AWS Partner Network (APN) Blog
Migrating Elasticsearch on Amazon EC2 to Modernized, Multi-Tenant Amazon OpenSearch Service Architecture
By Benjamin Draper, Solution Architect – NTT DATA Services
By Irshad A Buchh, Principal Solutions Architect – AWS
 |
| NTT DATA Services |
 |
For a recent project, NTT DATA Services was asked to architect and design the migration of a customer’s backend search tool used by two of its applications. Both applications were leveraging Elasticsearch for data storage.
In this post, we shall explore how NTT DATA used some of the DevOps pillars to implement migrations using an active migration strategy.
NTT DATA Services is an AWS Premier Tier Services Partner with Competencies in several areas including Migration and DevOps. NTT DATA helps customers plan, assess, develop, and deliver Amazon Web Services (AWS) solutions that transform the business.
Requirements
NTT DATA’s customer was using an older version of Elasticsearch for its backend data storage for two separate applications. Both applications had hundreds of users across multiple regions.
The goal of this project was to move from individual Elasticsearch instances on Amazon Elastic Compute Cloud (Amazon EC2) to a single multi-tenant hosted Elasticsearch solution per region—in this case, Amazon OpenSearch Service.
Data integrity was of the utmost priority for the customer along with security and performance. Several other concerns and major challenges encountered are listed below:
- 100% data integrity required: The data must match between the incumbent and new implementation without exception.
- 5 major version upgrades: The Elasticsearch software version was out of date by five major versions, requiring data transformation to be able to successfully load historic data into the new datastore format.
- Downtime: With an active migration approach, downtime needed to be minimized and scheduled properly with each customer to ensure a smooth transition.
- Multi-tenant security: In the new paradigm, customers would be sharing the Amazon OpenSearch Service infrastructure which necessitated finely controlled security permissions for each OpenSearch Service index, ensuring proper data segregation for all the customers.
DevOps Pillars
Having thousands of users, the customer made this a challenging lift. NTT DATA leveraged several pillars of DevOps to achieve successful migrations of both the data and infrastructure.
Automation
Throughout the migration, it was key to have reliable and scalable automation in place. Strong automation provides frontend development teams the confidence to add features in an agile way. Good automation provided the teams with confidence so they were able to rapidly change cluster configurations with the push-button click of an idempotent pipeline.
Alignment
It’s essential to foster strong alignment between all teams involved in a migration project; in this case, it was the frontend, operational, and DevOps teams. This alignment ensures smooth transitions from old to new data stores, and ensures all internal teams have their top priority concerns addressed prior to migration.
For example, the concerns of the application team being able to interact with a new API are just as valid and important as the operations team asking for streamlined notifications from the new data backend.
Testing
With data integrity being paramount, it was essential to have the necessary testing harness in place to ensure data was migrated successfully. This included automated document checkers and index counters along with a suite of Python modules to validate the datasets between backends were identical.
Testing also provided assurance the new infrastructure was configured correctly, ensuring tenants’ security permissions were scoped tightly to their own datasets.
Infrastructure as Code (IaC)
IaC allowed the development team to efficiently tweak and update the size and performance configuration of the new clusters along with making any security changes in a safe and effective manner.
Push-button automation was leveraged alongside Terraform to ensure the customer had full customization of their new infrastructure. Pipelines were designed to be idempotent to ensure no unintended changes were enacted.
Prerequisites
- Automation must exist to lift the data out of the old backend and transfer it to the new backend, along with automation to validate the integrity of the data once transferred. This was achieved using a combination of Ansible and Python to fully automate index creation in the new backend and data migration.
- A new version of the application must be written to handle any API changes that occur when communicating with the new backend.
- Downtime window must be scheduled with the customer for the data migration to be performed offline.
- IaC and corresponding testing must be developed for new backed infrastructure.
- Existing workflows for customer onboarding and data manipulation must be updated to work with the new storage backend.
- Code must be idempotent and leave the system in a stable state if any failures or errors occurred during onboarding or migration.
- Checks and balances must be in place and automated to ensure data integrity of the migration, and document checks must test for quantity of documents per index as well as document IDs.
- Security checks must be performed to ensure the correct user and role are provisioned with the correct access schema. Users need to be locked down to only view their own indices.
- Automation pipeline must be user-friendly to allow the customer to quickly train engineers on migration workflows.
- Error messages must be clear and concise to allow migration engineers to quickly troubleshoot and triage any incidents that may occur during the setup and execution of a migration.
- With thousands of customers over 10 different regions, the code must be customizable and flexible enough to work across multiple different AWS regions with different Amazon OpenSearch Service clusters.
Strategy and Architecture
There were two applications that required migration, and for several reasons NTT DATA collaborated with the customer to use an active migration.
NTT DATA’s DevOps team created a push-button data migration pipeline that allowed the customer to fully automate the migration of data from Amazon EC2 into OpenSearch Service. This was achieved using a combination of Ansible, Python, Amazon Managed Streaming for Apache Kafka (Amazon MSK), Logstash, and AWS Systems Manager Run Command.
All of the above DevOps pillars were in play for the migration pipeline. The code would create all of the necessary indices in the multi-tenant OpenSearch Service cluster, and then run a few tests to ensure the indices were matching.
The code also created the necessary users and roles in OpenSearch Service with the proper security profile, ensuring each newly-onboarded customer had fully locked down permissions. One of the most challenging aspects of the project was making sure each customer could only see their own indices. This represented a major paradigm shift, moving from single-tenant EC2 to multi-tenant OpenSearch Service.
The migration code was designed to be idempotent, meaning the system was not affected in any negative way if a failure occurred during the migration process. Operations that were needed to safely roll back were also automated, providing the customer with the ability to migrate and cleanly deprecate customers at will.
