AWS Partner Network (APN) Blog
Automate Data Sharing with Informatica Axon Data Marketplace and AWS Lake Formation
By Prasanna Sridharan and Praveen Kanumarlapudi, Data and Analytics Architects – AWS
By Jason Berkowitz, Global AWS Professional Services Data Analytics Lead – AWS
By Deepak Rameswarapu, Director, Product Management – Informatica
By Joshua Erhardt, Director, Strategic Ecosystem Architecture Solutions – Informatica
 |
| Informatica |
 |
A key goal of modern data strategy, whether a data mesh, data fabric, data lake, or data warehouse, is to deliver access to data when and where it’s needed.
Delivering this kind of ubiquitous access brings its own set of challenges in a world where unintended disclosure of sensitive data could bring real damage to an organization.
Data governance and privacy policies and procedures are created to inform and facilitate controlled access to data, but often slow things down to the point of being a serious barrier to the business. These barriers can be overcome by blending a robust data architecture with an automated data governance framework.
In this post, we describe how Amazon Web Services (AWS) and Informatica can combine and automate data governance for access within a data marketplace.
Following up on the blog post for designing a data mesh architecture using AWS Lake Formation and AWS Glue, this approach leverages a similar data mesh pattern with multiple AWS accounts, including a data lake account, central data governance account, and consumer accounts.
Data mesh is a pattern for defining how organizations can organize around data domains with a focus on delivering data as a product. When data is managed as a product, there is a defined data owner and data platforms that require systems to manage the responsibilities and processes of the data owner.
This solution combines Informatica’s data governance architecture which delivers enterprise data visibility, and the Informatica Intelligent Data Management Cloud (IDMC) which orchestrates and automates data access management with AWS Lake Formation.
Informatica is an AWS Data and Analytics Competency Partner that provides enterprise cloud data management software and solutions that accelerate cloud modernization on AWS.
AWS Solution Elements
Data Lake and Central Data Governance Account
One of a central data lake’s primary purposes is to make finding, managing, and accessing data easier. The purpose of the central data governance account is to help control how each organizational domain owns their own data end to end.
The central data governance account stores a data catalog of all enterprise data across accounts, and provides features allowing producers to register and create catalog entries with AWS Glue from all of their Amazon Simple Storage Service (Amazon S3) buckets.
The data governance account helps data owners with building, operating, serving, and resolving any issues arising from the use of their data. Within the data governance account is AWS Lake Formation, which centrally defines security, governance, and auditing policies in one place.
AWS Lake Formation enforces data access policies for consumers across analytics applications, and only provides authorization and session token access for data sources to the role that is requesting access.
AWS Lake Formation also provides uniform access control for enterprise-wide data sharing through resource shares with centralized governance and auditing. In the data governance account, we integrate Lake Formation with additional metadata stored within Informatica for data access.
Consumer Account
Data must be easily consumable by subject matter personas like data analysts and data scientists, as well as purpose-built analytics and machine learning (ML) services like Amazon Athena, Amazon Redshift, and Amazon SageMaker. A consumer is any entity who subscribes to a data product in the data mesh.
To do that, data domains must expose a set of interfaces that make data consumable while enforcing appropriate access controls and audit tracking. In this solution, we are implementing a consumer account that isolates data consumers but also ensures governance.
Informatica Solution Elements
Data Governance / Intelligent Data Management Cloud (IDMC)
Informatica provides a leading data governance platform. At the core is Axon, which provides both the Data Marketplace and Data Governance applications. Working in conjunction with Axon is the Informatica Enterprise Data Catalog (EDC), which acts as a catalog of catalogs, gathering and enriching metadata from across the enterprise to provide a holistic view of the entire data landscape.
Informatica data quality can enrich the governance view by providing data quality insights across the landscape. These core components of the Data Governance suite provide the foundation for gathering the metadata needed to enable a rich marketplace.
IDMC’s application integration capabilities deliver the process automation capabilities to tie the marketplace to the AWS Lake Formation engine to fulfill the orders and provide the data access.
Axon Data Governance and Marketplace
Axon Data Governance empowers teams with consistent, trusted data, providing integrated, automated data governance at scale. With a built-in data marketplace, it provides a governed shopping experience that allows users to shop for and order data and owners to approve and track access rights to data.
