AWS Partner Network (APN) Blog
Building a Multi-Tenant SaaS Solution Using AWS Serverless Services
By Anubhav Sharma, Sr. Partner Solutions Architect – AWS SaaS Factory
By Ujwal Bukka, Partner Solutions Architect – AWS SaaS Factory
 |
The move to a software-as-a-service (SaaS) delivery model is accompanied by a desire to maximize cost and operational efficiency.
This can be especially challenging in a multi-tenant environment where the activity of tenants can be difficult to predict. Finding a mix of scaling strategies that align tenant activity with the actual consumption of resources can be elusive. The strategy that works today may not work tomorrow.
These attributes make SaaS a compelling fit for a serverless model. By removing the notion of servers from your SaaS architecture, organizations can rely on managed services to scale and deliver the precise number of resources your application consumes.
This simplifies the architecture and operational footprint of your application, removing the need to continually chase and manage scaling policies. This also reduces the operational overhead and complexity, pushing more of the operational responsibility to managed services.
In this post, we’ll look into a reference solution that provides an end-to-end view of a functional multi-tenant serverless SaaS environment. The goal is to explore the architecture and design considerations that went into creating this reference solution.
This includes looking at how you can leverage using Amazon Web Services (AWS) serverless services, such as Amazon API Gateway, Amazon Cognito, AWS Lambda, Amazon DynamoDB, AWS CodePipeline, and Amazon CloudWatch to take advantage of the serverless model.
The reference solution illustrates many of the components needed to build a multi-tenant SaaS solution, such as onboarding, tenant isolation, data partitioning, tenant deployment pipeline, and observability. You can use this GitHub repository to deploy and explore the reference solution in your AWS account.
Supporting Multiple Deployment Models
Before diving into the specifics of this serverless SaaS reference solution, it will be beneficial to outline the different deployment models supported by this experience. We’ve included two deployment models in the solution—silo and pool—to highlight how these models can influence the onboarding, isolation, noisy neighbor, performance, and tiering profile of a serverless SaaS environment.
For the silo model, you’ll see each tenant has its own set of infrastructure resources. On the other hand, in the pool model, all tenants share a common storage and compute infrastructure. You can read about these isolation models in the SaaS Tenant Isolation Strategies whitepaper.
This serverless SaaS solution uses tiers to determine which model a tenant uses. Basic, Standard, and Premium tier tenants will share common set of resources. Platinum tier tenants will have their own dedicated resources.
Deploying the Baseline Environment
The README file provides instructions to deploy the serverless SaaS baseline environment.
The installation process provisions all of the resources that are part of the baseline environment. This represents the infrastructure and resources you’ll need to begin onboarding both silo and pool tenants. A diagram of this baseline infrastructure is shown below.
