AWS Architecture Blog
Category: AWS Glue

Designing a Successful Pilot Phase for Your Cloud Migration
Pilot phases, or pilots, as we will call them from now on, should be conducted to test and find the positive and negative aspects of a particular use case, design pattern, or application migration approach. They allow you to validate the foundation of your architecture (for example, with a landing zone governed by AWS Control […]

NLX is Helping Travelers Amid Disruption with AI-Powered Automation
This post was co-written by Andrei Papancea and Vlad Papancea of NLX and Sekhar Mallipeddi Travel impacts brought by the global pandemic left several airlines experiencing frequent flight disruptions, which increased flight scheduling change notifications being made to affected travelers. Every month, tens of thousands of passengers and related flight crew have to be contacted […]

Reduce Operational Load using AWS Managed Services for your Data Solutions
As the volume of customers’ data grows, companies are realizing the benefits that data has for their business. Amazon Web Services (AWS) offers many database and analytics services, which give companies the ability to build complex data management workloads. At the same time, these services can reduce the operational overhead compared to traditional operations. Using […]

Amazon MSK Backup for Archival, Replay, or Analytics
Amazon MSK is a fully managed service that helps you build and run applications that use Apache Kafka to process streaming data. Apache Kafka is an open-source platform for building real-time streaming data pipelines and applications. With Amazon MSK, you can use native Apache Kafka APIs to populate data lakes. You can also stream changes to […]

Automating Recommendation Engine Training with Amazon Personalize and AWS Glue
Customers from startups to enterprises observe increased revenue when personalizing customer interactions. Still, many companies are not yet leveraging the power of personalization, or, are relying solely on rule-based strategies. Those strategies are effort-intensive to maintain and not effective. Common reasons for not launching machine learning (ML) based personalization projects include: the complexity of aggregating […]
Mercado Libre: How to Block Malicious Traffic in a Dynamic Environment
Blog post contributors: Pablo Garbossa and Federico Alliani of Mercado Libre Introduction Mercado Libre (MELI) is the leading e-commerce and FinTech company in Latin America. We have a presence in 18 countries across Latin America, and our mission is to democratize commerce and payments to impact the development of the region. We manage an ecosystem […]
Architecting a Data Lake for Higher Education Student Analytics
One of the keys to identifying timely and impactful actions is having enough raw material to work with. However, this up-to-date information typically lives in the databases that sit behind several different applications. One of the first steps to finding data-driven insights is gathering that information into a single store that an analyst can use […]

Store, Protect, Optimize Your Healthcare Data with AWS: Part 2
Leveraging Analytics and Machine Learning Tools for Readmissions Prediction This blog post was co-authored by Ujjwal Ratan, a senior AI/ML solutions architect on the global life sciences team. In Part 1, we looked at various options to ingest and store sensitive healthcare data using AWS. The post described our shared responsibility model and provided a […]
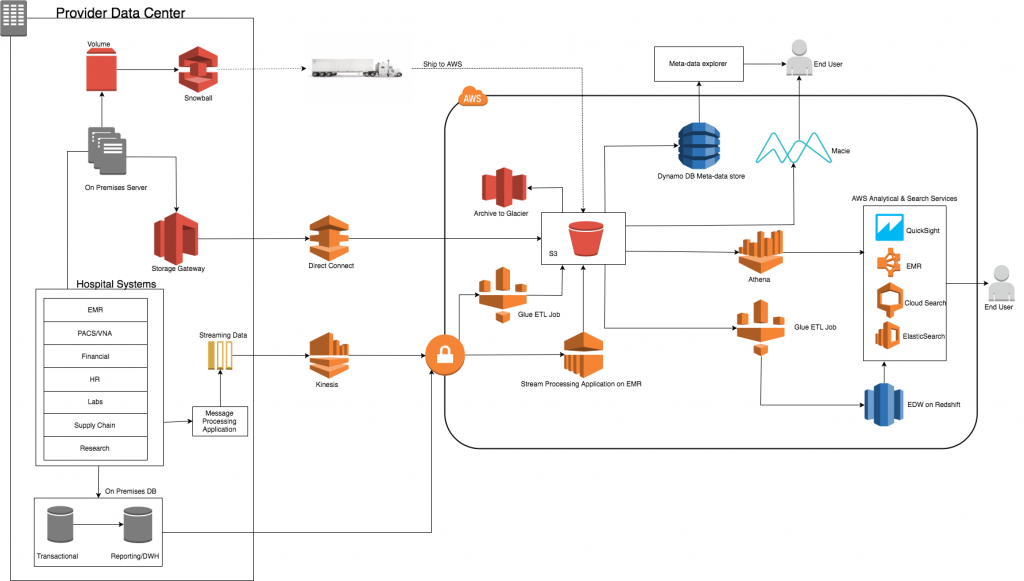
Store, Protect, Optimize Your Healthcare Data with AWS: Part 1
This blog post was co-authored by Ujjwal Ratan, a senior AI/ML solutions architect on the global life sciences team. Healthcare data is generated at an ever-increasing rate and is predicted to reach 35 zettabytes by 2020. Being able to cost-effectively and securely manage this data whether for patient care, research or legal reasons is increasingly […]