Informatica Axon Data Governance can be deployed from AWS Marketplace.
Enterprise Data Catalog
The EDC is an artificial intelligence-driven catalog that automatically gathers, connects, and enriches metadata about enterprise assets from sources. This includes on-premises or cloud-based locations such as data stores, business intelligence platforms, data integration tools, and other catalogs.
Informatica EDC can be deployed directly from AWS Marketplace.
IDMC Application Integration
IDMC provides over 200 intelligent data services, including application integration to provide real-time orchestration across heterogenous cloud services.
Informatica IDMC can be deployed directly from AWS Marketplace.
Solution Architecture
In this post, we will describe how a user of data can search and find data in the Informatica Axon catalog, request access, and use data immediately.
Below is the architecture diagram integrating AWS and Informatica pipelines to orchestrate the data access request and grant process.

Figure 1 – Reference architecture.
- AWS Glue crawler in the central data governance account crawls the Amazon S3 data lake buckets and creates the technical metadata.
- AWS Lake Formation and AWS Glue share the same technical metadata catalog.
- Informatica EDC syncs with the AWS technical metadata catalog.
- Some of the metadata from the EDC are exposed to Axon data marketplace.
- Business users access the Axon marketplace and place an order for an existing dataset.
- The user’s order flows through the marketplace order process and is approved by the data owner.
- The cloud application integration (CAI) process queries the marketplace for orders ready for fulfillment to begin the required provisioning. CAI automatically retrieves additional metadata from EDC if required and composes request.
- CAI creates the consumption JSON manifest file.
- CAI process writes the consumption JSON manifest file to the Amazon S3 manifest bucket.
- The manifest file creates an S3 notification event and populates the lf-automation Amazon Simple Queue Service (SQS) queue.
- The lf-automation SQS queue triggers the AWS Lambda function for each incoming file, and divides the file with multiple permission blocks into separate permission requests.
- Each permission request is published to the Amazon Simple Notification Service (SNS) topic lf-automation as a separate message.
- The lf-automation SNS topic pushes SQS messages to the lf-permissions SQS queue in the central data governance account.
- The lf-permissions SQS queue triggers the Lambda function for each incoming message, which grants cross-account access by invoking the AWS Lake Formation boto3 APIs.
- The lf-automation SNS topic pushes SQS messages to the lf-permissions SQS queue in the consumer account.
- The lf-permissions SQS queue triggers the Lambda function for each incoming message, which applies the specified permission by invoking the AWS Lake Formation boto3 APIs.
- AWS Lake formation permissions are granted to the consumer user.
- AWS Lake formation objects and permissions are exposed to the analytic services like Amazon Athena.
- Consumer user accesses the objects via Amazon Athena.
- The Lambda function invokes REST API to report results of provisioning request back to CAI, which processes and updates the marketplace order with appropriate results.
The solution uses the following AWS services:
Data Lake and Central Data Governance Account
- 2 Amazon S3 buckets
- 2 AWS Lambda functions
- 2 Amazon SQS queues
- 1 Amazon SNS topic
- AWS Lake Formation
- AWS Glue
- AWS Resource Access Manager (RAM)
Consumption Account
- 1 Amazon S3 bucket (for Amazon Athena results)
- 1 Amazon SQS queue
- 1 AWS Lambda function
- Amazon Athena
- AWS Lake Formation
- AWS Resource Access Manager (RAM)
AWS Prerequisites and Setup
Following are the prerequisites before starting the deployment of the solution:
- The solution requires you to complete the AWS Organizations setup before starting the deployment.
- Administrator access to two AWS accounts:
- Central data governance account – An AWS account holding the central data lake resource to share across accounts.
- Consumption account – An AWS account with consumer roles.
- Create AWS Organization in the central data governance account and make it the same as the management account. Now, add member accounts (producer and consumption accounts). Refer to the AWS documentation for instructions.
- Enable RAM sharing via AWS Organizations.
Data Lake and Central Data Governance Account Setup
- Download the central yaml file from the repo.
- Sign in as the admin to your central data governance account, go to AWS CloudFormation > click on Create Stack > select Upload a template file and upload the file you downloaded from Step 1, and then click Next.