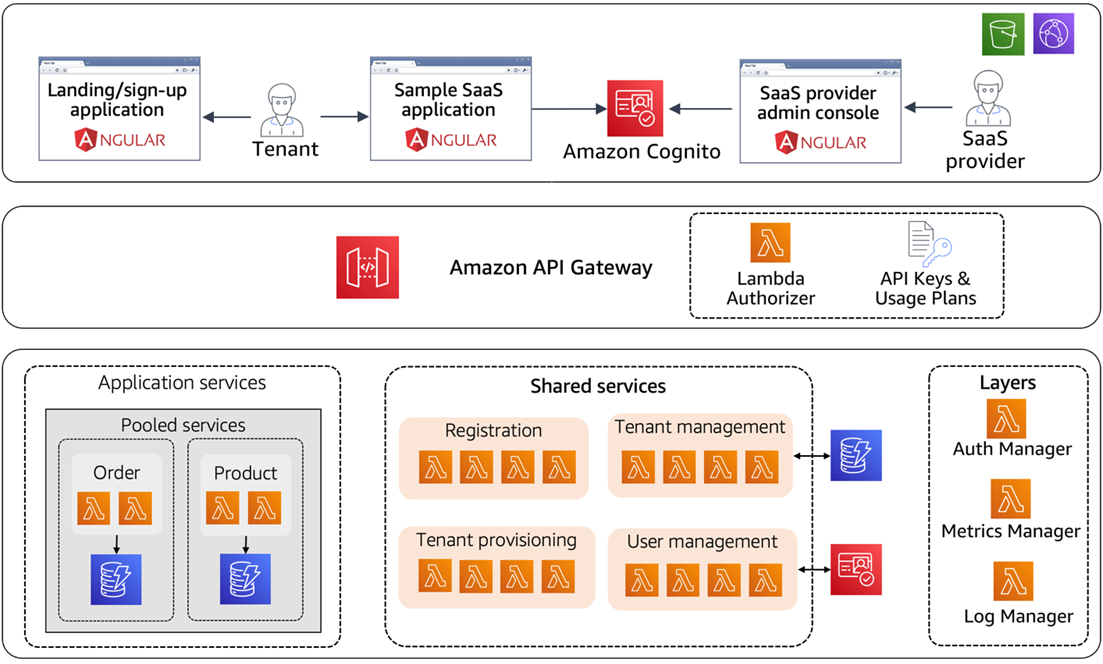
Figure 1 – Baseline deployment footprint.
You’ll notice that we have an end-to-end representation of all the applications, services, and infrastructure needed to run our multi-tenant serverless SaaS solution. The sections that follow provide a breakdown of the key elements of this environment.
Web Applications
You’ll see we have built three different applications that interact with the backend services of the environment. We have used Angular to build these applications.
The “SaaS provider admin console” represents an application that’s used by the administrators of a SaaS provider. The “Landing/sign-up application” serves as a public facing registration page for new tenants to register themselves. The “Sample SaaS commerce application” represents a typical ecommerce application.
This application also includes some minimal functionality to simulate a SaaS application, allowing you to create/update products and orders.
Shared Services
Our environment also includes a set of shared services that are responsible for the onboarding, tenant, and user management aspects of the application.
The name “shared” conveys the notion that these services are foundational to your SaaS environment, providing the cross-cutting functionality that’s separate from your application services and shared across all of the tenants. This means the operations and data used to onboard, manage, authenticate, and configure tenants are handled by these shared services.
Application Services
Application services are a representation of the microservices that provide the business functionality of your application. As noted above, the deployment and role of these application services will change based on a tenant’s tier.
For our baseline environment, we have deployed the application services that will be consumed by tenants in a tier that use the pooled model. Later, as you onboard Platinum tier tenants, you’ll see we deploy separate application services for each tenant in this tier.
Multi-Tenant Data Storage
The multi-tenant application services of our application are using Amazon DynamoDB to store our multi-tenant data. For our pooled tenants, we’re storing data in a pooled construct where tenant data is co-mingled in a shared DynamoDB table. This approach requires the introduction of a tenant partitioning key that associates DynamoDB items with individual tenants.
You can read this blog post to get more details about this approach.
Notion of Serverless Microservices
In order to better understand the architecture, you need to understand the notion of how we compose microservices in a serverless environment. It’s true that each function could be a microservices, but it’s more common to have a collection of functions that represent a logical microservice.
In this case, our microservice boundary is the Amazon API Gateway, backed by one of more Lambda functions. Imagine, for example, an order service that has separate functions for create, read, update, and delete orders. These functions all operate on the same data and should be grouped together as a logical microservice.
The diagram below provides a high-level representation of this concept. You can also refer this whitepaper to understand this concept in more detail.
