AWS Architecture Blog
Category: Industries

Transform lease agreement workflows with Amazon Bedrock
This post explores how Amazon Bedrock can transform property management operations and optimize costs. We examine a practical approach to tackle challenges such as processing high volumes of lease agreements, maintaining compliance with varied regulatory requirements.

How Banfico built an Open Banking and Payment Services Directive (PSD2) compliance solution on AWS
This post was co-written with Paulo Barbosa, the COO of Banfico. Introduction Banfico is a London-based FinTech company, providing market-leading Open Banking regulatory compliance solutions. Over 185 leading Financial Institutions and FinTech companies use Banfico to streamline their compliance process and deliver the future of banking. Under the EU’s revised PSD2, banks can use application […]

Genomics workflows, Part 7: analyze public RNA sequencing data using AWS HealthOmics
Genomics workflows process petabyte-scale datasets on large pools of compute resources. In this blog post, we discuss how life science organizations can use Amazon Web Services (AWS) to run transcriptomic sequencing data analysis using public datasets. This allows users to quickly test research hypotheses against larger datasets in support of clinical diagnostics. We use AWS […]

Genomics workflows, Part 6: cost prediction
Genomics workflows run on large pools of compute resources and take petabyte-scale datasets as inputs. Workflow runs can cost as much as hundreds of thousands of US dollars. Given this large scale, scientists want to estimate the projected cost of their genomics workflow runs before deciding to launch them. In Part 6 of this series, […]
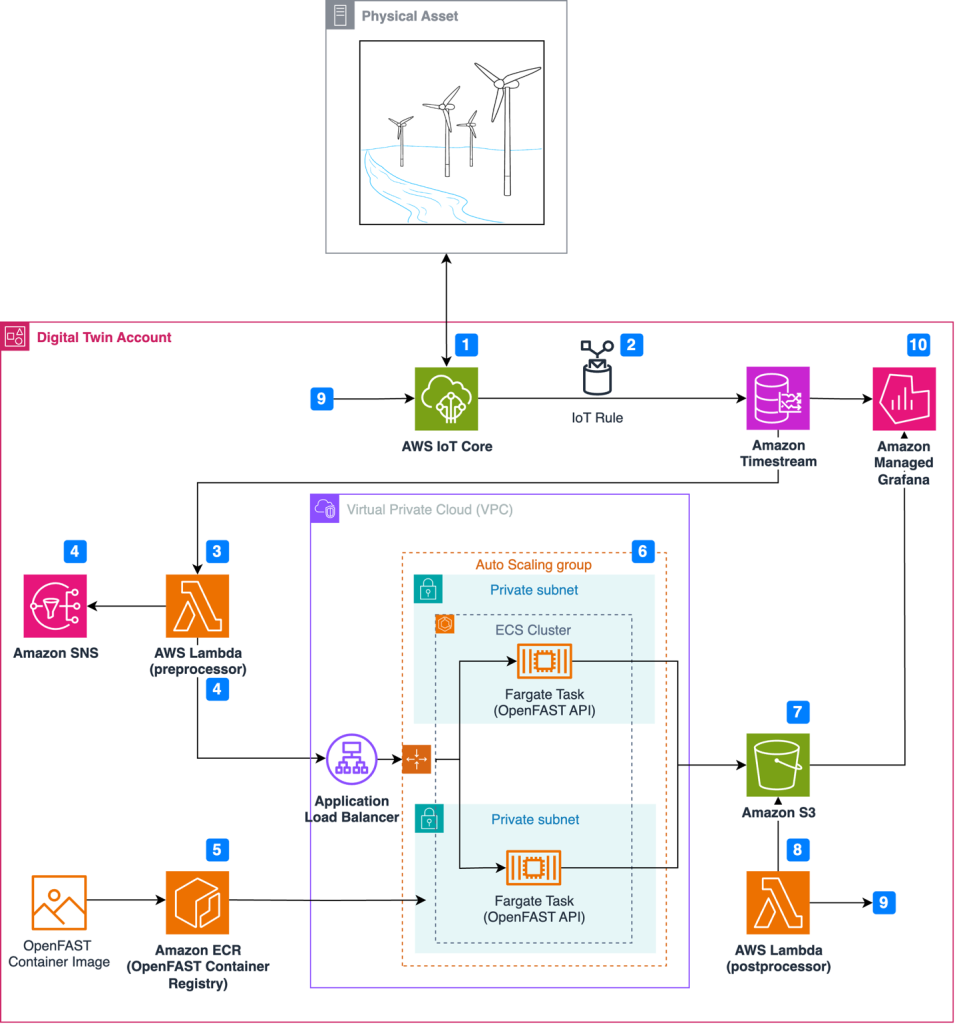
Physics on AWS: Optimizing wind turbine performance using OpenFAST in a digital twin
Wind energy plays a crucial role in global decarbonization efforts by generating emission-free power from an abundant resource. In 2022, wind energy produced 2100 terawatt-hours (TWh) globally, or over 7% of global electricity, with expectations to reach 7400 TWh by 2030. Despite its potential, several challenges must be addressed to help meet grid decarbonization targets. […]

Software-defined edge architecture for connected vehicles
To remain competitive in a marketplace that increasingly views transportation as a service emphasizing customer experience, vehicle capabilities and mobility applications need to improve and increase value over time, much like the internet of things and smart phones have done. Vehicle manufacturers and fleet operators are responding to this change by using data to inform […]

A modern approach to implementing the serverless Customer Data Platform
When building a Customer Data Platform (CDP), advertising and marketing Independent Software Vendors (ISVs) face a unique set of challenges. The ISV can help organizations with the heavy lifting required to build, secure, and maintain near real-time, high volume CDPs. However, architecting CDPs using traditional on-premises technologies can introduce multiple complexities and can limit deployment […]

An overview and architecture of building a Customer Data Platform on AWS
The deprecation of digital consumer identifiers, such as third-party cookies and mobile advertising IDs, and the rapid growth of data from expanding consumer touchpoints, has created challenges in identifying, managing, and reaching customers in digital channels. Organizations must rethink their strategies for collecting and storing customer data. Customer Data Platforms (CDPs) collect, aggregate, and organize […]

Architecting near real-time personalized recommendations with Amazon Personalize
Delivering personalized customer experiences enables organizations to improve business outcomes such as acquiring and retaining customers, increasing engagement, driving efficiencies, and improving discoverability. Developing an in-house personalization solution can take a lot of time, which increases the time it takes for your business to launch new features and user experiences. In this post, we show […]

How Shiji Group created a global guest profile store on AWS
Shiji Group provides global software solutions for the hospitality industry. The Shiji Enterprise Platform enables customers to manage large hotel property portfolios using software as a service (SaaS). Among functionalities such as reservations, housekeeping, finance, and integrations with external systems, the guest profile is a key aspect of the system. Besides personal information (such as […]