AWS Partner Network (APN) Blog
Data Tokenization with Amazon Athena and Protegrity
By Matt Hutton, VP Cloud Engineering – Protegrity
By Tamara Astakhova, Partner Solution Architect – AWS
 |
Data security has always been an important consideration for organizations when complying with data protection regulations.
When it comes to protecting sensitive data, there are a few options you can choose from. Tokenization is one of the ways to protect sensitive data at rest and preserve data privacy.
Protegrity, an AWS ISV Partner and global leader in data security, has released a serverless User Defined Function (UDF) that adds external data tokenization capabilities to the Amazon Athena platform.
In this post, we will describe how customers can use the Protegrity Athena Protector UDF with the Amazon Athena engine to tokenize or detokenize data at scale. This protects data at rest and maintains the confidentiality of individuals and other sensitive data.
Tokenization is a technique for de-identifying sensitive data at rest while retaining its usefulness. This is particularly vital to companies that deal with Personally Identifiable Information (PII), Payment Card Industry (PCI), and Protected Health Information (PHI).
About Amazon Athena
Amazon Athena is a serverless, federated query service that makes it easy to analyze data in Amazon Simple Storage Services (Amazon S3) using SQL. It can be used to join data across multiple data sources such as Amazon DynamoDB, HBase, Amazon Redshift, or any JDBC-compliant relational database.
Built on the Presto engine, Athena’s federated query engine offers a quick and powerful alternative for analytics without the need to first centralize all of your data into a data warehouse.
Amazon Athena recently released a new feature supporting external UDFs. The Athena team provides a Java SDK for developers to create UDFs to extend the Athena platform and perform useful transformations on data.
Protegrity for Amazon Athena
Protegrity provides data tokenization for Amazon Athena by incorporating tokenization technologies within an external Athena UDF deployed within the serverless AWS Lambda architecture.
This solution scales elastically with Athena’s on-demand and data intensive workloads.
About Tokenization
Tokenization replaces critical values with a meaningless token, and that token acts as a claim check to reveal the original value using the tokenization system.
With PII, for example, organizations can tokenize direct identifiers (national ID, credit card, policy ID) and quasi-identifiers (birthdate, postal codes). Once a record has been de-identified, sensitive values such as bank balance, credit score, or salary data can be maintained in the clear for data analytics, machine learning, or application processing within the enterprise.
Protegrity’s tokenization adds features such as preservation of data type, format, and length. Therefore, sensitive values can be swapped with tokens and stored without altering the database schema or violating field constraints with your applications.
Protegrity’s tokens are also join-preserving. The same value across tables or databases within an enterprise produces the same tokenized value everywhere.
Vault-based tokenization systems use a database, or “vault,” to store the mapping between the sensitive value and corresponding token. Vault-based solutions often suffer operational challenges, however, such as high-availability, performance, and scale.
Protegrity Vaultless Tokenization (PVT) incorporates the tokenization algorithms and key material from a distributed security policy into process memory, eliminating operational challenges. The vaultless nature of Protegrity’s solution incorporates within a Lambda function providing a scalable service when used with Amazon Athena.
The table below shows PII data before and after it has been tokenized. In the first column, data about the individual is in the clear. In the second column, the data is de-identified via tokenization. However, notice some portions of the tokenized values are preserved in the clear, such as the domain of the email address, year of birth, and last four digits of the credit card.
The data element of the security policy can be configured to preserve some analytic usability of data in its tokenized form. Finally, columns three and four show how authorized users in different roles would view the data.