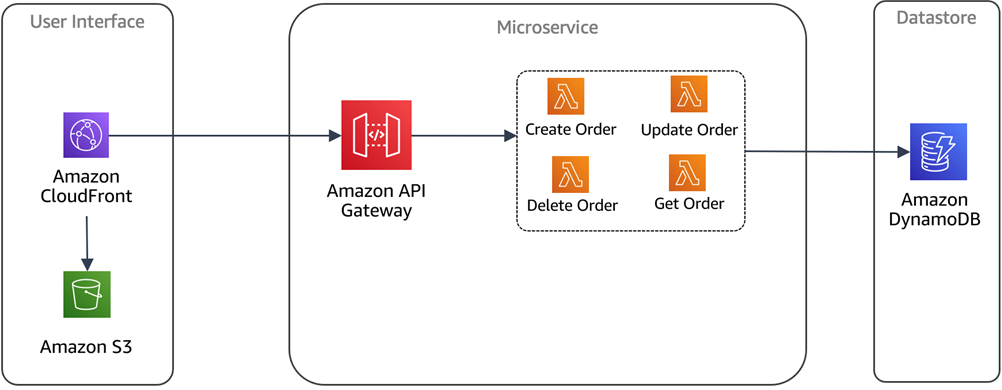
Figure 2 – Serverless microservices.
Tenant Registration and Onboarding
Now that we have a sense of the baseline architecture, let’s look at how tenants are introduced into this environment. Tenants can register themselves using the sign-up web application. The tenant registration flow varies slightly based on the tier the tenant selects during the sign-up process.
The following diagram depicts the tenant registration flow and how tenant registration service leverages other services to orchestrate the tenant registration.
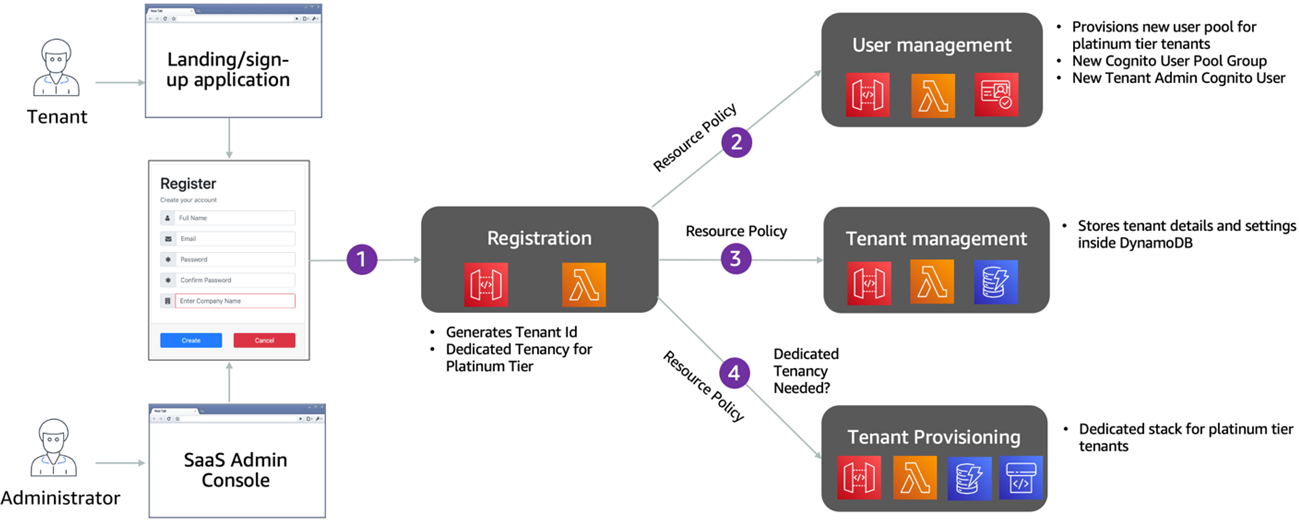
Figure 3 – Tenant registration flow.
The steps of the sign-up process are as follow:
- Tenant provides their sign-up details and tier. The registration service examines the tier, and if the tenant has selected a Platinum tier it’s flagged to be onboarded in a siloed model (dedicated resources). If any other tier is selected, the tenant will be flagged to be onboarded in a pooled model (shared resources).
