AWS Big Data Blog
Category: AWS Glue
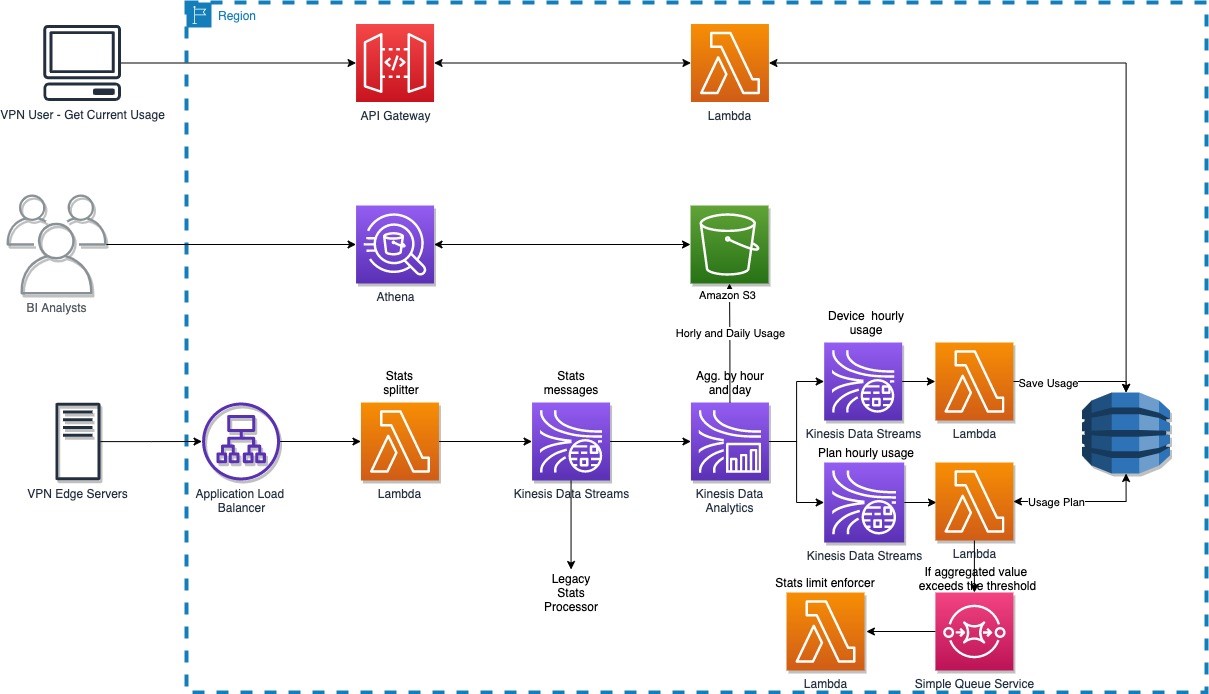
How NortonLifelock built a serverless architecture for real-time analysis of their VPN usage metrics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post presents a reference architecture and optimization strategies for building serverless data analytics solutions on AWS using Amazon Kinesis Data Analytics. In addition, this post shows […]

How MOIA built a fully automated GDPR compliant data lake using AWS Lake Formation, AWS Glue, and AWS CodePipeline
This is a guest blog post co-written by Leonardo Pêpe, a Data Engineer at MOIA. MOIA is an independent company of the Volkswagen Group with locations in Berlin and Hamburg, and operates its own ride pooling services in Hamburg and Hanover. The company was founded in 2016 and develops mobility services independently or in partnership […]

Create a custom Amazon S3 Storage Lens metrics dashboard using Amazon QuickSight
Companies use Amazon Simple Storage Service (Amazon S3) for its flexibility, durability, scalability, and ability to perform many things besides storing data. This has led to an exponential rise in the usage of S3 buckets across numerous AWS Regions, across tens or even hundreds of AWS accounts. To optimize costs and analyze security posture, Amazon […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]
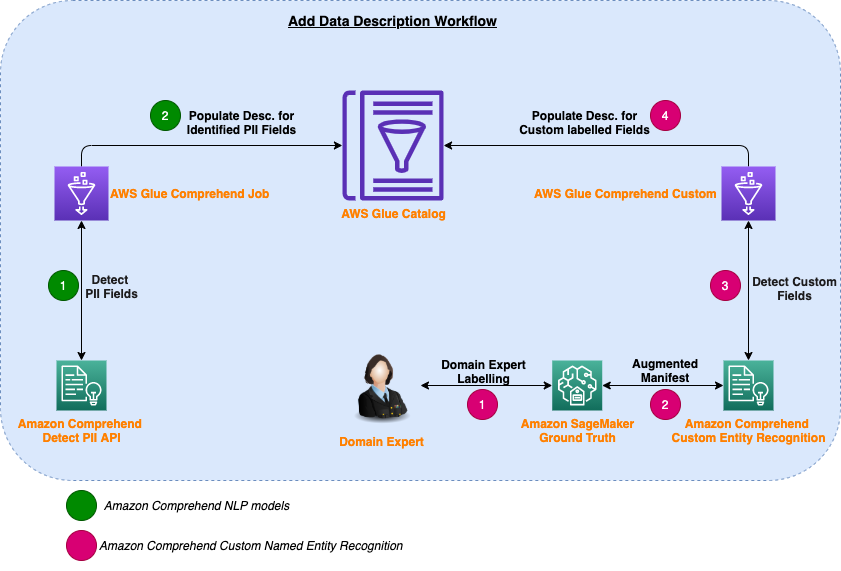
Simplify data discovery for business users by adding data descriptions in the AWS Glue Data Catalog
In this post, we discuss how to use AWS Glue Data Catalog to simplify the process for adding data descriptions and allow data analysts to access, search, and discover this cataloged metadata with BI tools. In this solution, we use AWS Glue Data Catalog, to break the silos between cross-functional data producer teams, sometimes also known […]

