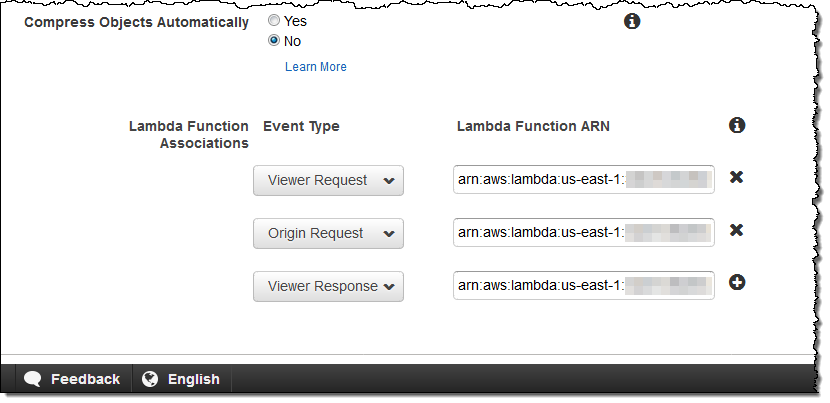
CloudFront 동작에 대해 이미 알고 있는 모든 것이 Lambda@Edge와 관련이 있습니다. 각 동작에서 여러 동작 (최대 4 개의 Lambda@Edge 함수 포함)을 사용하고, HTTP 헤더 및 쿠키 전달을 사용자 정의 할 수 있습니다. 동작을 편집하는 동안 이벤트 버전과 함수 (함수 버전을 포함하는 ARN을 통해)를 연결할 수도 있습니다.
정식 출시
Lambda@Edge는 현재 이용 가능하며, 지금 바로 사용하실 수 있습니다. 가격은 기능 호출 횟수 및 실행 시간을 기준으로 합니다 (자세한 정보는 Lambda@Edge 가격 책정 페이지 참조).
— Jeff;
이 글은 Lambda@Edge – Intelligent Processing of HTTP Requests at the Edge의 한국어 번역입니다.
AWS X-Ray, AWS Lambda 지원 공식 출시
AWS X-Ray에 대한 AWS Lambda 지원 기능을 출시했습니다. 지난 샌프란시스코 서밋에서 정식 출시한 AWS X-Ray는 분산 응용 프로그램의 실행 및 성능 동작을 분석하는 AWS 서비스입니다. 전통적인 디버깅 방식은 여러 서비스가 실행되는 독립 구성 요소가 있는 마이크로 서비스 기반 응용 프로그램에서는 잘 작동하지 않습니다. X-Ray를 사용하면 응용 프로그램의 대기 시간을 줄임으로써 오류, 속도 저하 및 시간 초과를 신속하게 진단 할 수 있습니다. 간단한 람다 기반 응용 프로그램을 작성하고 분석함으로써 우리의 응용 프로그램에서 X-Ray를 잠깐 사용하는 방법을 보여 드리겠습니다.
바로 시작하기를 원할 경우, 람다 함수 페이지로 이동하여 추적 기능을 활성화하여 기존 람다 함수에 대해서도 X-Ray 추적 기능을 쉽게 켤 수 있습니다.

또는 AWS 명령 행 인터페이스 (CLI)에서 함수의 tracing-config 를 업데이트하여 시작 가능합니다. (--function-name도 전달해야 함)
$ aws lambda update-function-configuration --tracing-config '{"Mode": "Active"}'
추적 모드가 활성화되면 Lambda는 함수에 대해 즉시 추적을 시작합니다. 그렇지 않으면, 업스트림 서비스에서 명시 적으로 지시 한 경우에만 함수가 추적됩니다. 추적 기능을 사용하면 응용 프로그램 리소스와 그 사이의 연결 을 시각적으로 나타냅니다. 주목해야 할 것은 X-Ray 데몬이 람다 함수의 리소스 중 일부를 사용한다는 것입니다. 메모리 제한에 가까워지면, Lambda는 메모리 부족 오류가 발생하지 않도록 X-Ray 데몬을 중단 시킬 수 있습니다.
몇 가지 다른 서비스를 사용하는 빠른 애플리케이션을 구축하여 신규 연동 테스트를 해 보겠습니다.
스마트폰에서 찍은 셀카가 많아서 이를 분석해 보려고 합니다. Amazon Simple Storage Service (S3) 버킷에 업로드 된 새로운 이미지에 응답하는 Java 8 런타임을 사용하여 간단한 Lambda 함수를 작성합니다. 이 샘플 앱은 사진에 Amazon Rekognition 을 사용하여, 이미지 내 객체를 인식하고 검색된 레이블을 Amazon DynamoDB에 저장합니다.

먼저 몇 가지 X-Ray 서비스에서 사용하는 용어를 살펴보겠습니다.
X-Ray가 서비스 그래프를 생성하여 추적 결과를 구성한다고 쉽게 이해할 수 있습니다. 서비스 그래프는 우리가 위에서 볼 수 있는 멋진 시각적 표현을 만듭니다 (여러 가지 색상이 다양한 요청 응답을 나타냅니다). 응용 프로그램을 실행하는 컴퓨팅 리소스는 segment의 형태로 수행 중인 작업에 대한 데이터를 보냅니다. 하위 데이터를 작성하여 해당 데이터에 대한 주석을 추가하고, 세분화 된 타이밍을 추가 할 수 있습니다. 응용 프로그램을 통한 요청 경로는 traces로 추적합니다. traces는 단일 요청으로 생성 된 모든 segment를 수집합니다. 즉, S3에서 들어오는 Lambda 이벤트를 DynamoDB로 쉽게 추적 할 수 있으며 오류 및 대기 시간이 어느 부분에 있는지 파악할 수 있습니다.
이제 selfies-bucket이라는 S3 버킷, selfies-table이라는 DynamoDB 테이블, 그리고 Lambda 함수를 생성합니다. ObjectCreated의 S3 버킷에 대한 Lambda 함수에 트리거를 추가합니다. 람다 함수 소스 코드는 매우 간단합니다. 코드를 변경하지 않으면 JAR에 aws-xray-sdk 및 aws-xray-sdk-recorder-aws-sdk-instrumentor 패키지를 포함시켜 Java 기능에서 X-Ray를 사용할 수 있습니다.
자 이제 사진 업로드를 해서 X-Ray 추적 상황을 살펴봅니다.

우리는 이러한 개별 추적 데이터 중 하나를 클릭하여 호출에 대한 자세한 정보를 얻을 수 있습니다.

AWS::Lambda 세그먼트에서 함수의 대기 시간, 실행 대기 시간, 실행 시도 횟수를 볼 수 있습니다.
AWS::Lambda::Function 세그먼트에는 몇 가지 가능한 하위 세그먼트가 있습니다.
- The inititlization subsegment includes all of the time spent before your function handler starts executing
- The outbound service calls
- Any of your custom subsegments (these are really easy to add)
DynamoDB에 약간의 문제가 있는 것처럼 보입니다. 오류 아이콘을 클릭하면, 전체 예외 스택 트레이스를 얻을 수 있습니다. 테이블 용량이 부족하기 때문에 DynamoDB를 조정해야 합니다. 단 몇 번의 클릭 또는 빠른 API 호출로 더 많은 정보를 얻을 수 있습니다.

