AWS Partner Network (APN) Blog
Using Amazon AppFlow to Achieve Bi-Directional Sync Between Salesforce and Amazon RDS for PostgreSQL
By Tejpal Chadha, GM – AWS Cloud Services & Solutions at Trantor
By Anirudh Rautela, Technical Lead at Trantor
By Raman Bedi, Technical Architect at Trantor
By Avijit Goswami, Principal Solutions Architect at AWS
 |
 |
Many software-as-a-service (SaaS) applications boast of microservices as a means to divide a monolithic architecture into easily manageable solutions.
Sometimes these microservices have their own databases. To maintain data consistency across the system, you need to implement a data synchronization system between source and target data persistence layers.
Amazon AppFlow is a fully managed integration service that enables you to securely transfer data between SaaS and cloud applications like Salesforce, Marketo, Slack, and ServiceNow, as well as AWS services like Amazon S3 and Amazon Redshift, in just a few clicks.
In this post, you will learn how Trantor has developed a solution using Amazon AppFlow to easily synchronize the data between Salesforce and Amazon RDS for PostgreSQL in near real-time.
Trantor is an AWS Advanced Consulting Partner specializing in security and compliance of Amazon Web Services (AWS) infrastructure and customers’ deployed application.
Solution Overview
Trantor’s solution is in production at, among others, a FinTech client who offers loans and leverages Salesforce along with their unique backend PostgreSQL database to track status, updates, and lender details in real-time before a decision is made.
For FinTech customers, the need for a data replication system can be of utmost importance.
Our customer had the use-case of synchronizing data between Salesforce and PostgreSQL. The customer wanted to manage the lending opportunities and CRM activities in Salesforce, but wanted to manage the borrower’s application running on Ruby on Rails using a PostgreSQL database.
The data synchronization system included bi-directional and uni-directional syncing of data across multiple Salesforce and PostgreSQL tables. The previous solution was based on a third-party tool for data synchronization that had limitations impacting cost and functionality that led to the creation of this data synchronization system using AWS services.
“Trantor’s Amazon AppFlow-based solution to sync SaaS data with Amazon RDS has helped our customers increase the data synchronization frequency by 10 times, while reducing operational overhead and cost spent on third-party tools by 30 percent,” says Sanjul Saxena, VP – Professional Services at Trantor.
“For startup organizations with limited resources, AppFlow’s ease of deployment, data transformation capability, and cost savings benefits for achieving data connectivity is very attractive,” adds Saxena.
Synchronization Requirement and Key Challenges
Trantor’s solution is designed to build a data synchronization system that enables bi-directional sync between Salesforce and the Ruby on Rails application.
The synchronization system should support the following features:
- Create, update, delete, and undelete operations from Salesforce.
- Update and delete operations from Ruby on Rails.
- Support field-level synchronization.
- Error logs and notifications.
The main challenges faced while using a third-party tool for the bi-directional sync includes:
- Low ROI, even for a few tables being synced.
- No option of customizing field-level synchronization.
- No insights into error logs being generated for the process.
- No control over the time taken for the resolution of issues.
Proposed Solution Architecture
In the following sections, we describe the details of implementation and challenges faced while implementing the Salesforce to Amazon RDS for PostgreSQL synchronization and vice versa.
The challenges faced are different and unique in each direction due to the difference in source systems.