- The registration service invokes the user management service to create a new tenant admin user; we used Amazon Cognito as our identity provider. For Platinum tier tenants, you’ll notice a separate user pool is provisioned for each tenant. Other tiers share a common user pool, but are assigned different Cognito groups within that single user pool. The Tenant Id and user role are stored as a custom claim inside Cognito.
- The registration service invokes the tenant management service to store tenant details. As part of this process, we associate an API key with the tenant, based upon the tenant tier selected during onboarding.
- Finally, the tenant provisioning service invokes the tenant pipeline to provision any tenant specific infrastructure for Platinum/silo tenants.
Tenant registration service makes use API Gateway Resource Policies to authenticate against the user management, tenant management and provisioning service.
Tenant Deployment Pipeline
For this solution, we used AWS CodePipeline to manage the deployment of our application services (Product and Order service, in our case).
This pipeline is responsible for creating and updating the tenant infrastructure using a CI/CD approach. When you publish/merge your code to the main branch, the pipeline (as shown in Figure 4) will trigger automatically, build the source, perform all of the necessary unit tests, and deploy the services for all your tenants in an automated fashion.
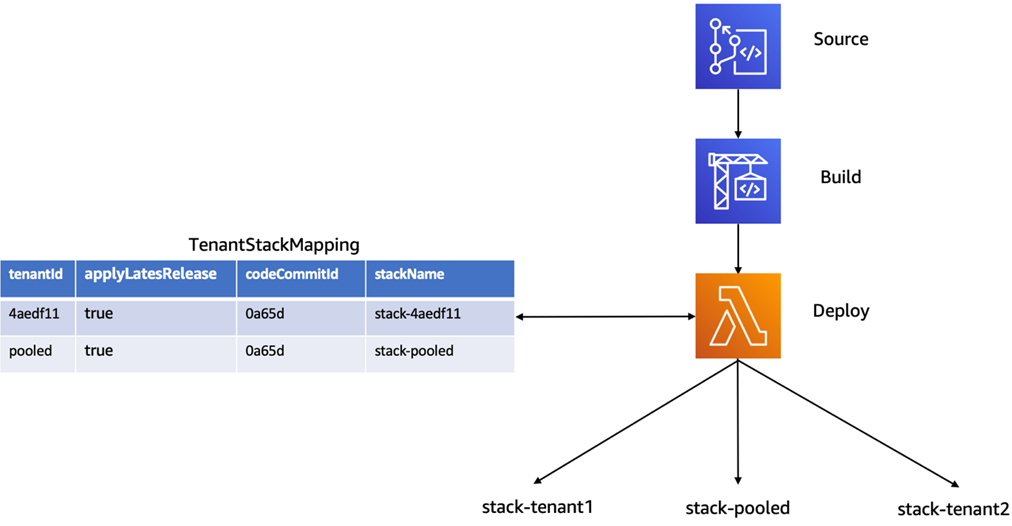
Figure 4 – Tenant CodePipeline.
As part of this deployment experience, you’ll notice we have introduced a TenantStackMapping table. This table is at the heart of the pipeline experience, providing a tenant/tier mapping that controls how tenants are deployed.
Our pool tenant (Basic, Standard, Premium tier tenants) are seeded with entries in this table for each pooled stack as part of baseline infrastructure deployment. Then, as silo (Platinum tier) tenants are onboarded, the system creates an entry inside this table for each silo tenant. The CodePipeline references this table to create and update stacks, as needed.
Final View of the Architecture
Once you have provisioned one or more Platinum tier tenants into the system, your architecture will add new infrastructure to support these tenants (depicted in Figure 5). You’ll now have siloed infrastructure for Platinum tier tenants, along with the pooled infrastructure that gets deployed as part of the initial provisioning script.