X-Ray SDK를 사용하면 X-Ray로 데이터를 쉽게 내보낼 수 있습니다. 파이썬의 경우, 이 라이브러리를 fleece라는 rackspace에서 가져올 수 있습니다. 더 자세한 사항은 기술 문서를 참고하시기 바랍니다.
– Randall;
AWS Step Functions 및 Amazon API Gateway 연동을 통한 서버리스 기반 승인 기능 구현하기
AWS Step Functions을 사용하는 가장 일반적인 사례는 프로그램 중에 사람이 개입해서 뭔가 승인해야 할 때입니다 (예: 회원 가입 시 이메일 승인 프로세스). Step Functions을 사용하면 상태 머신 이라고 하는 시각적 워크플로에서 일련의 단계별 분산 응용 프로그램 구성 요소를 쉽게 조정할 수 있습니다. 상태 머신을 신속하게 빌드 및 실행하여 응용 프로그램 단계를 안정적이고 확장성 높은 방식으로 실행할 수 있습니다.
이 글에서는 수동 승인 단계를 구현하기 위한 서버리스 디자인 패턴을 설명합니다. Step Functions 활동 작업(Activity Task)를 사용하여 나중에 결정을 내린 사람이 승인 또는 거부를 알려주는 고유한 토큰을 생성 및 반환할 수 있습니다.
기능 구현 단계 소개
Step Functions 상태 머신이 활동 작업 상태로 실행 되면, Step Functions은 활동(Activity)을 스케줄하고 활동 작업자(Activity Woker)를 기다립니다. 활동 작업자는 GetActivityTask를 호출하여 활동 작업을 가져오는 응용 프로그램 입니다. 작업자가 API 작업을 성공적으로 호출하면, 해당 작업자는 콜백 토큰을 포함하는 JSON blob로 작업을 보냅니다.
이 시점에서 상태를 포함한 실행 작업 상태 및 실행 분기가 일시 중지됩니다. 상태 머신에 타임아웃이 지정되어 있지 않으면, 활동 작업 상태는 활동 작업자가 vended 토큰을 사용하여 SendTaskSuccess 또는 SendTaskFailure를 호출 할 때까지 대기합니다. 이러한 일시 중지 기능이 수동 승인 단계를 구현하는 첫 번째 열쇠입니다.
두 번째 열쇠는 서버리스 환경에서 작업을 가져 오는 코드를 분리하고, 토큰을 공유 할 수 있는 한 완료 상태로 응답하고 토큰을 되돌려 보내는 코드에서 토큰을 가져 오는 기능입니다. 여기서 작업자는 단일 활동 작업 상태에 의해 관리되는 서버리스 응용 프로그램입니다.
이를 통해 일정에 따라 호출된 AWS Lambda 함수를 사용하여 활동 작업자를 구현합니다. 이 작업자는 승인 단계와 관련된 토큰을 획득하고, Amazon SES를 사용하여 승인자에게 이메일을 보냅니다.
직접 토큰을 리턴하는 응용 프로그램에서 Step Functions의 SendTaskSuccess 및 SendTaskFailure API를 직접 호출 할 수 있기 때문에 매우 편리합니다. 이메일 클라이언트 또는 웹 브라우저가 토큰을 단계 기능으로 반환 할 수 있도록 Amazon API Gateway를 통해 이러한 두 가지 작업을 제공 하면, 보다 쉽게 작업을 수행 할 수 있습니다. 토큰을 가져 오는 람다 함수와 API 게이트웨이를 통해 토큰을 반환하는 응용 프로그램을 결합하여 서버리스 수동 승인 단계를 구현할 수 있습니다 (아래 그림 참조).
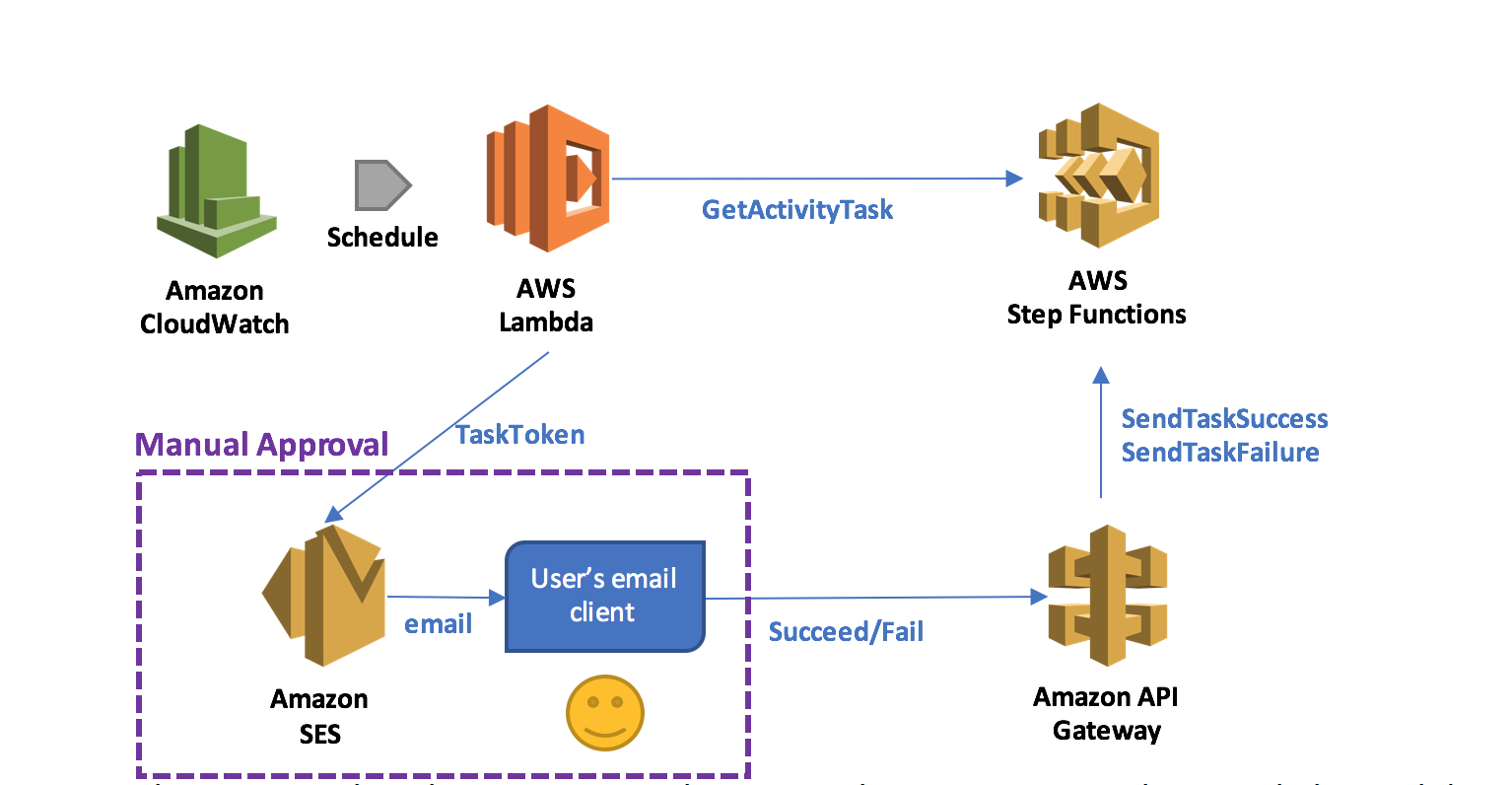
수동 승인이 필요한 상태가 되면, Lambda 함수는 승인 및 거부를 위해 두 개의 하이퍼링크가 포함 된 전자 메일을 준비하여 사용자에게 보냅니다.
권한이 부여 된 사용자가 승인(approval) 하이퍼 링크를 클릭하면 상태가 성공합니다. 사용자가 거절(reject) 링크를 클릭하면 상태가 실패합니다. 또한, 승인에 대한 시간 제한을 설정하도록 선택할 수 있으며, 제한 시간이 지나면 활동 작업 상태에서 재시도/처리 조건을 사용하여 이메일 요청을 재전송 하는 등의 조치를 취할 수 있습니다.
사례: 직원 승진 프로세스 승인
본 서버리스 애플리케이션 패턴의 하나로 이메일을 통해 관리자의 승인을 받는 것과 같은 기능을 포함하는 직원 승진 프로세스를 설계할 수 있습니다. 직원이 승진 후보로 정해되면, 새로운 Step Functions 실행이 시작됩니다. 직원의 이름과 직원 매니저 이메일 주소를 최초 제공합니다.
본 디자인 패턴을 사용하여 수동 승인 단계를 구현하고, SES를 사용하여 이메일을 관리자에게 보냅니다. 태스크 토큰을 획득 한 후, Lambda 함수는 API 게이트웨이가 제공하는 URI에 대한 하이퍼 링크가 포함 된 전자 메일을 생성하여 관리자에게 전송합니다.
본 사례에서는 IAM 역할을 만들 수 있도록 계정 관리 권한이 필요합니다. 또한, SES에 이메일 주소를 이미 등록 했으므로 주소가 보낸 사람/받는 사람으로 이메일을 보낼 수 있습니다. 자세한 정보는 Amazon SES로 전자 메일 보내기를 참조하십시오.
아래와 같은 단계로 서버리스 애플리케이션을 구현해 보겠습니다.
- 활동(Activity) 만들기
- 상태 머신(State Machine) 만들기
- API 생성 및 배포
- 활동 작업자 람다 함수 만들기
- 프로세스 테스트
단계 1: 활동 만들기
Step Functions 콘솔에서 Task를 선택하고, ManualStep이라는 활동을 작성하십시오.

본 활동의 ARN을 저장해 두시기 바랍니다. (나중에 사용 예정)

단계 2. 상태 머신 만들기
Step Functions 콘솔에서 승진 프로세스를 모델링하는 상태 머신을 만듭니다. 콘솔에서 기본 생성된 IAM 역할 인 StatesExecutionRole-us-east-1을 사용합니다. 상태 머신의 이름에 PromotionApproval를 지정하고 다음 코드를 사용합니다. Resource의 값을 위의 활동 ARN으로 바꾸십시오.
{
"Comment": "Employee promotion process!",
"StartAt": "ManualApproval",
"States": {
"ManualApproval": {
"Type": "Task",
"Resource": "arn:aws:states:us-east-1:ACCOUNT_ID:activity:ManualStep",
"TimeoutSeconds": 3600,
"End": true
}
}
}단계 3. API 생성 및 배포
API 게이트웨이를 사용하여 SendTaskSuccess 또는 SendTaskFailure API 작업을 호출하기 위한 공용 URI를 만들고 배포합니다.
먼저, IAM 콘솔로 이동하여 API 게이트웨이가 Step Functions을 호출하는 데 사용할 수 있는 IAM 역할을 만듭니다. 역할 이름을 APIGatewayToStepFunctions로 지정하고 역할 유형으로 Amazon API 게이트웨이 를 선택한 다음 역할을 만듭니다.
IAM 역할을 만든 후, AWSStepFunctionsFullAccess 관리 정책을 추가하십시오.

API 게이트웨이 콘솔에서 StepFunctionsAPI라는 새 API를 만듭니다. 성공(success) 및 실패(fail)이라는 루트 (/) 아래에 두 개의 새 리소스를 만들고 각 리소스에 대해 GET 메서드를 만듭니다.