- Fill in all of the required fields like Stack Name and OrgId.
- Please note the only mandatory fields in this template are Stack Name, OrgId, and Admin role name. OrgId is found in the AWS Organizations page, when all of the prerequisites were setup.
- Click Next and wait for the stack CREATE_COMPLETE.
- Once the stack is completed, go to Outputs and save the SNS topic arn. This is used in the consumption setup.

Figure 2 – Central data governance account – CloudFormation stack.
After the central data governance account deployment is complete, you may notice the following resources have created in your central account:
- The Data bucket and the Manifest bucket.
- Copies the NY Taxi dataset (June 2021) from the Registry of Open Data on AWS bucket to the Data bucket.
- AWS Glue catalog table named nyc_taxi_data in a database named lf_automation pointing to the same dataset in the Data bucket.
- SQS queue to receive Amazon S3 file notifications from the Manifest bucket.
- AWS Lambda function that listens to the SQS queue and creates multiple message notifications.
- SNS topic with a message filter based of message attributes, and delivers messages to other accounts.
- SQS queue to receive SNS notifications.
- Lambda function that listens to the SQS queue and sets the database-level permissions for AWS Lake Formation.
Consumption Account Setup
- Download the consumption yaml file from the repo.
- Sign in as the admin to your consumption account, go to AWS CloudFormation > click on Create Stack > select Upload a template file and upload the file you downloaded from Step 1, and then click Next.
- Fill in all of the required fields:
- Central account – Account number of central catalog account
- TopicArn – Copied from output of central catalog account CloudFormation stack.
- Click Next and wait for the stack CREATE_COMPLETE.
After consumption deployment is complete, you may notice the following resources have created in your central account:
- SQS queue to receive SNS notifications from the central catalog account.
- As Lambda function that listens to the SQS queue and sets the database, table, or column-level permissions for AWS Lake Formation.
- Two consumption users (lf-taxi-manager and lf-business-analyst).
- Amazon Athena resource access to the consumption users.
Once the solution is deployed you can login to the Informatica Axon Data Marketplace and request for data access. Once the request is approved, it will create a JSON manifest file which will trigger the AWS pipeline and grant appropriate access.
You can validate the access by logging into the AWS Management Console and querying it through Amazon Athena.
Informatica Prerequisites and Setup
The following instructions provide an overview of how the solution can be created, but we strongly recommend reaching out to your Informatica account team to assist you. Learn more about scheduling an Informatica + AWS Lake Formation integration session.
- Deploy Informatica solution components:
- Configure EDC to scan the Glue catalog by creating an EDC resource type and entering the appropriate credentials. Additional settings can be configured in further steps of the resource configuration wizards. Once complete, save and run the resource to scan and ingest the information in the Glue catalog. This will consume the metadata in the Glue catalog and create associated metadata objects in EDC.
- Configure Axon Data Governance/EDC integration and then create rules to automate onboarding of desired metadata into Axon from EDC. These rules allow you to control what metadata is brought into Axon to be put under governance.
- Publish the onboarded metadata for critical data sets into Axon Data Marketplace. These published data sets should represent curated data for consumption across the enterprise.
- Configure Axon Data Marketplace for any custom fields needed by the provisioning process (consumer account number or user, for example).
- Create the IDMC application integration process, which invokes the required Axon and EDC APIs to retrieve approved orders from Axon Data Marketplace. This gathers additional required metadata from Axon Data Governance and EDC, and then writes the specific JSON file to a known Amazon S3 bucket for AWS processing.