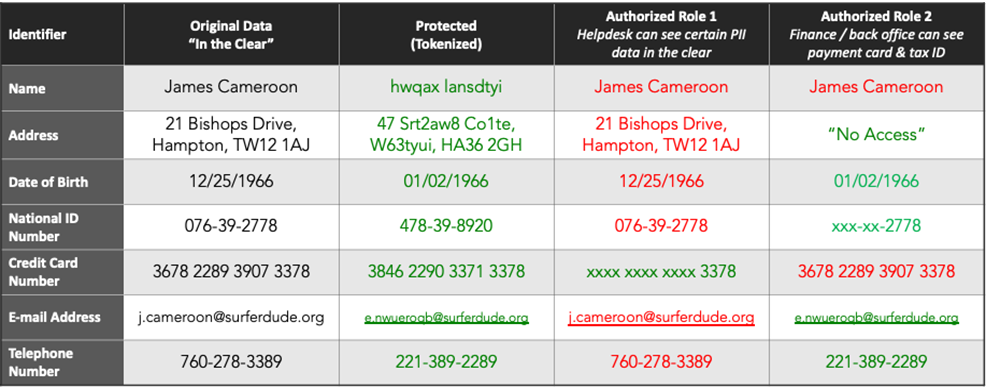

Figure 1 – Example of tokenized data in Protegrity’s solution.
Solution Overview and Architecture
In Amazon Athena, UDFs are invoked from a SQL query. Athena efficiently partitions, parallelizes, and batches requests to the Protegrity UDF, or “Athena Protector” running within a serverless Lambda function. The Protector verifies authorization against the customer’s security policy, and then performs the requested operation. The Athena SQL engine coalesces the final result-set and returns it to the client.
A Protegrity Enterprise Security Administrator (ESA) application is used by an organization to manage the security policy. The security policy contains key material for tokenization operations, data element rules (policies), and authorized users and groups.
In this solution, the security policy is provisioned to the Protegrity Athena Protector by another serverless component called the Protegrity Policy Agent. The Policy Agent periodically synchronizes the policy from an ESA, envelope-encrypts the security policy using AWS Key Management Service (KMS), and deploys the encrypted policy file into a Lambda Layer used by the Athena Protector.
This immutable architecture allows the Protegrity Athena Protector can quickly scale to serve thousands of concurrent requests and serve burst requests from Athena without any runtime dependencies on other applications, such an ESA.
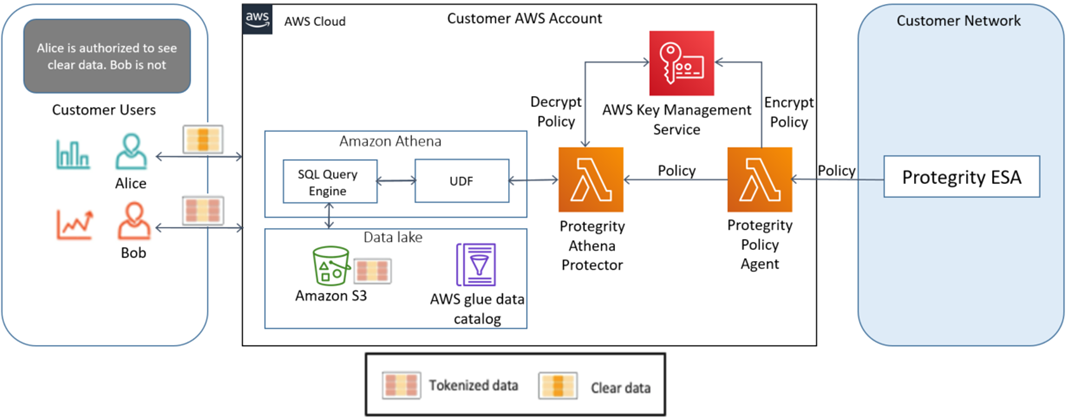
Figure 2 – Amazon Athena and Protegrity architecture.
In a previous blog post on Amazon Redshift with Protegrity, we showed a similar architecture could achieve an impressive 180 million token operations per second.
The following table shows benchmarks with Protegrity and Athena, reaching a maximum throughput of about four million token operations per second after we subtract a start-up baseline for Athena queries.