이제 각 메소드를 구성해야합니다. /fail GET 메소드를 선택하고, 다음 빙식으로 구성하십시오.
- Integration type: AWS Service 선택
- AWS Service: Step Functions 선택
- HTTP method: POST 선택
- Region: 여러분이 원하는 리전을 선택합니다. (참고. 아직 Step Functions이 지원되는 리전은 AWS Region Table에서 참고하세요.)
- Action Type: SendTaskFailure 추가
- Execution: APIGatewayToStepFunctions 역할의 ARN 값 입력

URI를 통해 taskToken을 전달하려면 Method Request 섹션으로 이동하고 taskToken 이라는 URL Query String 매개 변수를 추가하십시오.

Integration Request 섹션으로 이동하여 application/json 유형의 Body Mapping Template을 추가하여 쿼리 문자열 매개 변수를 요청 본문에 삽입합니다. 보안 경고에서 제안한 변경 사항을 허용합니다. When there are no templates defined (Recommended) 본문 패스 동작을 설정합니다. 아래 코드는 이러한 매핑을 수행합니다.
{
"cause": "Reject link was clicked.",
"error": "Rejected",
"taskToken": "$input.params('taskToken')"
}그런 다음, Save을 눌러 저장합니다.
다음에는 /success GET 메서드를 구성합니다. 구성은 /fail GET 메소드와 매우 유사합니다. 유일한 차이점은 Action입니다. SendTaskSuccess를 선택하고 다음과 같이 매핑을 설정하십시오.
{
"output": "\"Approve link was clicked.\"",
"taskToken": "$input.params('taskToken')"
}API 작업을 구성한 후 API 게이트웨이 콘솔의 마지막 단계는 respond 이라고하는 새로운 단계에 API 작업을 배포하는 것입니다. GET 메소드 중 하나에서 Invoke URL 링크를 선택하여 API를 테스트 할 수 있습니다. 토큰이 URI에 제공되지 않으므로 ValidationException 메시지가 표시되어야 합니다.

단계 4: 활동 작업자를 위한 Lambda 함수 만들기
Lambda 콘솔에서 Node.js 4.3 런타임에 대한 신규 템플릿을 활용하여 CloudWatch Events Schedule 트리거로 람다 함수를 만듭니다. Schedule expression에 입력하는 값은 활동 비율입니다. 이것은 활동 진행 시간이 계획되는 비율보다 커야합니다.
안전 마진(safety margin)은 활동이 계획되지 않은 동안 발생하는 토큰 손실, 재시도 활동 등을 설명합니다. 예를 들어, 승진 액션이 3 번이 발생할 것으로 예상되는 경우, 특정 한 주 동안 하루에 네 번 람다 함수를 실행하도록 예약 할 수 있습니다. 또는, 단일 람다 함수가 여러 활동을 병렬 또는 직렬로 실행될 수 있습니다. 이 때는 분당 1 회의 속도를 사용하지만 트리거는 아직 사용하지 않도록 설정합니다.

이제 Node.js 4.3 코드를 사용하여 Lambda 함수 ManualStepActivityWorker를 만듭니다. 이 함수는 StepTunction에서 taskToken, employee 이름 및 manager 이메일 정보를 수신합니다. 이들 정보를 이메일에 포함시키고 이메일을 관리자에게 보냅니다.
'use strict';
console.log('Loading function');
const aws = require('aws-sdk');
const stepfunctions = new aws.StepFunctions();
const ses = new aws.SES();
exports.handler = (event, context, callback) => {
var taskParams = {
activityArn: 'arn:aws:states:us-east-1:ACCOUNT_ID:activity:ManualStep'
};
stepfunctions.getActivityTask(taskParams, function(err, data) {
if (err) {
console.log(err, err.stack);
context.fail('An error occured while calling getActivityTask.');
} else {
if (data === null) {
// No activities scheduled
context.succeed('No activities received after 60 seconds.');
} else {
var input = JSON.parse(data.input);
var emailParams = {
Destination: {
ToAddresses: [
input.managerEmailAddress
]
},
Message: {
Subject: {
Data: 'Your Approval Needed for Promotion!',
Charset: 'UTF-8'
},
Body: {
Html: {
Data: 'Hi!<br />' +
input.employeeName + ' has been nominated for promotion!<br />' +
'Can you please approve:<br />' +
'https://API_DEPLOYMENT_ID.execute-api.us-east-1.amazonaws.com/respond/succeed?taskToken=' + encodeURIComponent(data.taskToken) + '<br />' +
'Or reject:<br />' +
'https://API_DEPLOYMENT_ID.execute-api.us-east-1.amazonaws.com/respond/fail?taskToken=' + encodeURIComponent(data.taskToken),
Charset: 'UTF-8'
}
}
},
Source: input.managerEmailAddress,
ReplyToAddresses: [
input.managerEmailAddress
]
};
ses.sendEmail(emailParams, function (err, data) {
if (err) {
console.log(err, err.stack);
context.fail('Internal Error: The email could not be sent.');
} else {
console.log(data);
context.succeed('The email was successfully sent.');
}
});
}
}
});
};이제 Lambda function handler and role 항목에서 Role에 대해서는 Create a new role을 선택하고 LambdaManualStepActivityWorkerRole를 생성합니다.

IAM 역할에 두 개의 정책을 추가합니다. 하나는 Lambda 함수가 Step Functions를 호출하여 GetActivityTask API 조치를 호출하고 SES를 호출하여 이메일을 보내도록 허용하는 것입니다. 결과는 다음과 같습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": "states:GetActivityTask",
"Resource": "arn:aws:states:*:*:activity:ManualStep"
},
{
"Effect": "Allow",
"Action": "ses:SendEmail",
"Resource": "*"
}
]
}또한, GetActivityTask API 동작이 60 초 제한 시간으로 롱 폴링(long-polling)을 수행하므로 람다 기능의 제한 시간을 1 분 15 초로 늘립니다. 이를 통해 함수가 활동이 사용 가능하게 될 때까지 기다릴 수 있으며, SES에 이메일을 보내도록 여분의 시간을 제공합니다. 다른 모든 설정의 경우 람다 콘솔 기본값을 사용하십시오.

그런 다음, 액티비티 작업자 람다 함수를 생성 할 수 있습니다.
단계5: 프로세스 테스트 하기
이제 직원 승직 프로세스를 테스트 할 준비가되었습니다.
람다 콘솔에서 ManualStepActivityWorker 람다 함수에서 ManualStepPollSchedule 트리거를 활성화하십시오.
Step Functions 콘솔에서 아래 입력 값을 사용하여 상태 시스템을 새로 시작하십시오.
{ "managerEmailAddress": "name@your-email-address.com", "employeeName" : "Jim" } 잠시 후 Jim의 프로모션을 승인하거나 거부하는 링크가 포함 된 이메일을 받아야 합니다. 링크 중 하나를 선택하면 실행이 성공하거나 실패합니다.

이 글에서는 AWS Step Functions의 활동 작업, API 게이트웨이가 있는 API 및 승인/실패 프로세스를 전달하는 AWS Lambda 함수가 포함 된 상태 머신을 만들었습니다. 본 디자인 패턴을 사용하여 수동 승인 단계를 구현할 수 있습니다.
질문이나 제안이 있으시면 아래에 의견을 남겨주십시오.