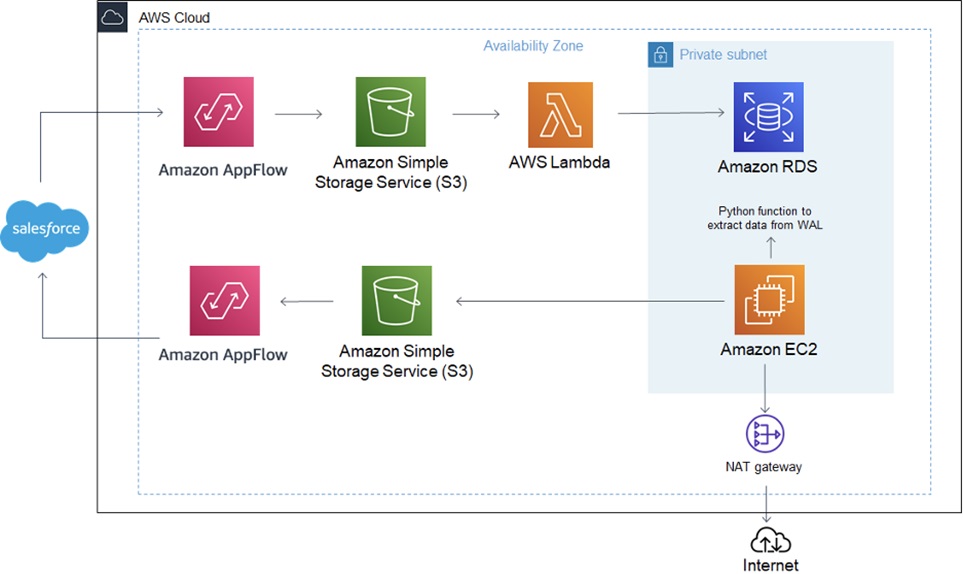
Figure 1 – Bi-directional replication architecture.
Implementation Details
The implementation consists of two data synchronization flows:
- Salesforce to Amazon RDS PostgreSQL
- Amazon RDS PostgreSQL to Salesforce
Salesforce to Amazon RDS PostgreSQL Synchronization
Amazon AppFlow runs every minute (customizable) to fetch changes that occur on a Salesforce object. For any insert, update or delete on Salesforce objects, Amazon AppFlow dumps the changes into an Amazon Simple Storage Service (Amazon S3) bucket.
Using Amazon S3 event notifications, an AWS Lambda custom Python script is triggered which reads the JSON dumped in the S3 bucket and replicates the changes to the target Amazon RDS for PostgreSQL database.
Advantages of Using AWS Lambda
The earlier implementation which relied on a third-party tool had a replication lag of 10 minutes. This meant the data generated in Salesforce could have taken a maximum of 10 minutes to be reflected in the corresponding PostgreSQL database. This is huge considering the fact that replication systems should be as close as possible to a real-time sync.
Using AWS Lambda, Trantor was able to bring down the time to one minute using their custom replication system. AppFlow generates CSV files for changes on Salesforce that Lambda reads and pushes to PostgreSQL all under a minute.

Figure 2 – Amazon S3 to PostgreSQL data replication.
When using Lambda to replicate data from S3 to PostgreSQL, it provides advantages such as:
- Horizontal scaling: In the event an S3 bucket receives too many files, Lambda helps serve the high load requests in parallel due to the concurrent nature of Lambda functions.
- Near real-time data replication: Lambda springs into action as soon as the files are written to S3, which means the data is replicated to the destination as soon as it arrives. Hence, users see only a fraction of replication lag.
Amazon RDS PostgreSQL to Salesforce Synchronization
For data flow from Amazon RDS PostgreSQL to Salesforce, you need to enable logical replication which lets the server store additional information in WAL (Write-Ahead Logging) on Amazon RDS for PostgreSQL.
A custom Python script on the Amazon Elastic Compute Cloud (Amazon EC2) instance constantly reads the WAL for changes.
If there is any supported operation (update/delete), a CSV file is dumped in an S3 bucket containing the changed record details. Amazon AppFlow checks the S3 bucket every minute and pushes the data to Salesforce.
Why AWS Lambda Was Replaced by Python on Amazon EC2
When posting data from Amazon RDS for PostgreSQL to Salesforce, you can use a Python script running on EC2 and not using Lambda.
To understand this, you have to understand how things work under the hood. WAL is a method by which PostgreSQL ensures data integrity. Any changes to data are logged to a transaction log file sequentially. In the event of a crash, you can simply use the transaction log file to apply the changes back to the database.
On enabling logical replication, PostgreSQL starts logging all of the DML events to the transaction log. You can use synchronous streaming replication protocol, meaning that script continuously reads WAL for changes.
To maintain a continuous stream of changes for their solution, Trantor had to remove Lambda as it has the following shortcomings:
- Max timeout: A Lambda function can exist for a maximum period of 15 minutes.
- Resume stream: For continuous streaming of data, you cannot stop the Lambda function gracefully, and then reinstate a new Lambda and resume the stream.
For solving the above-mentioned issues, Trantor chose to run Python scripts in an Amazon EC2 instance. The script continuously reads WAL for changes, writes a CSV file, and pushes it to Amazon S3.