Introducing AWS Glue 3.0 with optimized Apache Spark 3.1 runtime for faster data integration
May 2022: This post was reviewed for accuracy. In August 2020, we announced the availability of AWS Glue 2.0. AWS Glue 2.0 reduced job startup times by 10x, enabling customers to realize an average of 45% cost savings on their extract, transform, and load (ETL) jobs. The fast start time allows customers to easily adopt […]

How Comcast uses AWS to rapidly store and analyze large-scale telemetry data
This blog post is co-written by Russell Harlin from Comcast Corporation. Comcast Corporation creates incredible technology and entertainment that connects millions of people to the moments and experiences that matter most. At the core of this is Comcast’s high-speed data network, providing tens of millions of customers across the country with reliable internet connectivity. This […]

How GE Healthcare modernized their data platform using a Lake House Architecture
GE Healthcare (GEHC) operates as a subsidiary of General Electric. The company is headquartered in the US and serves customers in over 160 countries. As a leading global medical technology, diagnostics, and digital solutions innovator, GE Healthcare enables clinicians to make faster, more informed decisions through intelligent devices, data analytics, applications, and services, supported by […]

Build a serverless event-driven workflow with AWS Glue and Amazon EventBridge
April 2025: This post was reviewed for accuracy. Customers are adopting event-driven-architectures to improve the agility and resiliency of their applications. As a result, data engineers are increasingly looking for simple-to-use yet powerful and feature-rich data processing tools to build pipelines that enrich data, move data in and out of their data lake and data […]
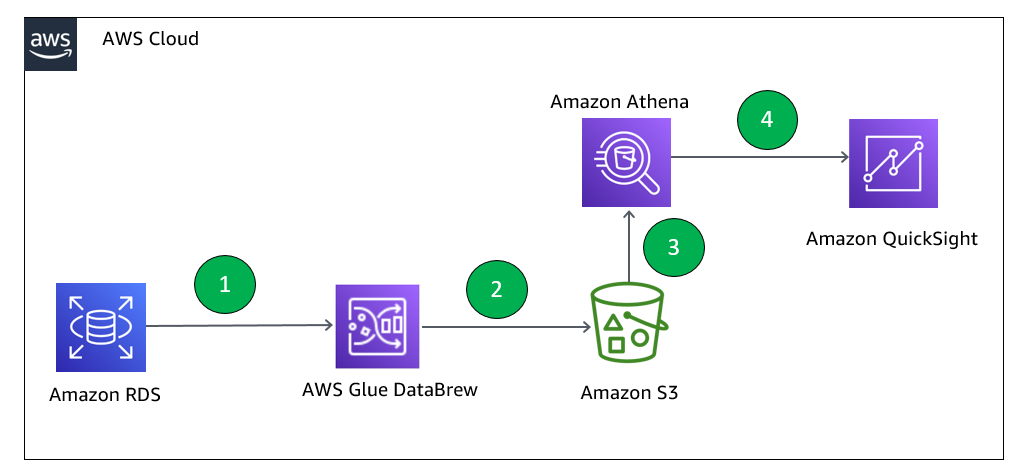
Data preparation using an Amazon RDS for MySQL database with AWS Glue DataBrew
With AWS Glue DataBrew, data analysts and data scientists can easily access and visually explore any amount of data across their organization directly from their Amazon Simple Storage Service (Amazon S3) data lake, Amazon Redshift data warehouse, or Amazon Aurora and Amazon Relational Database Service (Amazon RDS) databases. You can choose from over 250 built-in […]