AWS Architecture Blog
Category: Industries

Build Your Own Game Day to Support Operational Resilience
Operational resilience is your firm’s ability to provide continuous service through people, processes, and technology that are aware of and adaptive to constant change. Downtime of your mission-critical applications can not only damage your reputation, but can also make you liable to multi-million-dollar financial fines. One way to test operational resilience is to simulate life-like […]

Field Notes: Tracking Overall Equipment Effectiveness with AWS IoT Analytics and Amazon QuickSight
This post was co-authored with Michael Brown, Senior Solutions Architect, Manufacturing at AWS. Overall equipment effectiveness (OEE) is a measure of how well a manufacturing operation is utilized (facilities, time and material) compared to its full potential, during the periods when it is scheduled to run. Measuring OEE provides a way to obtain actionable insights […]

Using AWS Serverless to Power Event Management Applications
Most large events have common activities such as event registration, check-in upon arrival, and requesting of amenities. When designing applications, factors such as high availability, low latency, reliability, and security must be considered. In this blog post, we’d like to show how Amazon Web Services (AWS) can assist you in event planning activities. We’ll share […]

Securely Ingest Industrial Data to AWS via Machine to Cloud Solution
As a manufacturing enterprise, maximizing your operational efficiency and optimizing output are critical factors in this competitive global market. However, many manufacturers are unable to frequently collect data, link data together, and generate insights to help them optimize performance. Furthermore, decades of competing standards for connectivity have resulted in the lack of universal protocols to […]

Ensure Workload Resiliency and Comply with Data Residency Requirements with AWS Outposts
Personally Identifiable Information (PII) and Personal Health Information (PHI) data are critical to the continued operation of healthcare organizations. Disaster recovery (DR) strategies must ensure that healthcare provider workloads with PII and PHI data operate with near-zero data loss recovery point objective (RPO) and recovery time objective (RTO). In most cases, an organization would typically […]

Scaling Data Analytics Containers with Event-based Lambda Functions
The marketing industry collects and uses data from various stages of the customer journey. When they analyze this data, they establish metrics and develop actionable insights that are then used to invest in customers and generate revenue. If you’re a data scientist or developer in the marketing industry, you likely often use containers for services […]
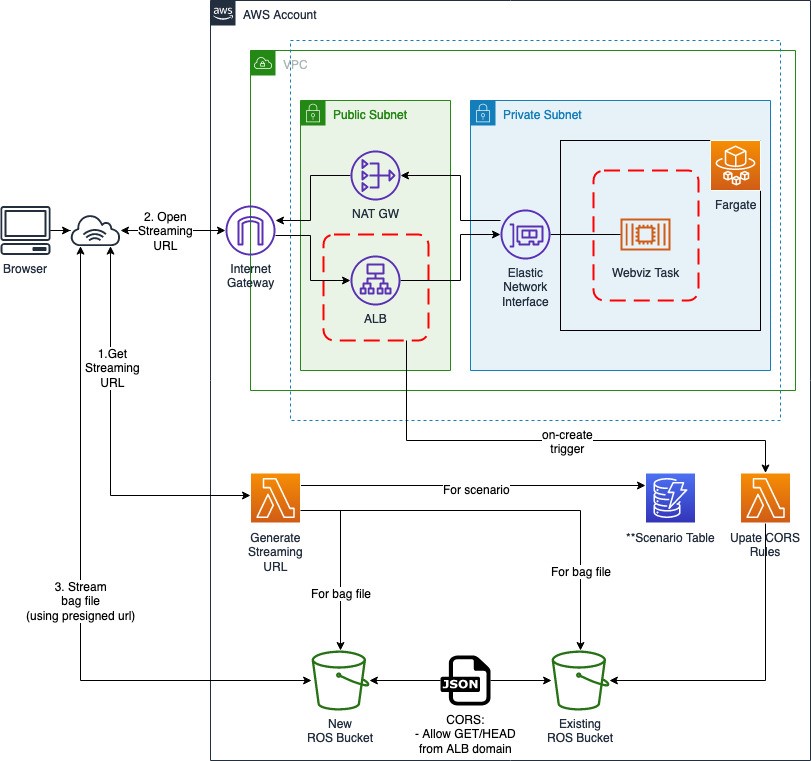
Field Notes: Deploy and Visualize ROS Bag Data on AWS using rviz and Webviz for Autonomous Driving
In the automotive industry, ROS bag files are frequently used to capture drive data from test vehicles configured with cameras, LIDAR, GPS, and other input devices. The data for each device is stored as a topic in the ROS bag file. Developers and engineers need to visualize and inspect the contents of ROS bag files to identify […]

Queue Integration with Third-party Services on AWS
Commercial off-the-shelf software and third-party services can present an integration challenge in event-driven workflows when they do not natively support AWS APIs. This is even more impactful when a workflow is subject to unpredicted usage spikes, and you want to increase decoupling and fault tolerance. Given the third-party nature of services, polling an Amazon Simple […]

Building a Data Pipeline for Tracking Sporting Events Using AWS Services
In an evolving world that is increasingly connected, data-centric, and fast-paced, the sports industry is no exception. Amazon Web Services (AWS) has been helping customers in the sports industry gain real-time insights through analytics. You can re-invent and reimagine the fan experience by tracking sports actions and activities. In this blog post, we will highlight […]

Address Modernization Tradeoffs with Lake House Architecture
Many organizations are modernizing their applications to reduce costs and become more efficient. They must adapt to modern application requirements that provide 24×7 global access. The ability to scale up or down quickly to meet demand and process a large volume of data is critical. This is challenging while maintaining strict performance and availability. For […]