AWS Architecture Blog
Category: Database

Disaster Recovery with AWS managed services, Part 1: Single Region
This 3-part blog series discusses disaster recovery (DR) strategies that you can implement to ensure your data is safe and that your workload stays available during a disaster. In Part I, we’ll discuss the single AWS Region/multi-Availability Zone (AZ) DR strategy. The strategy outlined in this blog post addresses how to integrate AWS managed services […]

Migrating Microsoft APS PDW to Amazon Redshift Cloud Data Warehouse
Before cloud data warehouses (CDWs), many organizations used hyper-converged infrastructure (HCI) for data analytics. HCIs pack storage, compute, networking, and management capabilities into a single “box” that you can plug into your data centers. However, because of its legacy architecture, an HCI is limited in how much it can scale storage and compute and continue […]

Batch Inference at Scale with Amazon SageMaker
Running machine learning (ML) inference on large datasets is a challenge faced by many companies. There are several approaches and architecture patterns to help you tackle this problem. But no single solution may deliver the desired results for efficiency and cost effectiveness. In this blog post, we will outline a few factors that can help […]

Exploring Data Transfer Costs for AWS Managed Databases
When selecting managed database services in AWS, it’s important to understand how data transfer charges are calculated – whether it’s relational, key-value, document, in-memory, graph, time series, wide column, or ledger. This blog will outline the data transfer charges for several AWS managed database offerings to help you choose the most cost-effective setup for your […]

Simplifying Multi-account CI/CD Deployments using AWS Proton
Many large enterprises, startups, and public sector entities maintain different deployment environments within multiple Amazon Web Services (AWS) accounts to securely develop, test, and deploy their applications. Maintaining separate AWS accounts for different deployment stages is a standard practice for organizations. It helps developers limit the blast radius in case of failure when deploying updates […]

Offloading SQL for Amazon RDS using the Heimdall Proxy
Getting the maximum scale from your database often requires fine-tuning the application. This can increase time and incur cost – effort that could be used towards other strategic initiatives. The Heimdall Proxy was designed to intelligently manage SQL connections to help you get the most out of your database. In this blog post, we demonstrate […]

Serverless Architecture for a Structured Data Mining Solution
Many businesses have an essential need for structured data stored in their own database for business operations and offerings. For example, a company that produces electronics may want to store a structured dataset of parts. This requires the following properties: color, weight, connector type, and more. This data may already be available from external sources. […]

Migrate Resources Between AWS Accounts
Have you ever wondered how to move resources between Amazon Web Services (AWS) accounts? You can really view this as a migration of resources. Migrating resources from one AWS account to another may be desired or required due to your business needs. Following are a few scenarios where this may be of benefit: When you […]
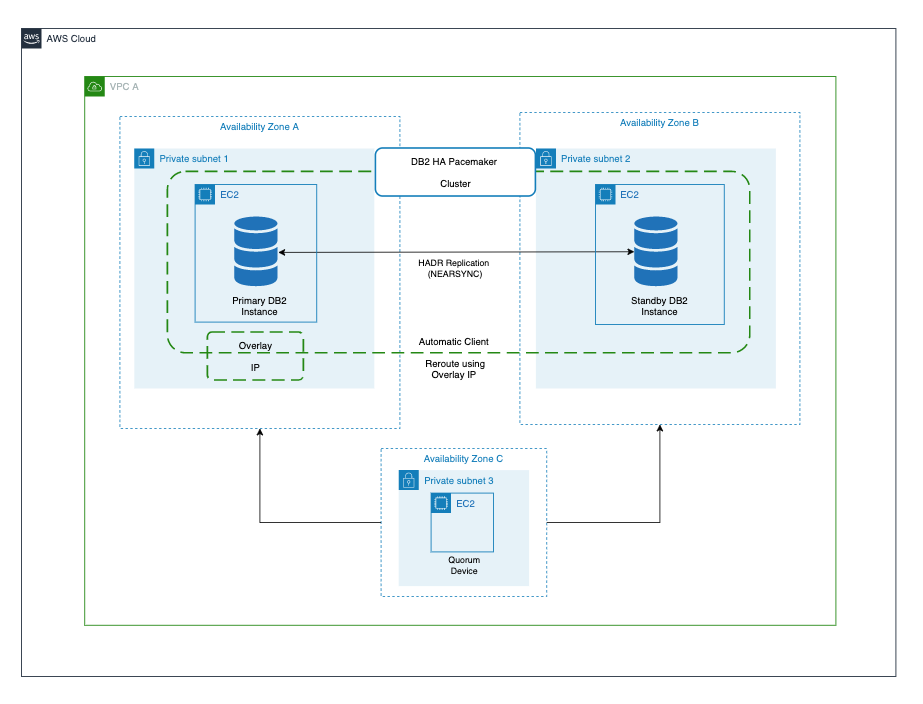
Field Notes: Set Up a Highly Available Database on AWS with IBM Db2 Pacemaker
Many AWS customers need to run mission-critical workloads—like traffic control system, online booking system, and so forth—using the IBM Db2 LUW database server. Typically, these workloads require the right high availability (HA) solution to make sure that the database is available in the event of a host or Availability Zone failure. This HA solution for […]

How The Mill Adventure Implemented Event Sourcing at Scale Using DynamoDB
This post was co-written by Joao Dias, Chief Architect at The Mill Adventure and Uri Segev, Principal Serverless Solutions Architect at AWS The Mill Adventure provides a complete gaming platform, including licenses and operations, for rapid deployment and success in online gaming. It underpins every aspect of the process so that you can focus on […]