In this model, each Platinum tier tenant gets its own Cognito User Pool, a separate API Gateway, separate installations of Lambda functions, and their own set of DynamoDB tables.
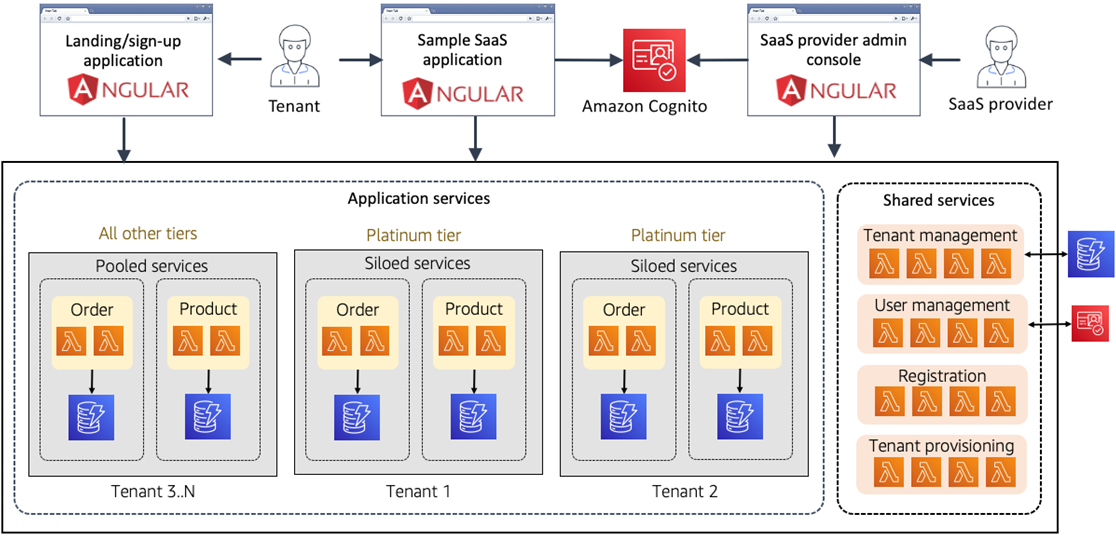
Figure 5 – Final deployment footprint.
API Authorization and Tenant Isolation
The serverless SaaS reference solution leverages various mechanisms to manage security and control tenant activity. In Figure 6, you’ll see the solution relies on a combination of a Lambda authorizer, Amazon Cognito, dynamic identity and access management (IAM) policies, and STS service to implement these controls.
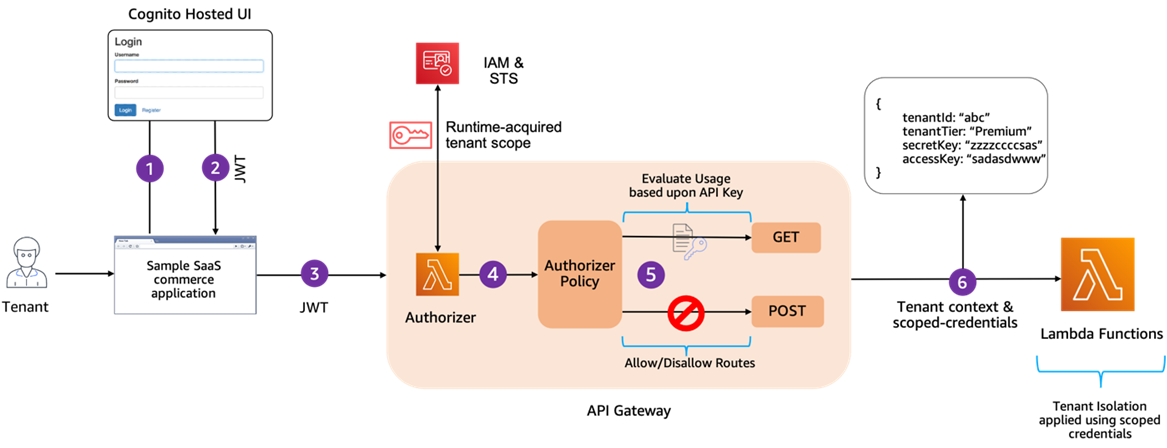
Figure 6 – Authorization flow.
