AWS Partner Network (APN) Blog
How WSP Digital Improves Geospatial Pipeline Efficiency with AWS Step Functions and AWS Batch
By Shiddy Mwinyi, Solutions Architect – AWS
By Katherine Vishnevskaya, Partner Solutions Architect – AWS
By Christine Seeliger, Data Science and Analytics Technical Lead – WSP Digital
By Paul Borg, Head of DevOps – WSP Digital
 |
| WSP Digital |
 |
Geospatial extract, transform, and load (ETL) pipelines prepare data for business analysis and insights, enabling leaders to make informed decisions.
Despite their value, however, these pipelines can present significant challenges. For example, they often run on a single virtual machine or use expensive third-party applications, adding licensing costs to cloud computing costs.
Geospatial ETL pipelines can also be difficult to tune and manage at scale, and although they can be event-triggered or scheduled, manual starting is not unusual. The pipelines frequently take days to complete because of the computationally expensive spatial operations.
In this post, experts from Amazon Web Services (AWS) and WSP Digital walk through how to migrate a geospatial pipeline to AWS Step Functions and AWS Batch to simplify pipeline management while improving performance and costs.
WSP Digital is an AWS Partner that designs and builds intuitive mobile and web-based software solutions. WSP is a leading engineering and professional services firm, and WSP Digital incorporates the digital technology specializations of WSP, including geospatial, data and analytics, visualization, digital engineering, software engineering and systems integration, and platform engineering.
Key Challenges
To illustrate, let’s look at an initial geospatial ETL pipeline which ran on Python/Django with separate modules for ingestion, processing, and analysis using Celery, a distributed task system, to parallelize the process. The dataset was recomputed monthly and comprised roughly six million geospatial features, each with about 60 properties.
Because all processes ran through Celery on a single Amazon Elastic Compute Cloud (Amazon EC2) instance, there was a single point of failure. The workflows featured complex dependencies and required more robust, tailored solutions that could be managed at scale.
To modernize the pipeline, we considered dependencies between modules, logging requirements and notifications, testing, and validation between ETL steps, cost and time between activity triggers, and the ability to scale and manage complex workflows.
Improving Pipeline Processing with AWS Batch
To address the single point of failure challenge, we selected AWS Batch for pipeline processing. It’s a fully managed batch computing service that plans, schedules, and runs containerized batch workloads and scales to meet requirements. With AWS Batch, you can also opt for spot instances for cost efficiency.
Our first step was to decouple the pipeline from the main application. We needed to create a separate container with a minimalistic Django build containing database and geospatial modules only.
We configured the AWS Batch service by following these steps:
- Defining AWS Batch compute environments: We used a mix of Amazon EC2 and AWS Fargate, a pay-as-you-go compute engine, for the various pipeline components. The computing choice was made based on the pipeline component’s memory and CPU requirements.
- Creating AWS Batch job definitions: We created separate job definitions for Fargate and EC2 executions, respectively. The job definition was used to run the different parts of the pipeline using parameterized Django management commands.
- Creating AWS Batch job queue: Both job definitions were then mapped to the respective computing environments using the job queue.
Simplified Orchestration Using AWS Step Functions
Once the compute processing environments were created in AWS Batch, the next stage was the end-to-end orchestration of the pipeline. We used AWS Step Functions to achieve this, as it’s a visual workflow service that helps developers build distributed applications, automate processes, orchestrate microservices, and create data and machine learning (ML) pipelines.
There are several ways to start an AWS Step Functions workflow, including via an API gateway, on a schedule or based on a particular event via Amazon EventBridge, from an AWS Lambda function, or from another step function. In our case, we set a monthly schedule via Amazon EventBridge.
We split our workflow into separate step functions. These flows are managed by a main step function dealing with notifications, database tuning, and error handling. Since we have a long-running ETL workflow, we use a standard workflow. For Internet of Things (IoT) data ingestion or mobile application backends, express workflows would be preferred.

Figure 1 – Main workflow from start to finish.
Branching Off Subsequent Workflows
Following the primary workflow shown in Figure 1, three subsequent workflows emerge. These child workflows are: 1) ingestion, 2) feature dataset generation, and 3) aggregation.
Ingestion Workflow
We start by invoking the child AWS Step Function that ingests the data from Amazon Simple Storage Service (Amazon S3). Prior to ingestion kicking off, the step function runs a database migration process via the Migrate step, as illustrated below.
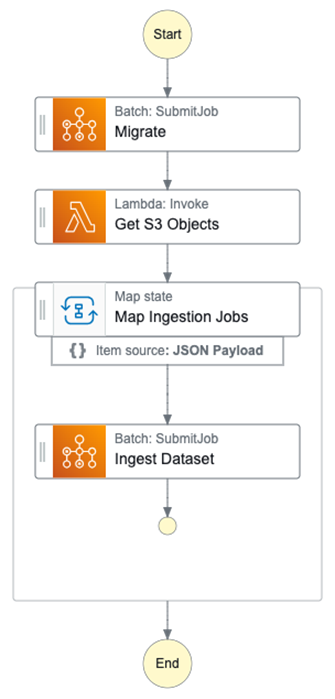
Figure 2 – Steps to ingest the dataset.
Using the sync service integration pattern ensures that AWS Step Functions can wait for a request to complete before progressing to the next state. The ingestion step function invokes a Lambda function to list incoming new datasets in S3. The output is used to create a set of AWS jobs for each dataset to handle its ingestion into the system.
After the ingestion step function run is complete, scale up the database before transforming and loading data to account for more compute- and memory-intensive processing.
We use the Amazon RDS API (“IncreaseDBInstance” operation) for this step, checking the status every minute to see when the database instance type has changed via the “Check_DB_Processing” step.
As soon as the database instance has scaled up, kick off the subsequent processing steps.
Feature Generation Workflow
This step function is illustrated in Figure 3. Notably, we use a Lambda function to split jobs into batches. The output of the Lambda function inputs to a map state that launches multiple instances of the AWS Batch job, each taking a different batch parameter as command line input. This allows us to parallelize this process.

