AWS Big Data Blog
Category: Amazon Athena

Boosting your data lake insights using the Amazon Athena Query Federation SDK
Today’s modern applications use multiple purpose-built database engines, including relational, key-value, document, and in-memory databases. This purpose-built approach improves the way applications use data by providing better performance and reducing cost. However, the approach raises some challenges for data teams that need to provide a holistic view on top of these database engines, and especially […]

Keeping your data lake clean and compliant with Amazon Athena
June 2025: This post has been reviewed for accuracy and the following updates have been made: added new function to retrieve SQL query in the Lambda code; upgraded Python’s run time and version of sqlparse in the Lambda deployment package; added and removed actions in the Lambda policy; updated the CloudFormation template to reflect policy […]

Auditing, inspecting, and visualizing Amazon Athena usage and cost
Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. It’s a serverless platform with no need to set up or manage infrastructure. Athena scales automatically—running queries in parallel—so results are fast, even with large datasets and complex queries. You […]

Managing COVID-19 exposure with crowd tracing
This is a guest blog post by AWS partner Aspire Ventures As we enter winter, with fewer options to be outdoors, our personal choices can impact our risk of contracting the COVID-19 virus even more. The New England Journal of Medicine publication showed real-world examples of the effectiveness of masks and social distancing in mitigating […]

Redacting sensitive information with user-defined functions in Amazon Athena
Amazon Athena now supports user-defined functions (in Preview), a feature that enables you to write custom scalar functions and invoke them in SQL queries. Although Athena provides built-in functions, UDFs enable you to perform custom processing such as compressing and decompressing data, redacting sensitive data, or applying customized decryption. You can write your UDFs in […]
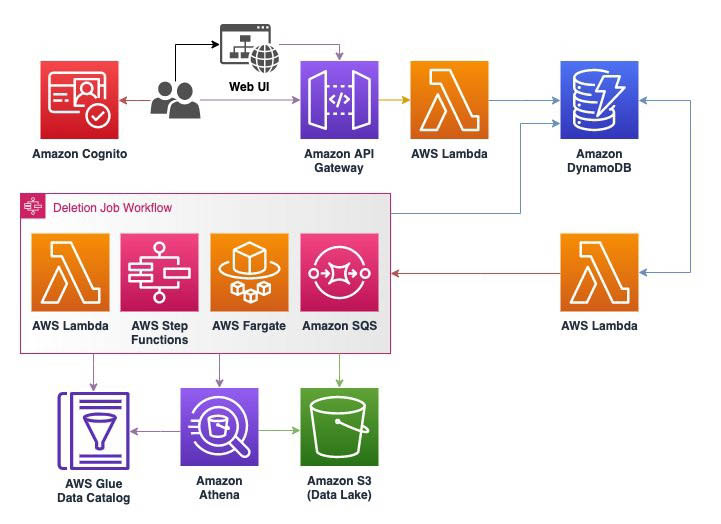
Handling data erasure requests in your data lake with Amazon S3 Find and Forget
February 2024: This post was reviewed and updated for accuracy. Data lakes are a popular choice for organizations to store data around their business activities. Best practice design of data lakes impose that data is immutable once stored, but new regulations such as the European General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), […]

Extracting and joining data from multiple data sources with Athena Federated Query
With modern day architectures, it’s common to have data sitting in various data sources. We need proper tools and technologies across those sources to create meaningful insights from stored data. Amazon Athena is primarily used as an interactive query service that makes it easy to analyze unstructured, semi-structured, and structured data stored in Amazon Simple […]

Automating bucketing of streaming data using Amazon Athena and AWS Lambda
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In today’s world, data plays a vital role in helping businesses understand and improve their processes and services to reduce cost. You can use several tools to […]
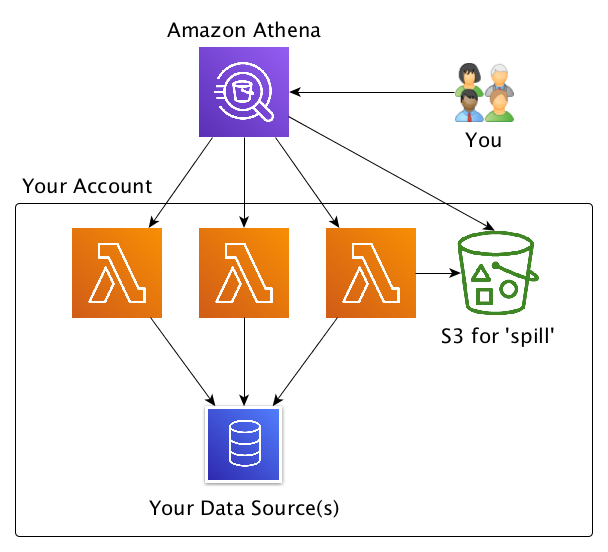
Configure and optimize performance of Amazon Athena federation with Amazon Redshift
This post provides guidance on how to configure Amazon Athena federation with AWS Lambda and Amazon Redshift, while addressing performance considerations to ensure proper use.

Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Toyota Motor Corporation (TMC), a global automotive manufacturer, has made “connected cars” a core priority as part of its broader transformation from an auto company to a mobility company. In recent years, […]