Major Challenges While Using WAL
Some of the challenges faced during replication of data from Amazon RDS for PostgreSQL to Salesforce includes:
De-duplication in case of bi-directional sync
When a new record ‘X’ is created on Salesforce, Amazon AppFlow seeks the changes and dumps a CSV to S3 containing the new record. Lambda reads the CSV file and writes the data to PostgreSQL.
As soon as the data is inserted into PostgreSQL, the WAL reports an insert operation that’s read by the Python script running on EC2, and it writes the data to the S3 bucket. AppFlow reads the CSV and pushes the data to Salesforce, creating an infinite loop where the same data is being updated to both the data sources again and again.
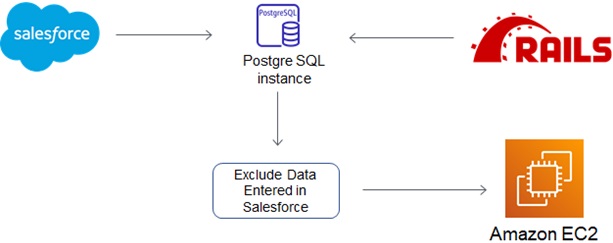
Figure 3 – Data filtration.
Wal2json plugin provides the functionality of filtering records from the origin. Using an origin, we can always segregate changes being made to the PostgreSQL database by the Salesforce data replication process vs. any other changes being made to the same database. Trantor created and utilized a unique origin when ingesting changes from Salesforce to PostgreSQL.
Whenever any records were inserted, updated, or deleted from Salesforce, the changes were filtered when inserting into PostgreSQL. Hence, the Python script on the EC2 instance only read those changes, which were performed from the Ruby on Rails application and replicated them further to Salesforce.
Storage issues with WAL
A transaction log or WAL in PostgreSQL is divided into files of 16 megabytes, which is known as the WAL segment. The size of the WAL segment is configurable. As data keeps coming into PostgreSQL, the WAL segments keep growing.
PostgreSQL creates a checkpoint containing the REDO point from where the WAL would be replayed in case the server crashes, or any other issue is faced. After the creation of this point, PostgreSQL flushes the previous segments. Failure to report the feedback results in ever-increasing WAL size, which would ultimately causing storage issues.
For this to function correctly, you need to send feedback to flush the Log Sequence Number (LSN) with the current LSN of the wall.
Previously, Trantor was only sending the feedback to flush the LSN when any data was inserted, updated, or deleted in the Salesforce schema. They modified the Python script to send feedback for flushing the LSN whenever data is inserted into any table in the database. This ensures PostgreSQL has the updated LSN to minimize replication lag in the logical slot.
Custom Enhancement
Trantor has done some enhancements to support the delete feature from Amazon RDS for PostgreSQL and replicate it to Salesforce, which was not supported by the third-party tool.
If you delete any data from PostgreSQL, it would not be deleted from Salesforce. To achieve this, they used the simple_salesforce library for Python.
As previously mentioned, the custom Python script reads WAL for any DML operations. As soon as it encounters a delete operation, the script initializes a Salesforce object based on the table on which the delete operation is performed, and uses Salesforce API to soft delete the object from Salesforce.
The library also supports hard delete if required based on the business requirement.
Conclusion
The need for bi-directional syncing arises when there is frequent change of data between source and destination, and the two sources should remain consistent and synced.
The simple and easy-to-use user interface (UI) on Amazon AppFlow allows you to set up bi-directional syncing between various SaaS applications and AWS services. Amazon AppFlow also supports analytical databases like Amazon Redshift, providing low latency and high volume data analytics.
The architecture described in this post helped Trantor to create a bi-directional synchronization system using AWS services. The main highlight of the implementation was Amazon AppFlow, which helped to seamlessly integrate with a SaaS application (Salesforce in Trantor’s case) using an intuitive UI.
AWS provided the means to effectively and efficiently synchronize data between two different data sources with minimal complexity.
.

.
Trantor – AWS Partner Spotlight
Trantor is an AWS Select Consulting Partner whose certified AWS experts deliver compliant and cost-effective cloud solutions.
Contact Trantor | Partner Overview
*Already worked with Trantor? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.