Ali Baghani, Software Development Engineer
이 글은 Implementing Serverless Manual Approval Steps in AWS Step Functions and Amazon API Gateway의 한국어 번역입니다.
AWS Step Functions– 시각적 워크플로 기반 분산 애플리케이션 개발용 신규 서비스
오늘 날 다양한 웹 기반 마이크로 서비스를 연결하여 복잡한 분산 응용 프로그램을 보다 쉽게 만들 수 있어야 합니다. 대부분 개발자는 복잡한 비즈니스 프로세스를 구현하든 간단한 사진 업로드를 위한 처리를 하던지 가급적 관리 작업 보다는 코드 개발에 집중하고, 익숙한 개발 도구와 라이브러리를 사용하면서 견고하고 확장성 높은 비용 효율적인 안정적 응용 프로그램을 구축하기를 바라고 있습니다.
AWS Step Functions 소개
위의 요구 사항에 부합하는 AWS Step Functions을 오늘 출시합니다. 여러분이 만든 애플리케이션의 구성을 시각적 워크플로를 통해 설정하고, Step Functions 콘솔에서 각 머신(machine)에서 높은 확장성으로 진행하는 과정을 정의해 줄 수 있습니다.
각 머신은 상태 세트를 정의하고 이들 사이의 그 상태 값을 이전합니다. 각 단계별 상태는 병렬 혹은 순서대로 활성화 될 수 있습니다. Step Functions에서는 다음 단계로 가기 전에 모든 병렬적인 상태가 완료되도록 합니다. 이들 상태를 기반으로 작업 및 의사 결정 및 컴퓨터를 통한 과정 제어 등을 수행합니다.
아래에는 상태 머신(state machine)에 대한 일부분을 표시한 것입니다.
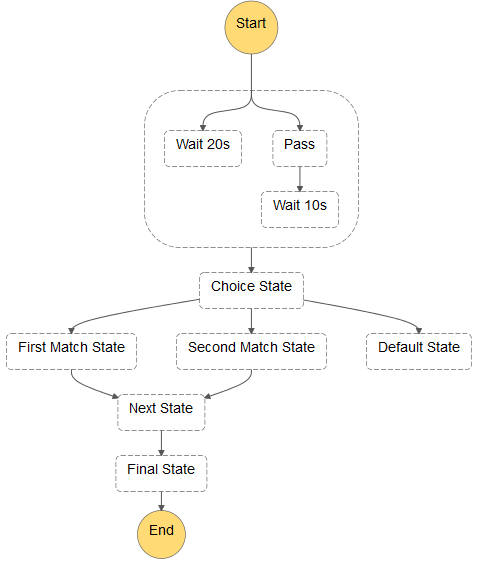
각 상태 머신의 여러 복제본은 동시에 독립적으로 실행할 수 있습니다. 각 복제본은 실행물(execution)이라고 부릅니다. Step Functions는 수 천개의 실행물을 동시에 실행할 수 있도록 하여 원하는 수준의 확장성을 제공합니다.
어떤 상태가 실행될 때 수행할 작업을 지정하는 데는 두 가지 다른 방법이 있습니다. 먼저, 상태가 실행될 때 동기적으로 호출 될 Lambda 함수를 제공 할 수 있습니다. 둘째, 액티비티(Activity) 이름을 제공할 수 있습니다. 이것은 수행할 작업에 대해(API를 통해) 가져올 장기적인 실행 작업 함수에 대한 참조값입니다. 어느 쪽이든, 코드는 JSON 입력을 통해 JSON 출력을 반환 받습니다.
상태 시스템의 일부로서 오류 처리 동작을 지정하고 로직를 다시 시도 할 수 있습니다. 따라서, 코드 한 부분에서 일시적인 문제로 인해 일시적인 오류가 발생하더라도 원활하게 실행되는 강력한 다중 단계 앱을 만들 수 있습니다.
Step Function 살펴 보기
AWS 관리 콘솔에 들어가 상태 시스템을 설정해 보겠습니다. 정식 애플리케이션은 AWS 단계 함수 API (아래에서 설명)를 사용하여 상태 시스템을 생성하고 실행합니다.
우선 간단한 AWS Lambda 함수를 작성해 보겠습니다.
함수의 ARN 값을 복사합니다.
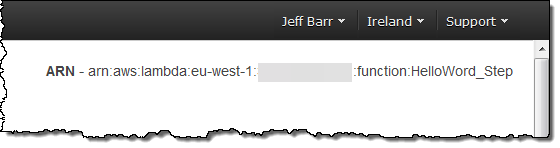
이제 AWS Step Functions 콘솔로 가서 Create a State Machine을 누르고, 이름(MyStateMachine)과 함께 실행할 기본 샘플 워크 플로를 선택합니다.
Hello World를 클릭하고, 상태 머신에 대한 JSON 모델을 만들기 위해 Parallel 요소를 선택합니다.
{
"Comment": "A simple example of the Steps language using an AWS Lambda Function",
"StartAt": "Hello",
"States": {
"Hello": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:99999999999:function:HelloWord_Step",
"Next": "Parallel"
},
"Parallel": {
"Type": "Parallel",
"Next": "Goodbye",
"Branches": [
{
"StartAt": "p1",
"States": {
"p1": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:9999999999:function:HelloWord_Step",
"End": true
}
}
},
{
"StartAt": "p2",
"States": {
"p2": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:99999999999:function:HelloWord_Step",
"End": true
}
}
}
]
},
"Goodbye": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:99999999999:function:HelloWord_Step",
"End": true
}
}
}Preview 를 누르면 아래와 같이 시각적으로 보입니다.
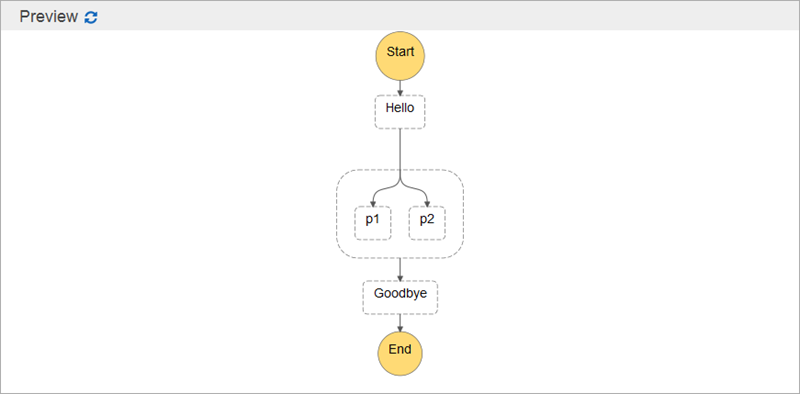
Step Functions을 실행할 IAM 역할을 지정합니다.
이제 모든 설정을 마치고, 상태 머신을 실행할 수 있습니다. 첫번째 함수를 통과하는 JSON 블럭을 가지고 시작해 볼 수 있습니다.
Start Execution을 누르자 마자 상태 머신이 실행되고, 실행 순서에 따라 아래와 같이 상태와 상태 사이의 전이가 일어납니다.
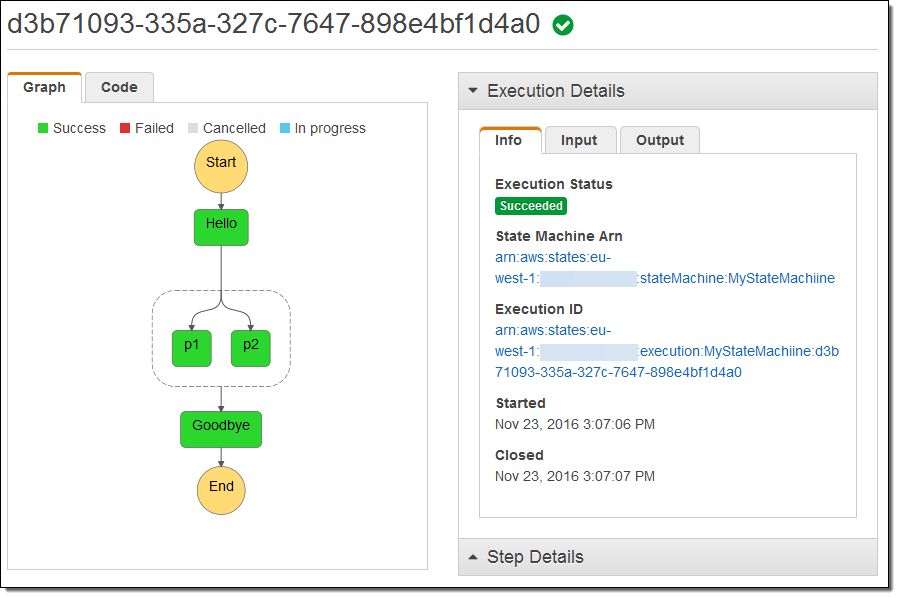
Lambda 콘솔에 가면, 아래와 같이 4번의 함수 실행을 볼 수 있습니다. (시간이 촉박하면, 네 개의 기능을 따로 만들지 않아도 됩니다.)
Step Functions는 각 단계별로 정보를 모두 기록하고 이를 콘솔에서 볼 수 있습니다.
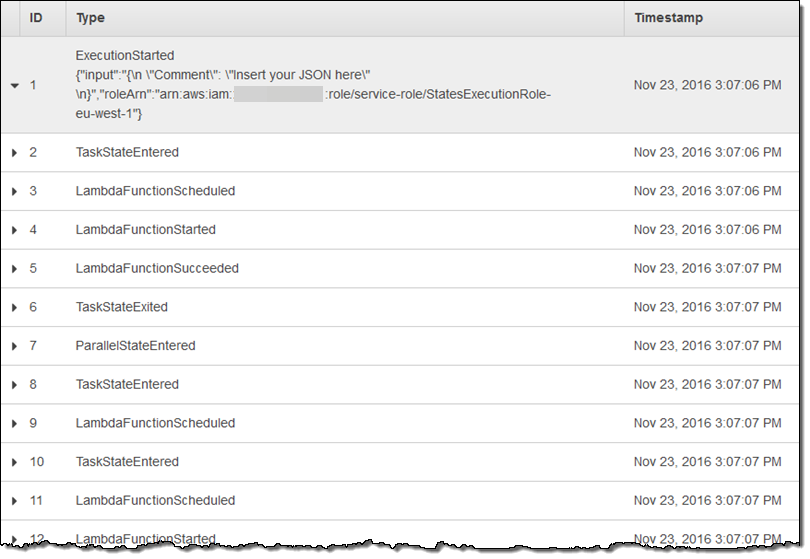
AWS Step Functions API
앞에서 말씀 드린 대로, AWS Step Funcitons는 API로 실행 가능하며, 아래에 주요 기능에 대한 API 함수 입니다.
CreateStateMachine– JSON을 통해 신규 상태 머신 생성ListStateMachines– 상태 머신 목록 가져오기StartExecution– 상태 머신 (비동기적으로) 실행하기DescribeExecution– 실행물 정보 가져오기GetActivityTask– 실행할 신규 작업 가져오기
