AWS Partner Network (APN) Blog
A New Strategy for Savings: Distributed Spot Orchestration for Amazon EKS in Harness Cloud Cost Management
By Ravi Yadalam, Product Director, Cloud Cost Management – Harness
By Sunil Bemarkar, Sr. Partner Solutions Architect – AWS
 |
| Harness |
 |
Successfully operating any workload in the cloud requires careful attention to cost optimization, and a need to continually evaluate and refine spending of Amazon Web Services (AWS) resources.
There are various benefits to running your applications on Kubernetes, and why you need it is well established. However, cluster infrastructure also comes with its own challenges.
Before we dive into the specific challenges around cluster infrastructure, let’s take a step back and look at how we can approach cloud cost management holistically.
In this post, we explain how the Harness Cloud Cost Management solution reduces waste with full automation and cost transparency using Cluster Orchestrator for Amazon Elastic Kubernetes Service (Amazon EKS).
Harness is an AWS Partner and modern software delivery platform that uses artificial intelligence (AI) to simplify your DevOps. Harness holds the AWS DevOps Competency for independent software vendors (ISVs) and is a member of the AWS Public Sector Partner Program.
Pillars of Cloud Cost Management
Organizations can approach managing cloud costs through the following three cost management pillars:
- Cost transparency: This involves getting a clear picture of the hierarchical breakdown of cloud spend across your organization. Achieving this means being able to easily answer which teams are spending how much, what cloud services or resources are they spending it on, and why.
- Cost optimization: This involves implementing features that allow you to maximize efficiency, minimize wasted cloud spend, and cut costs as much as possible. This typically requires automation and intelligence built into the tooling providing the automation.
- Cost governance: This involves setting guardrails to make sure your cloud costs are where you want them to be. Checks and balances can include comprehensive budgeting, accurate cloud cost forecasting, and governance policies preferably with automated enforcement.
Cluster Infrastructure Challenges
Now, let’s look at some of the challenges associated specifically with cluster infrastructure.
Balancing Workload Requirements
Balancing workload requirements with cloud infrastructure in general is difficult given all of the various possibilities associated with both aspects. Specifically, autoscaling of cluster nodes based on workload requirements is a challenge given the actively evolving nature of workloads.
Cluster Visibility
Getting complete visibility on cluster costs across pods and nodes can itself be a challenge because of the different ways in which various teams and cost centers consume cloud services and resources. Beyond that, being able to allocate those cloud costs for chargeback or showback can be even harder.
This issue is made even more complex when you have shared cloud accounts, services, and resources across multiple teams and departments. It’s also hard to keep track of cost anomalies when costs are spiking up or crashing down beyond what is business as usual. These are events you should know about as soon as possible before the impact on your cloud bill gets out of hand.
Cluster Optimization
Properly optimizing clusters requires granular tracking of the utilization requirements of workloads and nodes over time because of constantly evolving requirements. This data needs to be leveraged to right-size cluster nodes and workload configurations. Because this is difficult to achieve, overprovisioning of both workloads and nodes has always been a problem.
Then there’s the tricky choice from the cloud trinity: what do you choose from in terms of on-demand instances, instances covered under commitments, and Amazon EC2 Spot instances? This decision requires several considerations, including Spot-readiness of the workload and the overall commitment purchases you have.
Finally, idle workloads and nodes cause a ton of wasted cloud spend. Automatically detecting and correcting this can be a huge challenge without the right tooling and practices.
So, what does Kubernetes provide today that may be elevating some of this?
Pod Autoscaling
Horizontal pod autoscaling (HPA) deploys more pods in response to increased load and reduces pod count in response to decreased load. So, your pod count would grow or shrink based on demand going up or down. HPA checks metrics to see if the pod utilization is crossing certain thresholds to determine if there’s a need to scale the number of pods up or down.
Similar to HPA, with vertical pod autoscaling (VPA) you are increasing or decreasing the size or resources of each pod, which could be CPU or memory.
With HPA increasing and decreasing pod count, and VPA increasing and decreasing pod size, native Kubernetes autoscaling tries to match these dynamic changes with the right nodes. That’s where things start to get messy.
What could go wrong with node selection? If the wrong node type does not have enough resources and a pending pod need is spun up, then you have pods left in a pending state. Similarly, with the existing cluster nodes, if the wrong node is scaled down then you again face the risk of pods remaining in pending state.