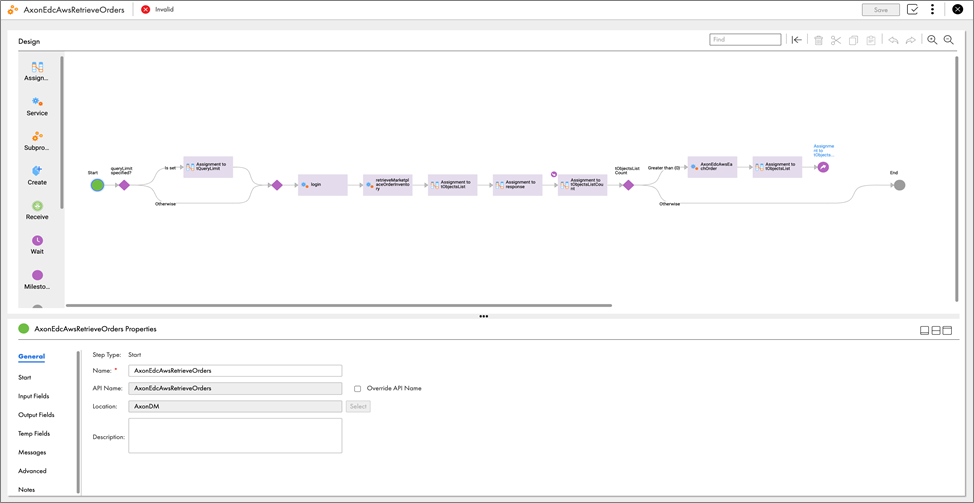
Figure 3 – IDMC application integration process.
End User Experience
A user starts with a shopping experience in Axon Data Marketplace. Here, you can browse for curated data collections that can be made available.
The governed ordering process includes accepting terms of use as well as a data owner approval. Once approved, fulfillment is automated through the use of IDMC application integration and AWS Lake Formation.
- User signs into Axon Data Marketplace.

Figure 4 – Informatica Data Marketplace.
- Navigate to the EDP Data Lake category, where you can see the available data collections that have been published.

Figure 5 – Published data collections inside Informatica Data Marketplace.
- Select the taxi_user collection to see specifics about the collection, including details about the attributes included as well as quality measures that have been captured.
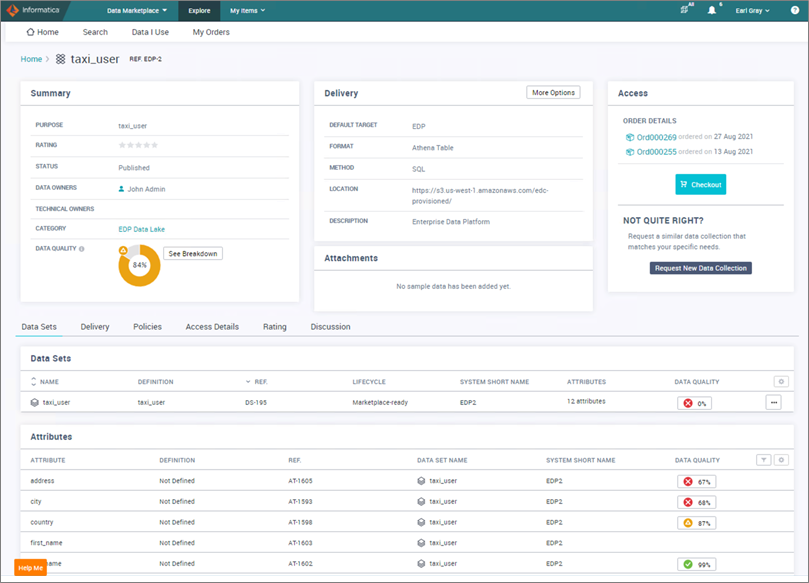
Figure 6 – Data collection results inside Informatica Data Marketplace.
- Users can request access by hitting the Checkout button and completing the order form, which includes a justification for the request and other required information.
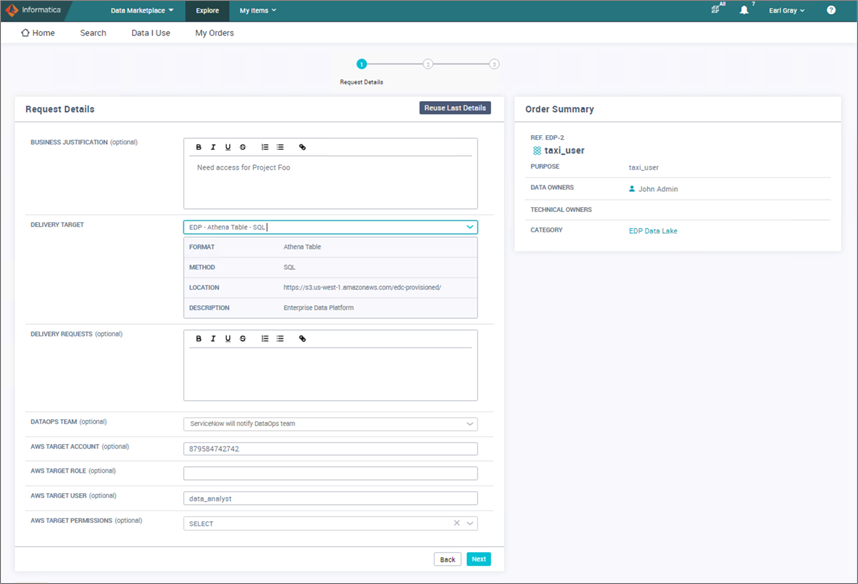
Figure 7 – Order form inside Informatica Data Marketplace.