The start of this flow begins with our tenants authenticating with Amazon Cognito, which issues a JWT token (Steps 1 and 2). This JWT is then passed with each request that’s processed by the API Gateway (Step 3). Once you’ve landed in the API Gateway, a Lambda authorizer is used to validate and authorize the request (Step 4).
Within the authorizer, our code will enable/disable routes based on the user’s role, preventing access to any routes that are not valid for that user (Step 5). It will also use the tenant context from the JWT to acquire scoped credentials for tenant, and send these to Lambda functions where they’ll be used to apply tenant-scoped access to resources accessed by the function (Step 6).
Generating Tenant Isolation Policies
As part of the authorization process, the Lambda authorizer generates the short-lived credentials based upon the IAM policies that are specific to that tenant. These policies are dynamically generated by the Lambda authorizer based upon the incoming Tenant Id.
Below is a JSON snippet that provides an example of a tenant isolation policy for a DynamoDB table:
In this snippet the “tenant_id” variable is a placeholder that gets replaced by the Id of the incoming tenant. As a result, you will get a policy that is relevant for that tenant only.
The Lambda authorizer uses this IAM policy to generate fine-grained short-lived credentials using the AssumeRole method of STS service. The outcome of this is a secret access key which has access to the data for that tenant only. The Lambda authorizer provides these short-lived credentials to the downstream Lambda functions as part of the Lambda context.
To add efficiency to this process, the Lambda authorizer caches the credentials for a configurable duration, based upon the JWT token.
Applying Tenant Isolation
The different tiering and deployment models of our application (silo and pool) also influence the isolation story of the serverless SaaS solution. Our pooled tenant tiers rely on the credentials generated by the Lambda authorizer to provide the fine-grained access control that our pooled application services require.
The strategy for silo tenants differs a bit, since we are provisioning separate DynamoDB tables for each tenant. In this case, there’s no need to apply the scoped credentials when accessing a tenant’s DynamoDB table. Instead, the tenant execution role, applied during provisioning of our siloed Lambda functions, restricts access to the specific table provisioned for that tenant.
The following diagrams show this variation. In Figure 7, our isolation model relies on the scoped credentials provided by the authorizer to limit access to DynamoDB items in a pooled DynamoDB table.
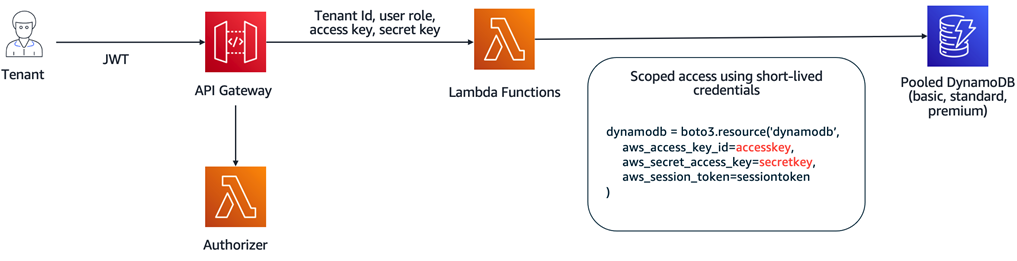
Figure 7 – Tenant isolation – pooled model.
Figure 8, on the other hand, uses the execution role associated with the Lambda function to control access to Amazon DynamoDB tables.