새 객체가 S3 버킷에 업로드 될 때마다 Lambda 함수를 실행할 수 있습니다. 이 함수는 StartExecution을 호출하여 상태 머신 실행을 시작할 수 있습니다. 상태 머신은 (예를 들어) 이미지 유효성 검사, 다양한 크기 및 형식 병렬 생성, 특정 유형의 콘텐트 확인 및 데이터베이스 항목 업데이트를 수행 할 수 있습니다.
동일한 기능을 AWS CLI에서도 사용할 수 있습니다.
개발 도구
신규 statelint gem 파일을 사용하여 연결할 수 없는 상태, 터미널 상태 누락과 같은 일반적인 오류에 대해 수기 혹은 컴퓨터에서 생성된 JSON 로그를 확인할 수 있습니다.
AWS GitHub 레포지터리에서 다운로드하십시오 (RubyGems) 다음과 같이 설치하십시오.
$ sudo gem install j2119-0.1.0.gem statelint-0.1.0.gemHere’s what happens if you have a problem:
$ statelint my_state.json
2 errors:
State Machine.States.Goodbye does not have required field "Next"
No terminal state found in machine at State Machine.States
잘 진행이 된다면,
$ statelint my_state.json
정식 출시
AWS Step Functions는 오늘 부터 US East (Northern Virginia), US East (Ohio), US West (Oregon), EU (Ireland), Asia Pacific (Tokyo) 리전에서 사용 가능합니다.
AWS 프리티어를 통해 매월 4,000 번의 상태 전이를 수행할 수 있습니다. 그 이후로는 1,000회당 $0.025의 요금을 부가합니다.
— Jeff;
AWS Lambda@Edge – 미리 보기 출시
지난 주에 한 AWS 고객으로 부터 Hacker News에 올린 댓글을 통해 한 통의 메일을 받았습니다.
그는 싱글 페이지 애플리케이션(SPA)을 빠른 속도의 웹 페이지 배포가 가능한 Amazon CloudFront를 통해 Amazon S3에 정적 웹 호스팅으로 서비스를 하고 있는데, 그 페이지에서 AWS Elastic Beanstalk에서 운용중인 자체 API를 통해 개별 사용자를 위한 동적인 작업을 진행하고 있다고 합니다. 그 분이 설명한 문제는 다음과 같습니다.
최근의 웹 환경에서는 검색 엔진을 위해 별도 색인을 생성하고 Facebook 및 Twitter 내에서 콘텐츠 미리보기가 올바르게 표시 되려면 각 페이지의 미리 렌더링 된 버전을 제공해야 합니다. 이를 위해서는 사용자가 Google 사이트를 방문 할 때마다 Cloudfront의 프론트엔드에 서비스를 제공해야 합니다. 그러나 사용자 에이전트가 Google/Facebook/Twitter 인 경우 미리 렌더링된 사이트 버전으로 리디렉션을 해야합니다.
한 명의 고객이 보내준 사용 사례를 넘기지 않고, 우리가 앞으로 이러한 문제를 개선하겠다는 사실을 알려주었습니다. 여러 고객들이 이미 엣지에서 신속하게 의사 결정을 내림으로써 맞춤형 최종 사용자 경험을 제공하고자 하는 의견을 주었습니다.
(레이턴시 기준) 고객에게 가까이 있는 위치에서 HTTP 요청을 “지능적으로” 처리하는 데는 많은 주목할만한 사용 사례가 있습니다. 예를 들어, HTTP 헤더 검사, 접근 제어 (특정 쿠키가 필요함), 모바일 디바이스 탐지, A/B 테스트, 크롤러 또는 봇에 대한 신속한 처리 또는 특수한 별도 처리, 레거시 시스템을 수용 할 수 있는 사용자 친화적인 URL 리다이렉트 등입니다. 이런 요구 사항 대부분은 단순한 패턴 일치 및 규칙으로 표현할 수 있는 것보다 좀 더 복잡한 처리 및 의사 결정을 필요로합니다.
AWS Lambda@Edge 서비스 소개
이러한 요구 사항을 지원하기 위해 AWS Lambda@Edge 미리 보기를 시작합니다. 이 새로운 람다 기반 처리 모델을 사용하면, 전 세계에 산재하는 AWS 엣지 로케이션에서 JavaScript 코드를 작성하여 실행할 수 있습니다.
이제는 가벼운 요청 처리 로직을 작성하고 CloudFront 배포판을 통과하는 요청(request) 및 응답(response)을 처리 할 수 있습니다. 아래와 같이 네 가지 별개의 이벤트에 대한 응답으로 코드를 실행할 수 있습니다.
Viewer Request – 콘텐츠 캐시 여부에 관계없이 모든 요청에 대해 코드가 실행됩니다. 다음은 간단한 헤더 처리 코드입니다.
exports.viewer_request_handler = function(event, context) {
var headers = event.Records[0].cf.request.headers;
for (var header in headers) {
headers["X-".concat(header)] = headers[header];
}
context.succeed(event.Records[0].cf.request);
}Origin Request – Your code will run when the requested content is not cached at the edge, before the request is passed along to the origin. You can add more headers, modify existing ones, or modify the URL.
Viewer Response – 캐시 여부와 관계없이 모든 응답에서 실행됩니다. 이것을 사용하여 브라우저로 다시 전달할 필요가 없는 일부 헤더를 정리할 수 있습니다.
Origin Response – 캐시 실패로 인해 원본(Origin)에서 다시 가져와서 엣지(Edge)에 반응한 후 코드를 실행합니다.
개별 코드는 URL, 메소드, HTTP 버전, 클라이언트 IP 주소 및 헤더 등 HTTP 요청 및 응답에서 나오는 여러 데이터를 접근할 수 있습니다. 간단하게 헤더를 추가, 수정 및 삭제할 수도 있고, HTTP 바디(Body)를 포함한 모든 값을 변경할 수 있습니다. 처음에는 헤더를 추가, 삭제 및 수정할 수 있습니다. 곧 바디를 포함한 모든 값에 대한 읽기 / 쓰기 접근 권한을 갖게됩니다.
자바 스크립트 코드는 HTTP 호출/응답의 한 부분이 되기 때문에 재빠르고 의미 있는 스스로 완결적인 코드여야 합니다. 다른 웹 서비스를 호출 할 수 없으며, 다른 AWS 리소스에 접근할 수 없습니다. 128MB의 메모리 내에서 실행되어야 하며 50ms 이내에 실행이 끝나야 합니다.
처음 시작을 해보려면, 새로운 람다 함수를 생성하고, CloudFront 배포를 트리거로 설정한 후 새 Edge 런타임을 선택하면됩니다.