Median Query Time(s) – # Token Operations:
| Token operations | Protect all columns | Unprotect all columns |
| 1M rows x 6 columns | 18s | 17s |
| 10M rows x 6 columns | 34s | 29s |
| 100M rows x 6 columns | 2m 24s | 2m 11s |
Using Tokenization with Protegrity and Amazon Athena
For this post, we assume there is a running Amazon Athena cluster in your account. If you don’t have one set up, go to the Amazon Athena Getting Started page.
We also assume you have a Protegrity subscription and have set up the Protegrity Athena Protector in your AWS account. The entire solution can be acquired from Protegrity; visit Protegrity + Amazon Athena for additional information.
Usage
Invoking the Protegrity Athena Protector from Athena SQL is fairly intuitive. First, we declare the function we intend to use with the USING clause.

Figure 3 – Amazon Athena UDF declaration for the Protegrity Athena Protector.
The two arguments required for the unprotect function is the column value and the Protegrity security policy data element name. The data element is defined in ESA and specifies any rules for tokenizing the data and key material. This is configured individually by each organization.
The following query shows how a user would unprotect four tokenized fields:
Amazon Athena can also be integrated into an extract, transform, load (ETL) workflow to protect a CSV file containing PII data in the clear. In the example below, we create an external table which maps to an unprotected file on Amazon S3.
Now that we have an external table, we can use Athena SQL with the Protegrity protect function to create a new table with the protected values. Once the new table is written, we can remove the file with PII data in the clear.
Performance Tuning
Amazon CloudWatch Metrics is a useful tool for understanding the performance characteristics of the Athena Protector. Open the Lambda function and navigate to the Monitor tab to access this feature.
