AWS Architecture Blog
Category: Networking & Content Delivery

How bitdrift scaled to 121 million concurrent gRPC connections on Amazon CloudFront for live telemetry sporting events
When 121 million mobile devices establish persistent gRPC connections to your origin infrastructure within seconds of a live broadcast, the routing policy behind your DNS records matters far more than it does at normal traffic levels. The wrong policy can concentrate all your connections onto a single origin endpoint, turning a scaling success into an […]

Dual-token authentication for Nakama game servers with Amazon Cognito on AWS
In this post, you learn how to configure an Amazon Cognito User Pool for SRP-based game client authentication with no client secret. You will implement a Go runtime hook that validates Cognito JWTs and bridges player identity to Nakama sessions.

How Samsung achieved real-time pricing with AWS Lambda Response Streaming
In this post, we walk through the legacy architecture challenges, the stateless streaming solution, key implementation patterns, and performance results—a pattern you can apply if you’re building high-traffic APIs that aggregate data from multiple backend sources.
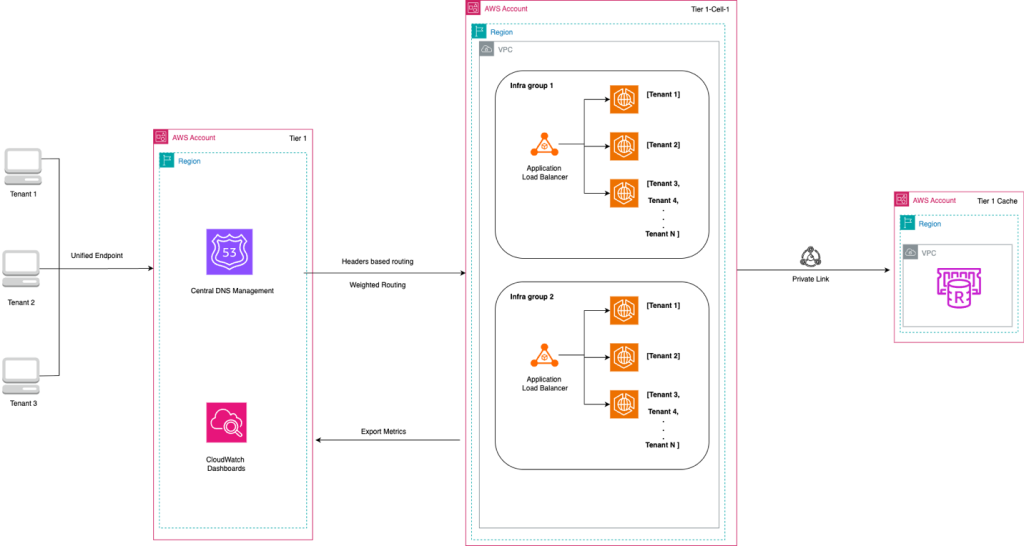
Building hybrid multi-tenant architecture for stateful services on AWS
In this post, we show you how to build a hybrid multi-tenant architecture that provides strong tenant isolation without requiring per-tenant AWS accounts. You learn how to configure Route 53 weighted routing to distribute traffic across multiple accounts, deploy Application Load Balancer listener rules for tenant-specific routing, create dedicated ECS clusters per tenant, and establish AWS PrivateLink connectivity to shared dependencies.