NTT DATA’s DevOps team provided the customer with several automation pipelines for checking data integrity, creating and deprecating users, and updating the OpenSearch Service cluster configuration. These automation pipelines allowed them to effectively modify their clusters without disrupting production operations. They could also test these pipelines safely in a development environment, meaning they could add new configurations and features quickly.
Once confirmed, the pipeline started initiating the data migration via Run Command. This would take a target customer as input and automation would handle the rest.
Logstash would pull documents out of the EC2 instances and put them into an Amazon MSK data queue. Logstash was an ideal choice for this portion of the migration pipeline, as it allowed the DevOps team to prune the old document base and only migrating data that was deemed appropriate by the customer. From there, a separate version of Logstash would then pull from Amazon MSK, manipulate documents as necessary, and send to the correct index in OpenSearch Service.
Two separate versions of Logstash were used on either side of Amazon MSK in order to handle the five major version upgrade that separated the EC2 system from the target OpenSearch Service system.
Once the OpenSearch Service cluster was fully hydrated with data, another script would handle the data integrity check, querying the EC2 instance for random documents and ensuring those same document IDs were present in the target OpenSearch Service cluster.
In addition, this integrity check would perform a document count operation. Counting all documents from the EC2 system and ensuring there was a 1:1 match with the number of documents migrated to OpenSearch Service.
If at any point in these checks an error occurred, the scripts would stop, provide the migration engineer with a detailed report of the errors, and give the option to keep the current state for troubleshooting or safely roll back the migration and return the OpenSearch Service cluster to the original state.
Once the pipeline was fully automated, the customer could schedule downtime for their customers and perform the migrations as needed.
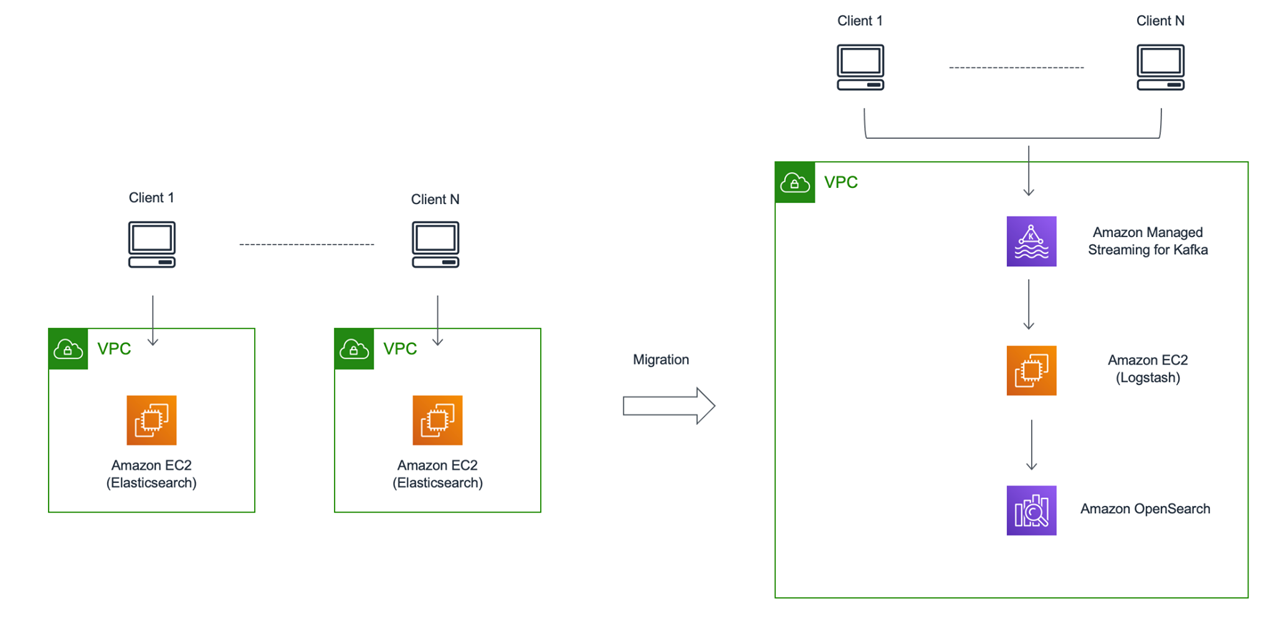
Figure 1 – Former and target state architecture.
Active Migration Execution
In order to execute the active data migration, the NTT DATA DevOps team worked with the customer to follow the following migration pattern. Automation would shut down the application and pull data out of EC2 and push into OpenSearch Service.
After verification, automation would then restart the application using OpenSearch Service as the backend. This provided the customer with maximal control over the data migration, allowing for transformation in flight as needed, with the downside being that it would require windows of application downtime to be scheduled with the customers’ own clients.
Conclusion
The pillars of DevOps were essential to NTT DATA’s strategy for having successful migrations for the applications discussed in this post. Automation, infrastructure as code (IaC), testing, and alignment fostered an agile development environment, freeing up the application development teams to focus on adding new features and to not get bogged down with aging infrastructure and slow manual testing of their datasets.
For migrations, implementing DevOps at scale meant secure and performant customers and ultimately successful migration of data and infrastructure. Automation provided the customer the ability to rapidly test migrations and different configurations of their Amazon OpenSearch Service clusters to ensure they were maximizing performance and following security best practices.
.

.
NTT DATA Services – AWS Partner Spotlight
NTT DATA Services is an AWS Premier Tier Services Partner that helps customers plan, assess, develop, and deliver AWS solutions that transform the business.