- The user must agree to the terms of use for the data set up by the data owners.

Figure 8 – Order summary inside Informatica Data Marketplace.
- Once submitted, the user can see the status is pending approval.
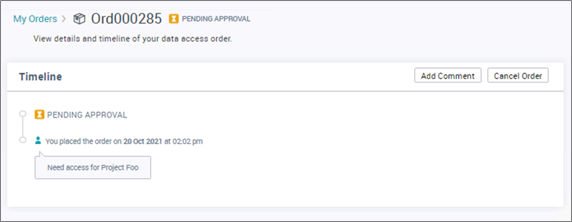
Figure 9 – Order status inside Informatica Data Marketplace.
- Data owners are presented with tasks related to user orders for the data collections they are responsible for.
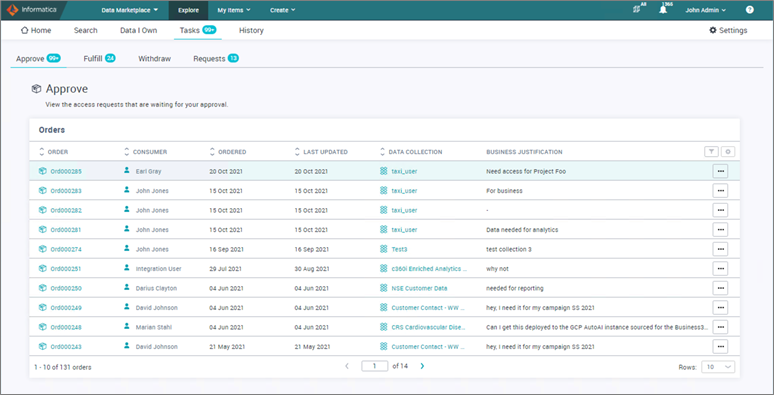
Figure 10 – Order approval requests inside Informatica Data Marketplace.
- The owner can approve, reject, or ask for more information by selecting an order. Once approved, an order will move to the Fulfillment stage.

Figure 11 – Order fulfillment inside Informatica Data Marketplace.
- The IDMC application integration process retrieves approved orders, gathers all the required metadata from Axon and EDC to prepare the order manifest, and writes that manifest to the target Amazon S3 bucket.
.
The Lake Formation automation will trigger and, through a series of Lambda and AWS Step functions, provision the requested access. When complete, it will signal the application integration process via a REST API with the status of the order. The process will appropriately update the Axon Data Marketplace order status and record the user access grant for the data collection.

Figure 12 – Fulfilled order inside Informatica Data Marketplace.
Conclusion
The goal of many chief data officers is to deliver governed access to data in minutes not months. The architecture outlined in this post demonstrates this goal is achievable.
While this framework was implemented to provision access to data already in the data mesh, it could easily be extended to provision data into new lakes, sandboxes, or analytics environments.
Ideally, the data governance platforms have an enterprise-wide view of data that goes beyond the data lake and could provide the needed metadata for any cataloged asset. This helps to enable the AWS Lake Formation ingestion framework to ingest new data into the data lake.
.

.
Informatica – AWS Partner Spotlight
Informatica is an AWS Data and Analytics Competency Partner that provides enterprise cloud data management software and solutions that accelerate cloud modernization on AWS.
Contact Informatica | Partner Overview | AWS Marketplace
*Already worked with Informatica? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.