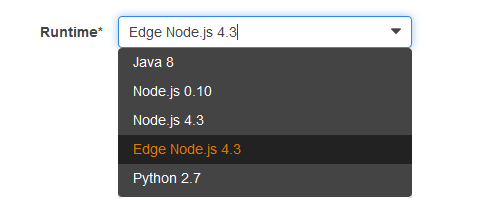
그런 다음, 코드를 만들면 됩니다. Lambda 함수는 엣지 로케이션의 여러 가지 측면을 개선하는데 도움을 줄 것입니다.
미리 보기 신청하기
이 기능이 새로운 애플리케이션 및 개발 도구로서 창의적인 적용을 해 볼 수 있을 것으로 생각하고, 여러분이 직접 해 보시기를 권해 드립니다.
오늘 AWS Lambda@Edge 미리 보기를 시작하였고, 직접 해보시려면 미리 보기 신청 페이지에서 등록해 주시기 바랍니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS Lambda@Edge – Preview의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
AWS Snowball Edge – 클러스터링 및 용량 추가, 로컬 엔드포인트와 Lambda 함수 지원
작년에 AWS Snowball을 출시(블로그 참고) 한 뒤, 많은 업데이트가 있었습니다. 물리적 50TB 데이터 전송 저장 장치로 보안 및 운송의 편리성을 통한 클라우드 데이터 이동에 대한 아주 간단한 해법으로서 그 이후에도, 용량 확대 및 리전 추가 지원 (80 TB), 작업 관리 API 및 S3 어댑터, HIPAA 호환, HDFS 가져오기 지원 등의 업데이트가 이루어졌습니다.
위의 모든 개선 사항 역시 중요했지만, 제품 기본 특성은 변경하지 않았습니다. 지난 1년간 많은 AWS 고객이 Snowball을 활용하여 다양한 유형의 대용량 데이터 이전, 유전학 데이터 수집 작업 등에서 물리적 환경에 필요한 다양한 작업을 진행하였습니다. 그 와중에 좀 더 기능적으로 필요한 몇 가지 여지가 있음을 알게 되었습니다.
어떤 고객은 네트워크 연결이 제한적이거나 아예 존재하지 않는 극단적인 상황에서도 많은 양의 데이터 (수백 테라 바이트)를 생성하기도 합니다. 예를 들어, 농장, 공장, 병원, 항공기 및 석유 시추 위치에서 생성하는 데이터를 수집할 필요가 있습니다. 각 작업 현장 측정 위치에서 비디오 감시, IoT 장치로 수집 된 정보에 이르기까지 고객은 개별 데이터 저장 및 수집에 넘어서서 데이터가 도착할 때 일부 로컬 처리를 수행 가능한 모델에 관심이 있습니다. 수집한 데이터를 필터링, 정리, 분석, 구성, 추적, 요약 및 모니터링하여, 특정 패턴이나 이슈에 대해 들어오는 데이터를 검색하여, 흥미로운 것이 발견되면 신속하게 경고를 하는 경우가 있습니다.
신규 Snowball Edge 디바이스
 오늘 Snowball Edge라는 새로운 저장 장치를 추가로 제공합니다. 이 장치는 기존 Snowball 기능에 더해 연결성, 스토리지, 클러스터링을 통한 수평적 확장, 기존 S3 및 NFS 클라이언트, Lambda 기반 처리를 통한 신규 스토리지 엔드포인트 지원이 가능합니다.
오늘 Snowball Edge라는 새로운 저장 장치를 추가로 제공합니다. 이 장치는 기존 Snowball 기능에 더해 연결성, 스토리지, 클러스터링을 통한 수평적 확장, 기존 S3 및 NFS 클라이언트, Lambda 기반 처리를 통한 신규 스토리지 엔드포인트 지원이 가능합니다.
물리적으로 Snowball Edge는 집에서 부터 아주 열악한 환경인 농장, 군대 및 항공 분야에서도 사용 가능합니다. 새로운 랙 마운트 장착용으로 클러스터 기능이 있는 것이 장점입니다.
몇 가지 새로운 기능을 살펴 보겠습니다.
연결성 확대
다양한 고속 네트워크 연결에 대한 선택 사항이 높아졌습니다. 10GBase-T, 10 또는 25 Gb SFP28, 또는 40 Gb QSFP+를 사용 가능합니다. IoT 기기가 데이터 업로드를 할 수 있도록 3G 모바일 혹은 Wi-Fi를 지원합니다 또한, 기타 IoT 기기를 위한 Zigbee, USB 3.0 포트, PCIe 확장 포트 등 다양한 접속 방법도 지원 합니다.
Snowball Edge에 데이터를 복사 할 수 있는 대역폭은 초당 최대 14Gb까지 확보 할 수 있습니다. 따라서, 19 시간 내에 100TB를 복사 할 수 있습니다. 시작부터 끝까지 (S3에서 사용 가능한 데이터로 전송 시작) 전체 과정은 배송 및 처리 과정을 포함하여 일주일이 소요됩니다.
스토리지 용량 확대
Snowball Edge는 100 TB 스토리지를 포함합니다.
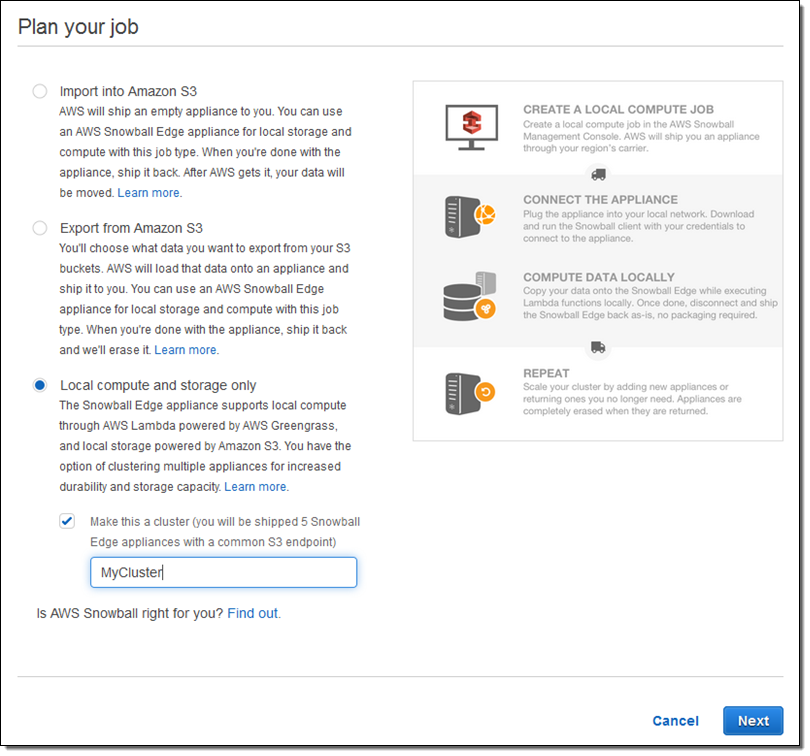
클러스터링을 통한 수평적 확장 기능Snowball Edge 어플라이언스 두 개 이상을 클러스터로 쉽게 구성하여 용량을 늘리고 내구성을 높이는 동시에 모든 스토리지에 단일 엔드 포인트를 통해 접근할 수 있습니다. 예를 들어, 6개의 기기를 클러스터링을 하면 400TB의 스토리지와 99.999%의 내구성을 갖춘 고가용성 클러스터를 생성합니다. 이를 통해 2개의 기기를 제외하고 데이터 보호를 할 수 있습니다.
클러스터링을 통해 페타 바이트 단위로 용량을 확장 할 수 있으며, 손쉽게 클러스터에서 기기 추가 및 제거가 가능합니다. 클러스터는 자체 관리가 가능하므로 소프트웨어 업데이트 등에 대해 걱정할 필요가 없습니다.
Local compute and storage only를 체크하여 클러스터를 주문하고, Make this a cluster를 통해 작업을 설정하시면 됩니다.
신규 스토리지 엔드 포인트 (S3 및 NFS)
기존 데이터 백업 및 아키이빙, 데이터 전송을 위해 S3나 NFS를 사용하여 Snowball Edge를 활용할 수 있습니다. 2개 이상의 기기로 클러스터를 만들어도, 같은 엔드 포인트를 사용 가능합니다. 클러스터를 로컬 네트워크 저장 장치로 사용할 수 있습니다.
Snowball Edge 는 S3 API, 즉 LIST, GET, PUT, DELETE, HEAD, Multipart Upload 등을 지원 하며, NFS v3 및 NFS 4.1. 역시 지원합니다.
Snowball Edge를 파일 스토리지 게이트웨이로 만들어 NFS로 접근 가능합니다. 이러한 기능을 활용하여 데이터 이전, AWS Storage Gateway 연동, 온-프레미스 앱에서 온-프레미스 데이터를 처리 가능합니다.
Lambda 기반 로컬 작업 지원
AWS Lambda 함수를 사용하여 Snowball Edge를 S3 버킷으로 연계해서 업로드가 가능합니다.
본 기능을 통해 (앞서 언급한 대로) 수집한 데이터를 필터링, 정리, 분석, 구성, 추적, 요약 및 모니터링하여, Snowball Edge를 좀 더 지능적이고 스마트하게 데이터 수집 및 처리를 할 수 있도록 해줍니다
우선 S3 PUT 에 대해 버킷당 하나의 함수를 사용 가능합니다. 함수는 Python 언어로 작성해야 하고 128 MB 메모리로 람다 함수 실행 환경을 설정하면 됩니다.
아래와 같이 Snowball Edge 환경 설정에 람다 함수를 지정하면 됩니다.
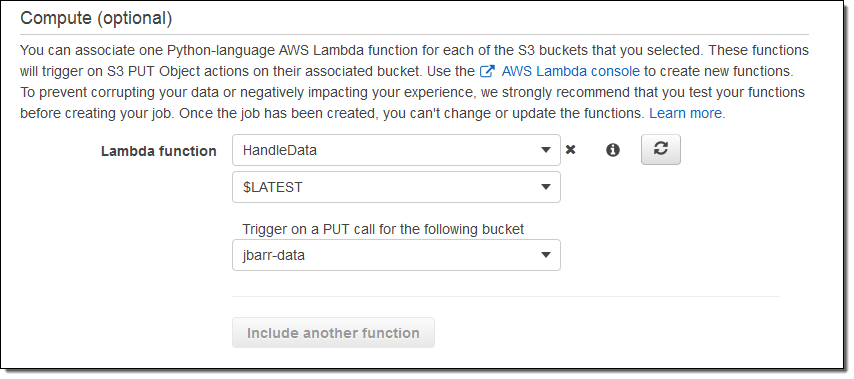
주문하기 전에 클라우드에서 기능을 테스트하는 것을 권장합니다.
정식 출시 및 가격 정보
Snowball Edge는 플러그앤 플레이 기반으로 배포합니다. 현장에서 이를 다루는 분은 설정을 할 필요는 없으며, LCD 보드를 통해 상태 정보나 설정 동영상을 볼 수 있습니다. 보드 상에 설정 코드는 자동으로 업데이트되고 소프트웨어 업데이트 관리도 필요 없습니다. AWS 관리 콘솔 (API 또는 CLI 접근 가능)을 통해 상태를 확인하고 배치 된 장비에 대한 최신 구성 변경 사항을 작성할 수 있습니다.
각 Snowball Edge은 배송료 포함 $300 입니다. 10일까지 장비를 사용할 수 있으며, 그 이후로는 일 $30이 추가됩니다. 로컬에서 Lambda 함수 실행은 무료입니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS Snowball Edge – More Storage, Local Endpoints, Lambda Functions의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
AWS Greengrass – 유비쿼터스 및 실세계 컴퓨팅 서비스
데이터 센터나 사무실 안에서 컴퓨팅 작업이나 및 데이터 처리는 용이합니다. 기본적으로 양호한 네트워크 연결성과 지속적인 전력 공급을 기대할 수 있으며, 가능한 만큼 온 – 프레미스 또는 클라우드 기반 스토리지에 접근하여 컴퓨팅 성능을 활용할 수 있습니다. 하지만, 밖으로 나오면 상황이 매우 다릅니다. 네트워크 연결은 간헐적이거나 신뢰할 수 없으며, 속도와 확장면에서 제한적일 수 있습니다. 전원 공급은 저장 용량 및 컴퓨팅 성능을 제한 할 수 있습니다.
따라서, 현실에서 흥미롭고 잠재적으로 가치 있는 많은 데이터가 수집 및 처리하여, 지능형 서비스를 제공하는 것은 매우 중요합니다. 이러한 데이터는 자원 채굴 현장이나 병원이나 공장 또는 심지어 (Curiosity)가 있는 화성처럼) 다른 행성, 지구 표면 아래 몇 마일 떨어진 해저 등에서도 얻어야 할 수 있습니다.
지금까지 많은 고객은 AWS 클라우드의 서비스 규모와 성능을 활용하여, 이러한 열악한 조건에서 로컬 처리를 시도할 수 있도록 다양한 피드백을 주셨습니다. 먼저, 데이터를 측정, 감지 및 제어하는 시스템을 로컬에 구축합니다. 그런 다음, 클라우드와 유사한 로컬 환경에 데이터를 저장하고 로컬 내부에서 독립적으로 수행하도록 일단 구성을 합니다. 이런 작업을 위해서는 로컬 프로세싱 및 스토리지 자원을 구성하고 활용하는 동시에 특수 센서 및 주변 장치에 연결할 수 있어야 합니다.
AWS Greengrass 소개
AWS Greengrass라는 서비스는 AWS 프로그래밍 모델을 작고 단순한 필드 기반 장치로 확장하여 위에서 설명한 문제점을 해결할 수 있도록 설계되었습니다.