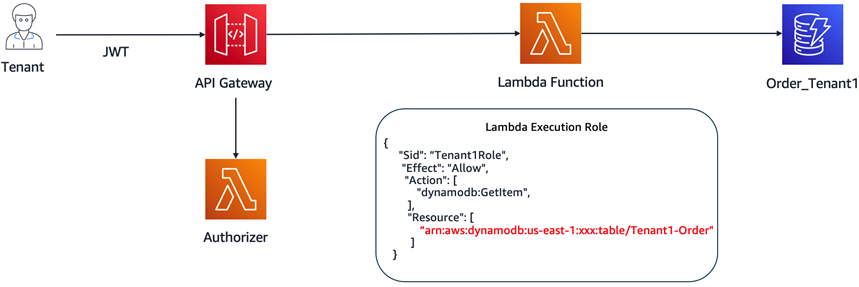
Figure 8 – Tenant isolation – silo model.
Tenant Throttling
It’s common for SaaS providers to offer different experiences to each type (tier) of tenants that are using the system. Throttling is usually part of a broader tiering strategy where basic tier tenants, for example, have throttling policies that limit their ability to impact the experience of higher tier tenants.
The serverless SaaS sample solution applies these tier-based strategies through the API Gateway, which allows you to create usage plans that can be associated with an API key to binds a tier to a given plan. In our case, we have one usage plan for each tenant tier (Basic, Standard, Premium, and Platinum). We have associated separate API keys with each of these usage plans to configure our tier-based throttling limits.
Depending upon your scenario, you might consider having one usage plan per tenant as well. This is usually the case when you have limited number of tenants.
Tenant Observability Using Lambda Layers
As a rule, SaaS solutions try to make development of microservices as simple as possible by introducing libraries or modules that will hide away many of the details associated with multi-tenancy. Logging, metrics, data access—they may all require tenant context, for example, and we don’t want to require developers to create one-off code in each of their services to manage/access/apply this tenant context.
In a serverless environment, we have a natural mechanism that will allow us to introduce common code that can be re-used to address these common multi-tenant needs. The serverless SaaS architecture uses Lambda layers to centralize logging and metrics collection.
In the reference solution, we’ve introduced layers to address some of the common needs of our microservices. A layer, for example, is used to extract a Tenant Id from a JWT token. We’ve also used code in a layer for recording the tenant-aware logs and metrics that are published to CloudWatch.
The reference solution also takes advantage AWS X-Ray for tracing and leverages X-Ray annotations to differentiate the traces by tenant. Finally, you can also use CloudWatch Logs Insight to query the logs and summarize these metrics.
Cost Per Tenant
The ability to log Tenant Id allows you to further understand the consumption of your tenants, especially those which operate in a pool model. As an example, this blog post walk through an approach to determine cost per tenant, based upon Tenant Id inside the CloudWatch logs. It makes uses of AWS Application Cost Profiler (ACP) to get granular cost breakdown of share AWS resources across tenants.
Cost per tenant for silo (Platinum) tenants is relatively simple, since you can use cost allocation tags to get a cost breakdown. This is possible, since the resources for silo tenants are not shared.
Conclusion
In this post, we have discussed how you can create a scalable and secure SaaS solution using AWS serverless services. We have provided guidance on how you can map various features inside AWS serverless services to SaaS best practices.
This solution will give you a head start and serve as a reference point in your SaaS journey. The GitHub repository also comes with a detailed documentation that provides you more information about the inner workings of this reference solution. You’ll find this useful as you dive deep into the architecture and implementation.

About AWS SaaS Factory
AWS SaaS Factory helps organizations at any stage of the SaaS journey. Whether looking to build new products, migrate existing applications, or optimize SaaS solutions on AWS, we can help. Visit the AWS SaaS Factory Insights Hub to discover more technical and business content and best practices.
SaaS builders are encouraged to reach out to their account representative to inquire about engagement models and to work with the AWS SaaS Factory team.
Sign up to stay informed about the latest SaaS on AWS news, resources, and events.