Harness Cluster Orchestrator for Amazon EKS
The Harness Cluster Orchestrator for Amazon EKS provides workload-driven intelligent autoscaling. It brings automation to balance workload requirements with cloud infrastructure, and brings intelligence to autoscaling with distributed Spot orchestration based on workload requirements.
The Cluster Orchestrator also integrates with the larger Harness Cloud Cost Management capabilities to provide the most granular cost visibility, allocation, and automated optimization options.
Finally, the solution provides simple, actionable workload and node resizing recommendations with auto-apply capability to avoid overprovisioning of any kind.
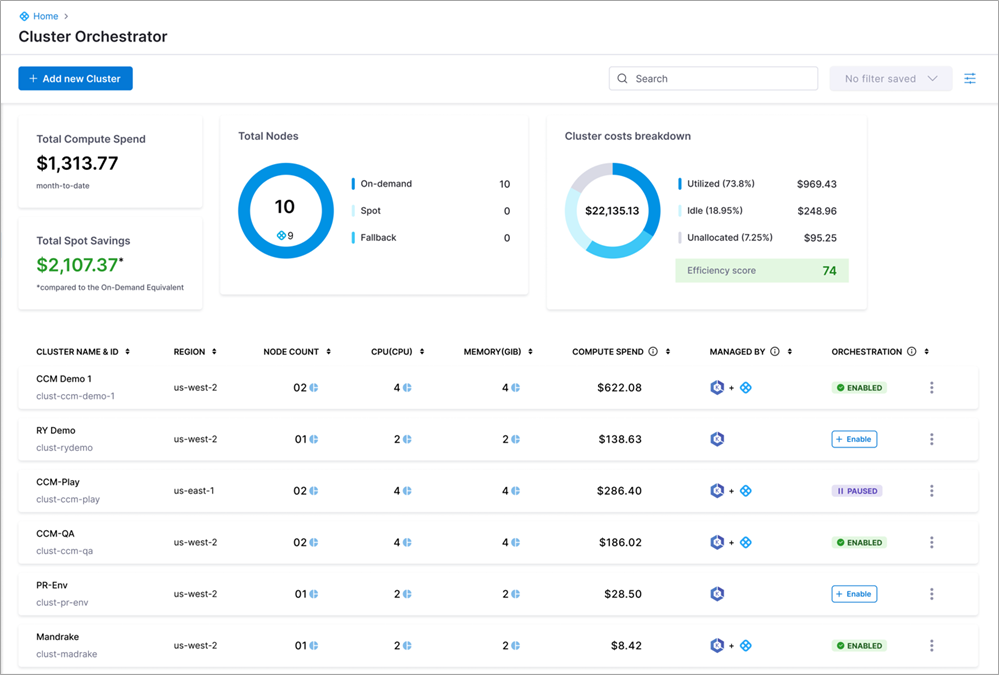
Figure 1- Harness Cluster Orchestrator view.
Spot Orchestration
The Cluster Orchestrator comes with full Spot instance orchestration built in. This capability enables you to run your workloads on Spot instances with up to 90% savings over On-Demand instances without worrying about Spot interruptions.
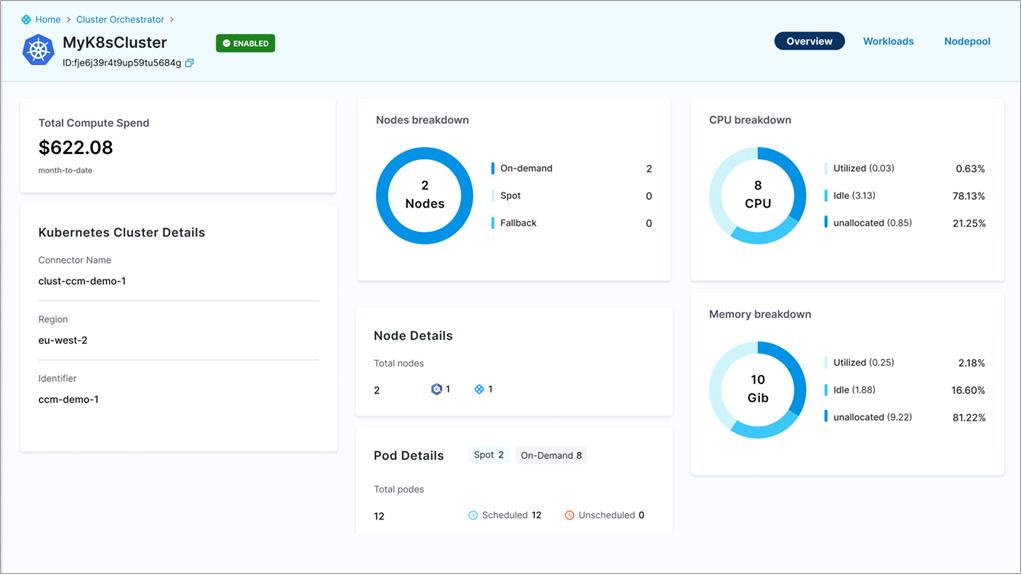
Figure 2 – Harness individual “ccm-demo-1” Kubernetes cluster overview.