Greengrass는 AWS IoT 및 AWS Lambda를 기반으로 하며 다른 AWS 서비스에도 접근할 수 있습니다. 오프라인 작업을 위해 제작되었으며, 로컬에서 프로그래밍 구현을 단순하게 만들어 주게 됩니다. 현장에서 실행되는 프로그램 코드를 통해 데이터를 새로 수집, 필터링 및 집계한 후 장기적으로 저장하고, 추가 분석을 할 수 있도록 클라우드로 전송할 수 있습니다. 또한, 현장에서 실행되는 프로그램 코드는 클라우드에 대한 연결을 일시적으로 사용할 수 없는 경우에도 매우 신속하게 조치를 취할 수 있습니다.
고객이 소형 장치용 임베디드 시스템을 이미 개발 중인 경우, 최신 클라우드 기반의 개발 도구 및 워크 플로를 활용할 수 있습니다. 클라우드에서 코드를 작성하고 테스트 한 다음, 로컬에서 배포 할 수 있습니다. 디바이스 이벤트에 응답하는 Python 코드를 작성할 수 있으며 MQTT 기반 pub/sub 메시징을 사용하여 통신 할 수 있습니다.
Greengrass에는 GreenGrass Core (GGC)와 IoT Device SDK의 두 가지 구성 요소가 있습니다. 이 두 구성 요소는 현장에서 직접 하드웨어에서 실행됩니다.
Greengrass Core는 128MB 이상의 메모리와 1GHz 이상의 x86 또는 ARM CPU를 갖춘 장치에서 실행되도록 설계되었으며, 필요한 경우 추가 리소스를 이용할 수 있습니다. AWS Lambda 기능을 로컬에서 실행하고, AWS 클라우드와 상호 작용하면서도 보안 및 인증을 관리하면서 주변의 다른 디바이스와 통신할 수 있습니다.
IoT Device SDK는 (일반적으로 LAN 또는 기타 로컬 연결된) 코어를 호스팅하는 디바이스장치에서 실행하는 응용 프로그램을 개발하는 데 사용합니다 . 이런 애플리케이션은 센서에서 데이터를 캡쳐하고, MQTT 토픽를 구독하며 AWS IoT 디바이스 섀도우를 사용하여 상태 정보를 저장 및 검색합니다.
AWS GreenGrass 사용
AWS Management Console, AWS APIs, AWS Command Line Interface (CLI)를 통해 Greengrass의 여러 측면을 설정하고 관리 할 수 있습니다.
새 허브 장치를 등록한 후, 원하는 람다 함수를 구성하며 디바이스에 전달할 배포 패키지를 만들 수 있습니다. 여기에서 경량 디바이스와 허브와 연결 시킬 수 있습니다.
미리 보기 출시
오늘 AWS Greengrass 미리보기를 시작합니다. 참여하고 싶으시다면, 가입하신 후 기다리시면 초대해 드립니다. 각 AWS 고객은 1 년 동안 3 개의 기기를 무료로 사용할 수 있습니다. 그 이후에는 각 활성 Greengrass Core의 월간 비용은 최대 10,000 개의 장치에 대해 $ 0.16 (연간 $ 1.49)입니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS Greengrass – Ubiquitous, Real-World Computing의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
AWS Lambda 신규 기능– 환경 변수 및 서버리스 앱 모델(SAM)
최근 AWS Lambda 및 서버리스(Severless) 애플리케이션 개발 모델이 확대되고 있는 고무적인 현상을 볼 수 있습니다. 특히, AWS Week in Review 에는 최근 이와 관련된 오픈 소스 프로젝트도 많이 늘어났습니다.
이러한 기술 변화에 도움을 줄 AWS Lambda에 두 가지 중요한 기능 추가를 발표하게 되었습니다. 환경 변수 지원 및 새로운 서버리스 애플리케이션 모델입니다.
환경 변수 지정 기능
대부분 개발자들이 하나의 환경 이상에서 코드를 작성하고, 이를 위해서는 재사용 가능한 변수 설정을 통해 시간에 코드의 영속성을 보장해야 합니다. 설정 값은 환경에 따라 테이블명, 파일 경로 등 달라질 수 있는 변수들로서 개발 환경, 테스트 환경, 정식 서비스 환경에 따라 변하게 됩니다.
이제 Lambda 함수에도 이러한 환경 변수를 설정할 수 있게 되었습니다. 변수를 필요에 따라 지정함으로서 코드를 수정 및 재배포하지 않고도, 효율적으로 서버리스 애플리케이션 개발을 할 수 있습니다. 각 환경 변수는 키/밸류 페어로 저장되며 이 값들은 AWS Key Management Service (KMS) 로 암호화 되고, 필요에 따라 복호화 됩니다. 환경 변수의 개수 제한은 없으나 전체 크기가 4kb 미만이어야 합니다.
Lambda 함수의 새 버전을 만들 때, 환경 변수를 설정할 수 있습니다. 여기서 환경 변수를 설정하는 예제를 간단한 Python 코드를 통해 보여 드리도록 하겠습니다.
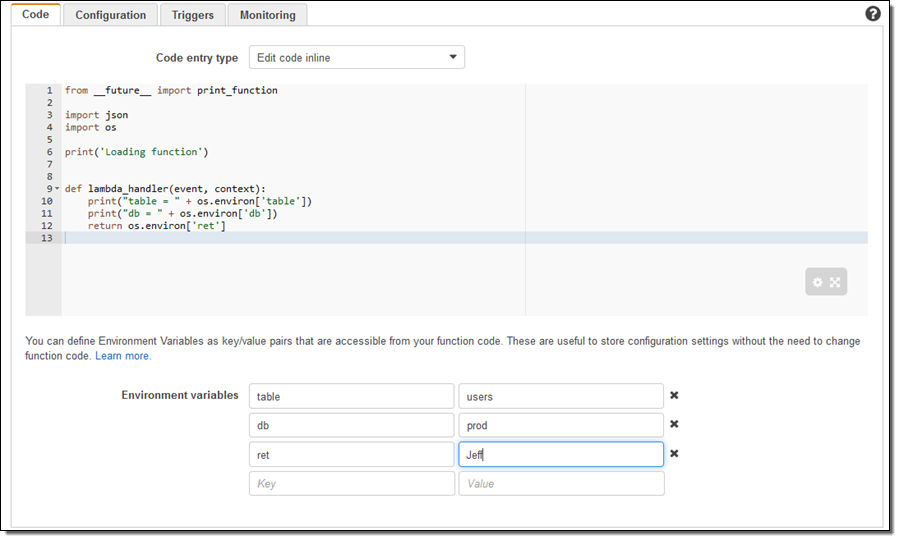
Lambda가 제공하는 기본 서비스 키를 사용하면 추가 비용이 들지 않습니다. (만약 기존에 사용 중인 KMS키에 대해 과금이 될 수 있습니다.)
본 기능에 대해 좀 더 자세한 정보는 Simplify Serverless Applications With Lambda Environment Variables 블로그 글을 참고하시기 바랍니다.
AWS 서버리스 애플리케이션 모델
Lambda 함수, Amazon API Gateway 자원, Amazon DynamoDB 테이블 등을 사용하여 서버리스 애플리케이션을 만들 수 있습니다. 신규 AWS Serverless Application Model (AWS SAM)은 AWS CloudFormation을 활용하여, 손쉽게 자원을 표시할 수 있는 방법입니다. 새로운 문법을 사용하기 위해서는 CloudFormation 템플릿이 Transform 부분을 포함해야 합니다.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
템플릿을 통해 Lambda 함수, API Gateway 엔드 포인트 및 API 리소스, DynamoDB 테이블을 표시하고, 각 함수의 핸들러, 런타임, 코드 배포를 위해 업로드할 Zip 파일 URI 등을 포함 할 수 있습니다.
API는 이벤트 뿐만 아니라 Swagger 를 통해서도 정의 가능합니다.
DynamoDB 테이블을 간단한 문법으로 정의하여, 테이블명, 기본 키 및 형식, 처리량 등을 설정할 수 있습니다.
AWS SAM 파일을 만들어 Lambda 함수의 배포 패키지로 만들 수 있습니다. 간단하게 Actions 메뉴에서 Export function을 선택하면 됩니다.
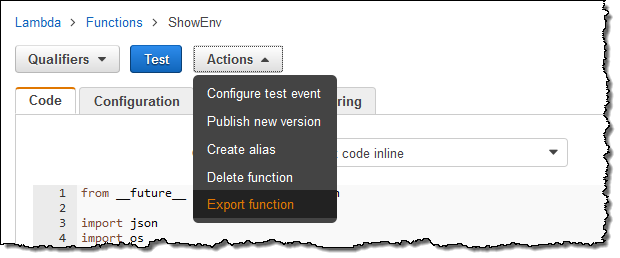
그리고 Download AWS SAM 파일 또는 Download deployment package를 선택합니다.
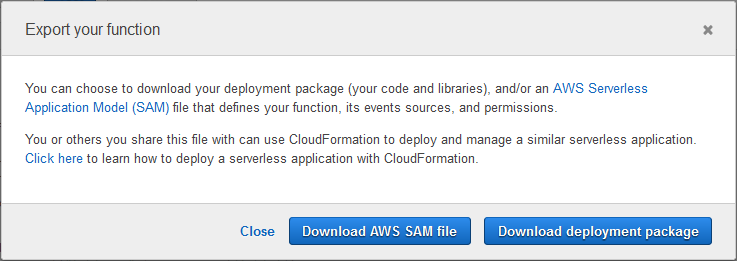
아래에 간단한 샘플 코드가 있습니다.
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Description: A starter AWS Lambda function.
Resources:
ShowEnv:
Type: 'AWS::Serverless::Function'
Properties:
Handler: lambda_function.lambda_handler
Runtime: python2.7
CodeUri: .
Description: A starter AWS Lambda function.
MemorySize: 128
Timeout: 3
Role: 'arn:aws:iam::99999999999:role/LambdaGeneralRole'코드 배포를 위한 ZIP 파일은 S3에 올려서, SAM 파일 내 CodeUri 를 수정하면 됩니다. 간단한 CLI 명령어 (aws cloudformation package and aws cloudformation deploy)를 통해 자동으로 배포할 수 있습니다. 좀 더 자세한 정보는 Introducing Simplified Serverless Application Management and Deployment 블로그 글의 Deploying a Serverless app 부분을 참고하시기 바랍니다.
샘플 예제로 되어 있는 Lambda 함수도 각 박스 오른쪽 아래의 다운로드 버튼을 눌러 받을 수 있습니다.
이제 Download blueprint를 누릅니다.
AWS SAM 파일과 코드가 포함된 ZIP 파일을 받을 수 있습니다.
더 자세한 사항은 Introducing Simplified Serverless Application Management and Deployment 블로그 글을 참고하세요.
— Jeff;
이 글은 New for AWS Lambda – Environment Variables and Serverless Application Model (SAM)의 한국어 번역입니다.
Amazon Aurora 업데이트 – Lambda Function 호출 및 S3 데이터 읽기 지원
AWS 서비스들은 그 자체만으로도 훌륭하지만, 서로 결합함으로써 더욱 다양한 서비스를 만들 수 있습니다. 저희의 서비스 모델은 각 서비스를 선택하여 학습하여 경험을 쌓은 다음, 다른 서비스와 결합 및 확장하는 레고블럭을 조립하는 것 같은 방식입니다. 이를 통해 각 서비스를 다양하게 활용할 기회와 함께 고객의 요구에 따라 서비스 로드맵에 반영할 수 있습니다.
오늘은 이와 관련하여 MySQL 호환 관계형 데이터베이스 서비스인 Amazon Aurora에 두 가지 기능을 추가합니다.
- Lambda 함수 호출 – Amazon Aurora 데이터베이스의 스토어드 프로시저(stored procedures)에서 AWS Lambda 함수를 호출 할 수 있습니다.
- S3 데이터 읽기 – Amazon Simple Storage Service (S3) 버킷에 저장된 데이터를 Amazon Aurora 데이터베이스에서 읽을 수 있습니다.
위의 두 가지 기능은 다른 AWS 서비스를 연계하기 위해 Amazon Aurora에 적절한 권한을 부여해야합니다. IAM 정책(Policy) 및 IAM 역할(Role)을 만들고, 그 역할을 Amazon Aurora 데이터베이스 클러스터에 부여합니다. 자세한 단계는Authorizing Amazon Aurora to Access Other AWS Services On Your Behalf를 참조하십시오.
Lambda 함수 통합
관계형 데이터베이스 트리거(trigger)와 스토어드 프로시저를 함께 사용하여 본 기능을 수행할 수 있습니다. 트리거는 특정 테이블 작업 전후에 수행 할 수 있습니다. 예를 들어, Amazon Aurora는 MySQL과 호환성이 있기 때문에 INSERT, UPDATE, DELETE 작업에 트리거를 지원합니다. 스토어드 프로시저는 트리거에 대한 응답에서 실행 가능한 스크립트입니다.
Lambda 함수를 스토어드 프로시저를 사용하여, Aurora 데이터베이스와 다른 AWS 서비스를 묶을 수 있습니다. Amazon Simple Email Service (SES)를 이용하여 이메일을 보내거나 Amazon Simple Notification Service (SNS)를 이용해 알림을 보내고, Amazon CloudWatch에 사용자 정의 통계를 추가하거나, Amazon DynamoDB 테이블을 업데이트할 수 있습니다.
그 외에도 복잡한 ETL 작업 또는 워크 플로우, 데이터베이스 테이블에 대한 감사, 성능 모니터링 및 분석 등의 용도로도 사용할 수 있습니다.