The Athena query that produced the dashboard in the screenshot below performed 60 million tokenization operations. We can see this resulted in over 60,000 function invocations from Athena, reaching a peak of 900 concurrent requests.
There were a large number of request throttles by the Lambda service. A throttle means Athena received a 429 (“too many requests”) exception and should retry the request.
AWS sets default quotas for concurrent executions that apply across each account and region. If the quota is exceeded, the Lambda service will start to throttle requests. We can resolve the performance impact of throttles by requesting a quota increase for the region where the function resides in. See Service Quotas in the AWS Management Console.
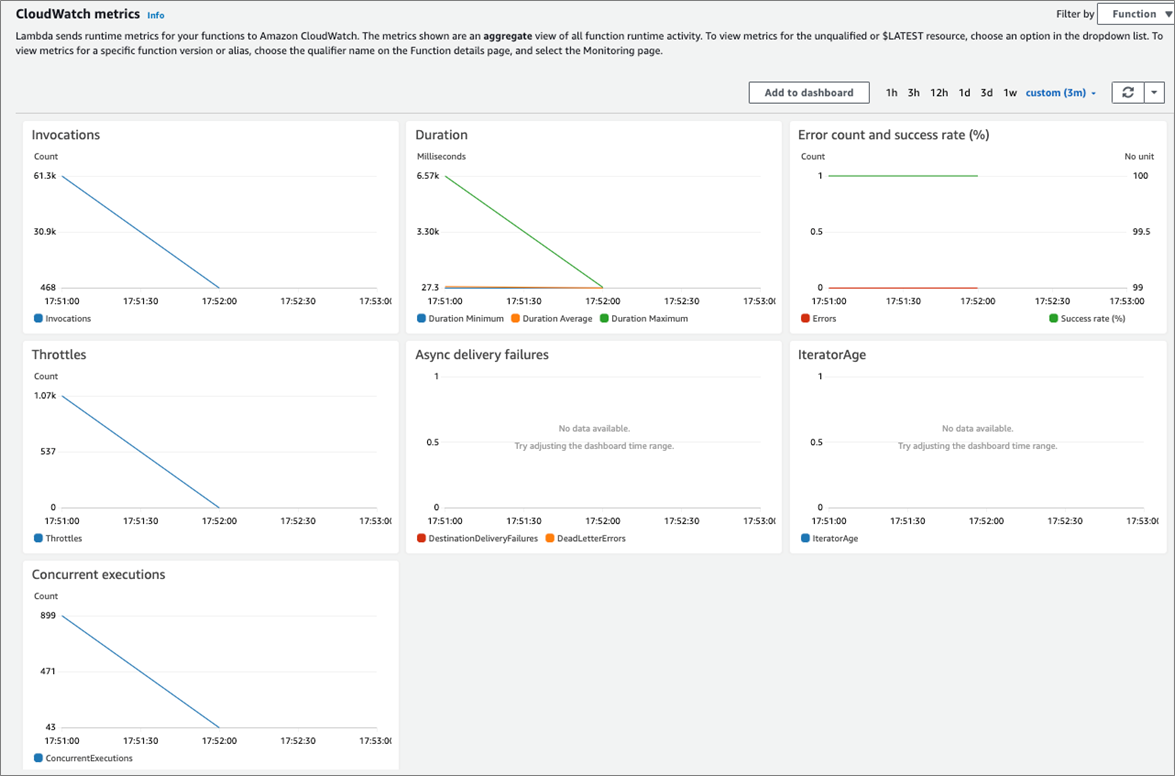
Figure 4 – CloudWatch Metrics for Protegrity Athena Protector Lambda.
Logging and Audit Records
Each invocation of the Protegrity Athena Protector Lambda is recorded in Amazon CloudWatch Logs. These logs can be searched and analyzed via CloudWatch Logs Insights.
Any authorization errors, such as an illegal access attempt, will be visible in the CloudWatch logs. Audit records are in JSON format.
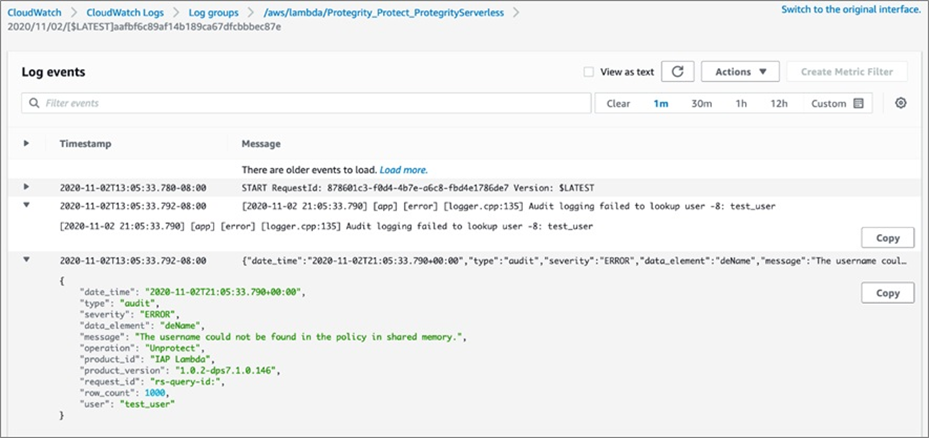
Figure 5 – Amazon CloudWatch Logs unauthorized user.
Conclusion
By performing tokenization operations at scale using a combination of Amazon Athena SQL and Protegrity Athena Protector UDF, customers can protect sensitive data at rest and maintain data privacy. With Protegrity, only users with the appropriate roles may re-identify tokenized values that enhancing data protection capabilities.
For more details on how to create an Amazon Athena Lambda UDF, refer to the documentation. To learn more about the Protegrity Athena Protector, visit the Protegrity website.
.

.
Protegrity – AWS Partner Spotlight
Protegrity is an AWS ISV Partner that provides fine-grained data protection capabilities (tokenization, encryption, masking) for sensitive data and compliance.
Contact Protegrity | Partner Overview
*Already worked with Protegrity? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.