Alternate Spot Instance
Upon receiving a Spot interruption notice from AWS, the Cluster Orchestrator automatically provisions an alternate Spot instance that has available Spot capacity, enough resources to run the pods, and the least likelihood of future interruptions.
Spot to On-Demand Fallback
The Cluster Orchestrator also temporarily switches from Spot to On-Demand when Spot capacity is unavailable. This is done to maintain availability and avoid running under capacity, though at a temporarily higher cost.
On-Demand to Spot Reverse Fallback
During this fallback from Spot to On-Demand, the Cluster Orchestrator continuously monitors for available Spot capacity. When it finds available Spot capacity, it does a reverse fallback to Spot. This is fully automated with no manual intervention.
Leveraging Native AWS Spot Capabilities
Behind the scenes, the Cluster Orchestrator uses several native AWS Spot capabilities out of the box. You don’t have to worry about keeping up with everything that AWS is continuously releasing to help you get the most out of Spot instances.
AWS Spot Instance Advisor API
The Cluster Orchestrator leverages the AWS Spot Instance Advisor API to determine which instance to launch based on the likelihood of interruption for each instance family. Additionally, Harness uses its own internal customer data as well.
Amazon EC2 Instance Rebalance Recommendations
The Cluster Orchestrator leverages the Amazon Elastic Compute Cloud (Amazon EC2) instance rebalance recommendations to identify constrained capacity pools. However, this is on a best-effort basis.
Spot Placement Score
The Cluster Orchestrator leverages the Spot Placement Score (SPS) to check the likelihood of Spot interruption based on placement in an AWS Availability Zone (AZ), region, and instance family.
Allocation Strategy
The Cluster Orchestrator follows a capacity-optimized allocation strategy. Harness uses diversified instances spread across multiple AZs.
Distributed Spot Orchestration
Spot instances and Spot orchestration are great for workloads that are Spot-ready. But what about critical workloads you don’t want to associate with any kind of Spot interruption risk How can you save on those workloads?
This brings us to a key differentiating factor of the Cluster Orchestrator: Distributed Spot Orchestration. This is configured with a custom resource the Cluster Orchestrator provides called the “workload distribution rule.” This workload distribution rule enables you to do the following three things.
1. Split Workload Replicas Across Spot and On-Demand
First, the workload distribution rule enables you to split replicas of a single workload to run on Spot and On-Demand nodes to maximize savings and minimize interruption risk.
2. Workload Distribution Strategy
Second, you can set a distribution strategy of cost-optimized if you want to run all Spot replicas on the least number of Spot nodes. This helps maximize savings but is slightly riskier with regard to interruptions.
You can also set a least-interrupted workload distribution strategy to make sure all Spot replicas are running on different Spot nodes as much as possible. This significantly reduces the chances of interruption, making it safer from an availability standpoint.
3. Base On-Demand Capacity
Third, like with autoscaling groups, you can set a base On-Demand capacity to ensure a minimum guarantee of On-Demand replicas beyond only which the Spot/On-Demand distribution ratio from the first option will kick in.