Figure 3 – Steps to achieve feature generation.
Once the feature dataset is generated, we run both components of the aggregation workflow.
Vectorfile and Aggregation Workflow
The aggregation workflow consists of two different processes running in parallel:
- Vectorfile generation: This step generates a set of vector tiles to visualize the feature dataset created in the previous workflow.
- Spatial aggregations: This step computes different spatial aggregations. This workflow is less compute- and memory-intensive on the database, so the master step function scales the database down before invoking it, as illustrated in Figure 1 above..
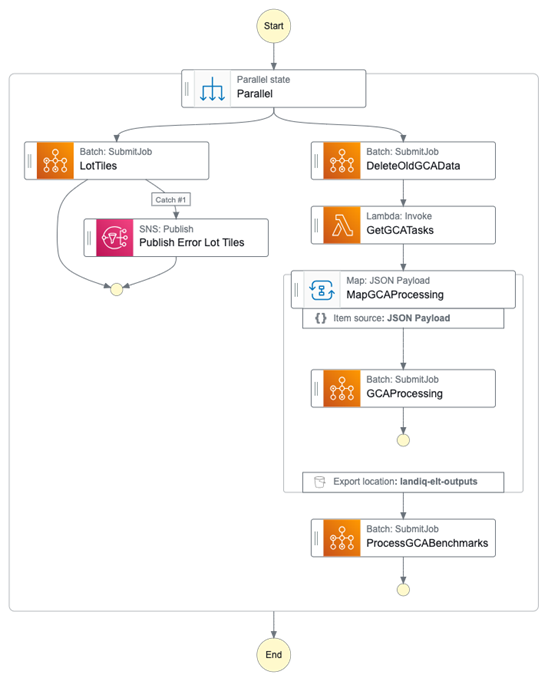
Figure 4 – Steps to achieve vectorfile and aggregation.
We use the AWS Step Functions Parallel execution feature, which reduces overall running time for our workflow and allows us to scale up easily.
The two processes in this workflow run in separate AWS Batch jobs and are independent from each other, so they use different resources based on the needs of each process. We use the same Lambda job and map state from the previous workflow for orchestration and parallelization.
After the aggregation computations are done and the vector tiles are created, the master workflow decreases the database instance and finishes the workflow. The dataset is then ready to be released into the testing environment using AWS CodePipeline.
If at any point we encounter an error, it will be caught by the step function’s native error-handling mechanism. We designed the error-handling step to send a notification to an Amazon Simple Notification Service (SNS) topic and finish the workflow by decreasing the database instance, meaning that no resources are wasted when not in use.
In addition, the AWS Step Functions console makes identifying the error cause easy, and jobs and workflows can be restarted after the issues are fixed.
Realizing the Benefits of Migration
Migrating to AWS Batch and AWS Step Functions has transformed the way WSP Digital handles data processing and orchestration, enabling streamlined and automated workflows. It has shown substantial benefits in terms of efficiency, scalability, and reliability.
Since making this update, the team has cut pipeline processing time significantly. Before moving to AWS Batch and Step Functions, processing times varied from five to nine days due to the requirements for manual interference and lack of notification processes. Now, the pipeline runs reliably within four days.
In addition, debugging has become a lot faster since it’s easy and straightforward to find the relevant logs for each job that is run.
As an additional benefit of using AWS Batch, WSP Digital now has a more fine-grained control over each separate task and is able to allocate different compute resources to each task. This allows WSP Digital to save costs compared to the approach of running everything on one large Amazon EC2 instance.
Integration of AWS Step Functions into the data loading process has simplified the coordination of complex workflows. Visualizing the flow of data load activities offers better control over each step. The retry action and error handling features of Step Functions results in improved data load efficiency, quality, and reliability.
Overall, this migration has greatly improved our geospatial pipeline management.
.

.
WSP Digital – AWS Partner Spotlight
WSP Digital is an AWS Partner that designs and builds intuitive mobile and web-based software solutions. WSP is a leading engineering and professional services firm, and WSP Digital incorporates the digital technology specializations of WSP, including geospatial, data and analytics, visualization, and more.