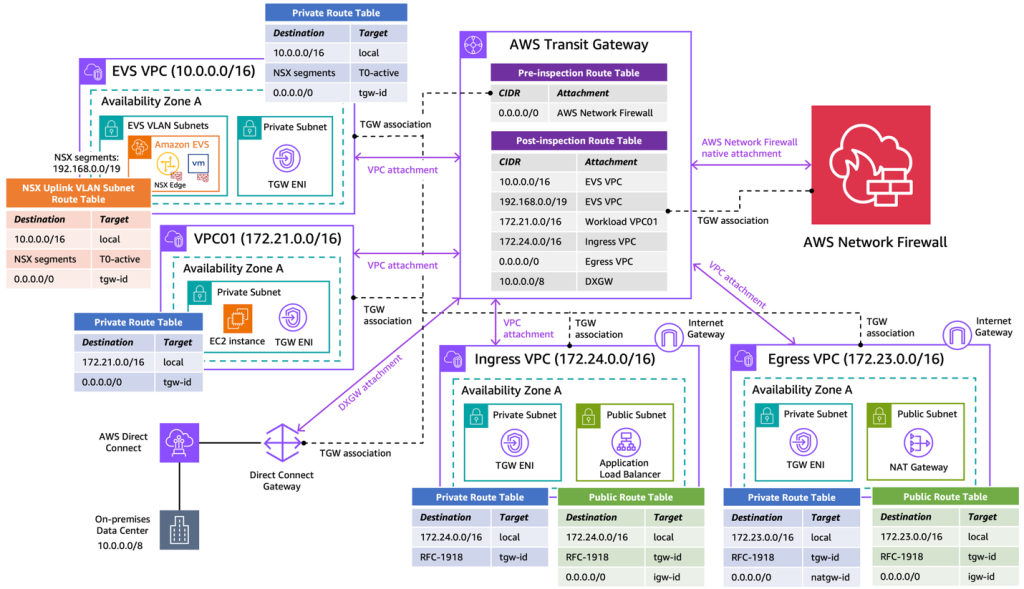
Secure Amazon Elastic VMware Service (Amazon EVS) with AWS Network Firewall
In this post, we demonstrate how to utilize AWS Network Firewall to secure an Amazon EVS environment, using a centralized inspection architecture across an EVS cluster, VPCs, on-premises data centers and the internet. We walk through the implementation steps to deploy this architecture using AWS Network Firewall and AWS Transit Gateway.
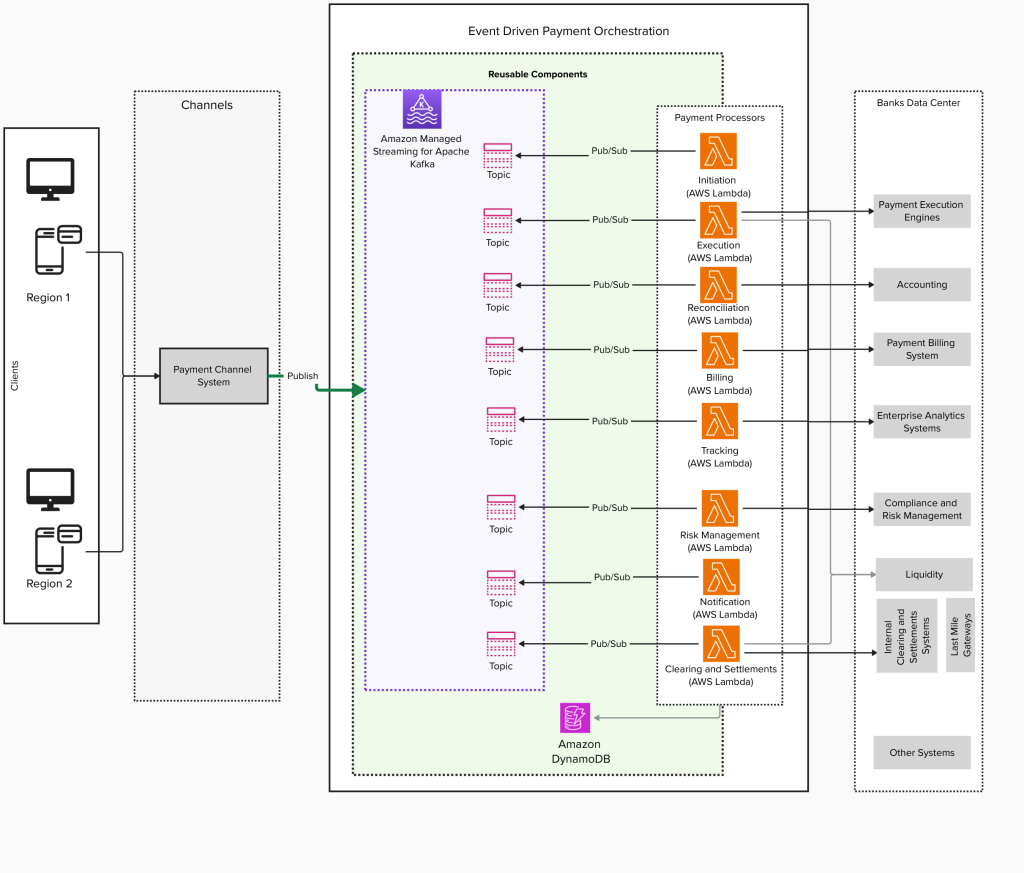
Modernization of real-time payment orchestration on AWS
The global real-time payments market is experiencing significant growth. According to Fortune Business Insights, the market was valued at USD 24.91 billion in 2024 and is projected to grow to USD 284.49 billion by 2032, with a CAGR of 35.4%. Similarly, Grand View Research reports that the global mobile payment market, valued at USD 88.50 […]
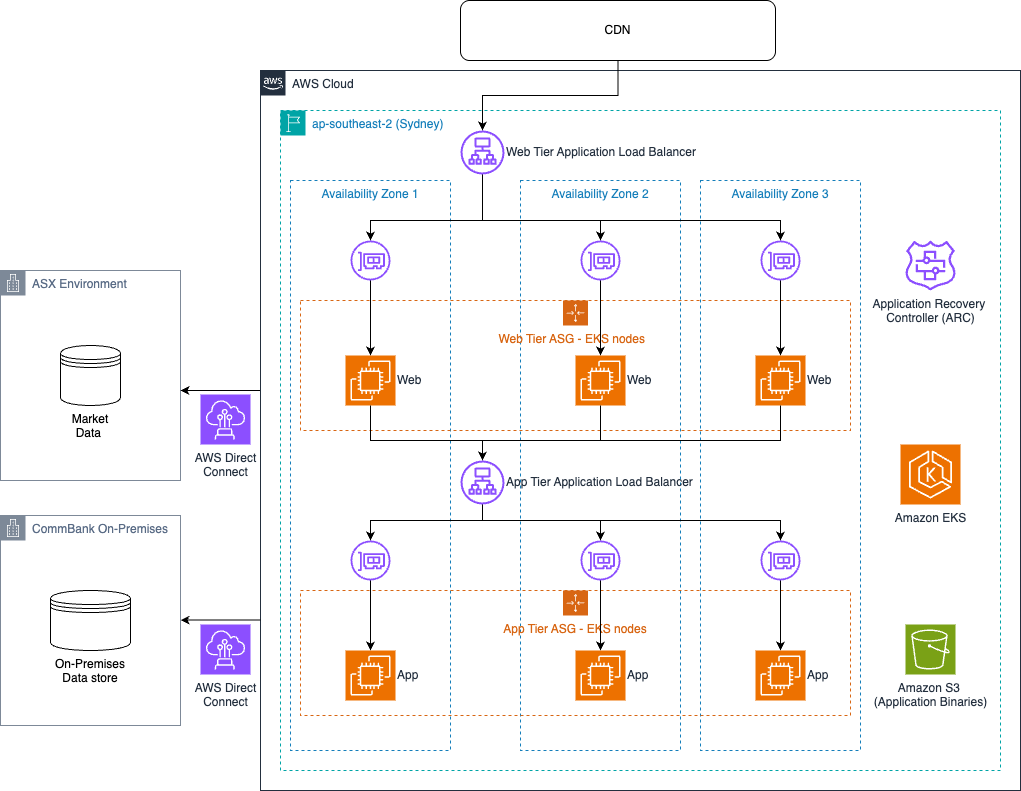
How CommBank made their CommSec trading platform highly available and operationally resilient
In this post, we explore how CommSec, Australia’s leading online broker, transitioned from a multicloud environment to AWS as their sole cloud provider while implementing Amazon Application Recovery Controller (ARC) zonal shift to maintain high availability and operational resilience. The consolidation