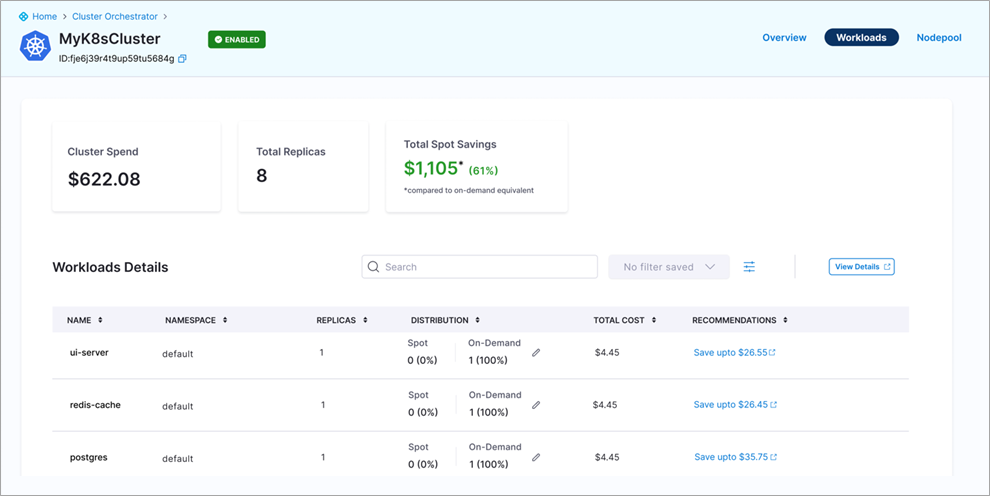
Figure 3 – Cluster Orchestrator base On-Demand capacity workload details view.
Intelligent Bin-Packing
The Cluster Orchestrator also has bin-packing capabilities built in to pack the optimal number and choice of pods onto cluster nodes, to potentially free up and optimize node resources. Optionally, as a more aggressive approach, you can choose to enable bin-packing of single replica applications that are otherwise excluded from bin-packing by default.
Leveraging Commitments
The Cluster Orchestrator has integration with another Harness feature called the Commitment Orchestrator that orchestrates the purchase and utilization of Amazon EC2 Reserved Instances (RIs) and Savings Plans to maximize savings and compute spend coverage. This integration enables prioritizing nodes covered by commitments over On-Demand nodes when Spot is either not applicable or available.
Automatic Scale Down of Idle Workloads
There can be tremendous savings with Spot instances and commitments, but what can be cheaper than scaling down to zero? The Cluster Orchestrator has integration with yet another Harness feature called Cloud AutoStopping that enables automatic scaling down of idle workloads all the way to zero. This includes scaling down other dependent services, virtual machines (VMs), Amazon Relational Database Service (Amazon RDS) databases, and more.
AutoStopping also automatically scales up the same workloads to service new incoming requests based on network traffic. This functionality ensures you have maximum savings down to the most granular windows of idleness at a workload level.
Savings Example: 84% Savings on a Non-Production Cluster
Let’s take an indicative example of a non-production Amazon EKS cluster to illustrate the savings with Harness and the Cluster Orchestrator.
This example non-production EKS cluster has 10 m4.xlarge nodes running in the US East (Ohio) region on Linux.
EKS EC2 Nodes: 10
- Each node:
- CPU – 4
- Memory – 16 GiB
- Price – $144/mo
- m4.xlarge in US East (Ohio) on Linux
Pods per node: 4
- Each pod:
- CPU – 1
- Memory – 4 GiB
- Price – $36
Without the Cluster Orchestrator
- On-Demand cost, running all month: $1,440
With the Cluster Orchestrator and AutoStopping
- On-Demand cost after dynamic idle time scale down: $533 ($907 or 63% savings)
- Assumptions:
- Average 70% idle time per month across pods
- Minimum one node at all times
- Assumptions:
- Final Spot cost after dynamic idle time scale down: $231 ($1,209 or 84% savings)
- Assumptions:
- 81% Spot savings over On-Demand for m4.xlarge running in US East (Ohio) on Linux
- 70% Spot nodes, 30% On-Demand nodes
- Assumptions:
Conclusion
The Harness Cluster Orchestrator for Amazon EKS comes with new distributed Spot orchestration capabilities, along with many other features to help you leverage up to 90% savings from Spot instances for all your workloads.
Whatever your goals and objectives are for properly managing cloud costs and realizing significant savings on your cloud spend, Harness Cloud Cost Management has you covered.
Sign up for a free trial through AWS Marketplace.
.

.
Harness – AWS Partner Spotlight
Harness is an AWS Partner and modern software delivery platform that uses AI to simplify your DevOps. Harness holds the AWS DevOps Competency for ISVs and is a member of the AWS Public Sector Partner Program.