스토어드 프로시저에서 mysql_lambda_async 프로시저를 호출 하면 됩니다. 이 프로시저는 비동기적으로 주어진 Lambda 함수를 실행하기 위해 함수 실행 완료를 기다리지 않고 처리를 종료합니다. Lambda 함수에 이용하는 AWS 서비스 및 자원에 대한 권한을 부여해야합니다.
자세한 내용은 Invoking a Lambda Function from an Amazon Aurora DB Cluster를 참조하십시오.
S3 데이터 읽기
또한, AWS의 주요서비스인 Amazon S3 버킷에 저장된 데이터를 직접 Aurora에 가져올 수 있게 되었습니다 (지금까지는 한 번 EC2 인스턴스에 다운로드 한 후 가져와야했습니다.)
Amazon Aurora 클러스터에서 접근 가능하면, AWS 어느 리전에 데이터가 배치되어 있어도 읽기 가능합니다. 형식은 텍스트 또는 XML 형식을 지원합니다.
텍스트 형식의 데이터를 가져 오기 위해서는, LOAD DATA FROM S3 명령을 이용합니다. 이 명령은 MySQL의 LOAD DATA INFILE과 거의 같은 옵션을 지원합니다. 그리고, 압축 데이터는 현재 지원하지 않습니다. 특정 행이나 필드 구분자와 문자 집합 설정이 가능하고, 지정한 행과 열 수를 무시하고 통합 할 수 있습니다.
XML 형식 데이터를 가져 오기 위해 새로운 LOAD XML from S3
<row column1="value1" column2="value2" />
...
<row column1="value1" column2="value2" />
또는 아래와 같습니다.
<row>
<column1>value1</column1>
<column2>value2</column2>
</row>
...또는 아래와 같습니다.
<row>
<field name="column1">value1</field>
<field name="column2">value2</field>
</row>
...더 자세한 사항은 Loading Data Into a DB Cluster From Text Files in an Amazon S3 Bucket 문서를 참고하십시오.
정식 출시
본 신규 기능은 오늘부터 이용하실 수 있습니다! 추가로 요금이 부과되지 않지만, 일반적인 Amazon Aurora, Lambda, S3 요금이 발생합니다.
— Jeff;
이 글은 Amazon Aurora Update – Call Lambda Functions From Stored Procedures; Load Data From S3의 한국어 번역입니다.
서버리스 Express 앱 개발을 위한 오픈 소스 패키지 공개
Express는 Node.js를 사용하는 인기있는 웹 프레임웍 중에 하나입니다. 이를 통해 손쉽게 “서버 없는(Serverless)” 웹 사이트, 웹 애플리케이션 및 API 서비르를 만들 수 있습니다. 서버 리스 환경에서 대부분 백엔드 로직은 필요에 따라 요청되는 무상태 기반인 경우가 많습니다. (Mike Roberts의 Serverless Architectures 글 참고. 한국어 번역)
AWS Lambda와 함께 사용 가능한 Amazon API Gateway를 통해 (얼마 전 새로 출시한 간편한 API 개발을 위한 신규 통합 기능을 기반으로) 기존 Express 애플리케이션에 서버리스 기능을 활용할 수 있습니다. API Gateway의 새로운 추가 기능 뿐만 아니라, 개발자별 API 사용량 제어 및 캐싱 등을 지원하는 Usage Plans을 통해 더 나은 API 서비스 제공이 가능합니다.
기존 Express 애플리케이션을 Lambda and API Gateway로 마이그레이션 하기 위해 aws-serverless-express 오픈 소스 패키지를 공개합니다. 여기에는 여러분의 이전 작업을 위한 시작점으로 필요한 샘플 예제가 포함되어 있습니다.
또한, API Gateway and Lambda를 통한 Express 앱 개발을 위한 두 가지 기술 정보를 참고하실 수 있습니다.
- Running Express Apps in AWS Lambda(영문): Claudia.js와 aws-serverless-express 모듈을 통해 애플리케이션을 개발 및 배포하는 방법입니다. 기존 TCP 리스너를 제거한 후, Lambda 프록시를 추가한 후 배포하는 방법입니다.
- Going Serverless: Migrating an Express Application to Amazon API Gateway and AWS Lambda(영문): 위의 글보다는 좀 더 깊이 있는 기술 문서로서, 환경 변수 설정 방법, 데이터베이스 연결 방법, 정적 자원에 대한 효율적인 호스팅 방법 등을 알려주고 있습니다. 추가적인 Lambda 및 API Gateway 기능을 통해 전체 배포 주기 및 과정에 대한 부분도 자세히 담고 있습니다.
— Jeff;
이 글은 Running Express Applications on AWS Lambda and Amazon API Gateway의 한국어 번역입니다.