resulted in significant benefits including 25% base capacity reduction, two times faster deployments, and improved failover capabilities through ARC zonal shift, enabling CommSec to continue serving millions of customers while meeting strict regulatory requirements.
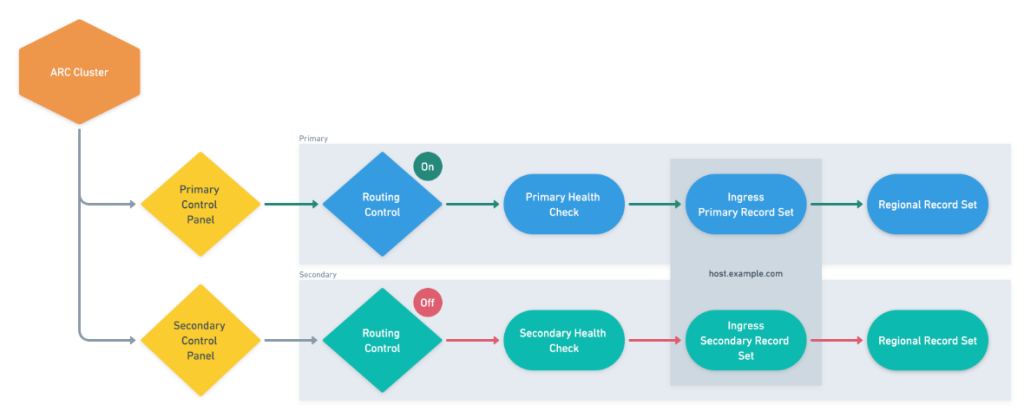
How HashiCorp made cross-Region switchover seamless with Amazon Application Recovery Controller
In this post, we discuss HashiCorp’s journey from manual, stress-inducing failover procedures to a streamlined, confident approach that fundamentally changed how they deliver on their enterprise-grade resilience promises.

Amazon Bedrock baseline architecture in an AWS landing zone
In this post, we explore the Amazon Bedrock baseline architecture and how you can secure and control network access to your various Amazon Bedrock capabilities within AWS network services and tools. We discuss key design considerations, such as using Amazon VPC Lattice auth policies, Amazon Virtual Private Cloud (Amazon VPC) endpoints, and AWS Identity and Access Management (IAM) to restrict and monitor access to your Amazon Bedrock capabilities.

Build a multi-Region AWS PrivateLink backed service with seamless failover
This post demonstrates how the Issuer Solutions business of Global Payments, as a service provider, implemented cross-Region failover for an AWS PrivateLink backed service exposed to their customers. Their solution enables failover to a secondary Region without customer coordination, reducing Recovery Time Objective (RTO).