AWS Big Data Blog
Category: Analytics
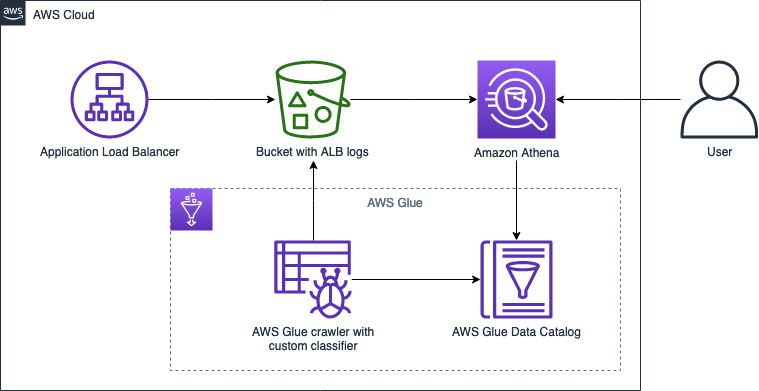
Catalog and analyze Application Load Balancer logs more efficiently with AWS Glue custom classifiers and Amazon Athena
You can query Application Load Balancer (ALB) access logs for various purposes, such as analyzing traffic distribution and patterns. You can also easily use Amazon Athena to create a table and query against the ALB access logs on Amazon Simple Storage Service (Amazon S3). (For more information, see How do I analyze my Application Load […]
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platform
This post was co-written with Alcuin Weidus, Principal Architect from GE Aviation. GE Aviation, an operating unit of GE, is a world-leading provider of jet and turboprop engines, as well as integrated systems for commercial, military, business, and general aviation aircraft. GE Aviation has a global service network to support these offerings. From the turbosupercharger […]

Apply CI/CD DevOps principles to Amazon Redshift development
CI/CD in the context of application development is a well-understood topic, and developers can choose from numerous patterns and tools to build their pipelines to handle the build, test, and deploy cycle when a new commit gets into version control. For stored procedures or even schema changes that are directly related to the application, this […]
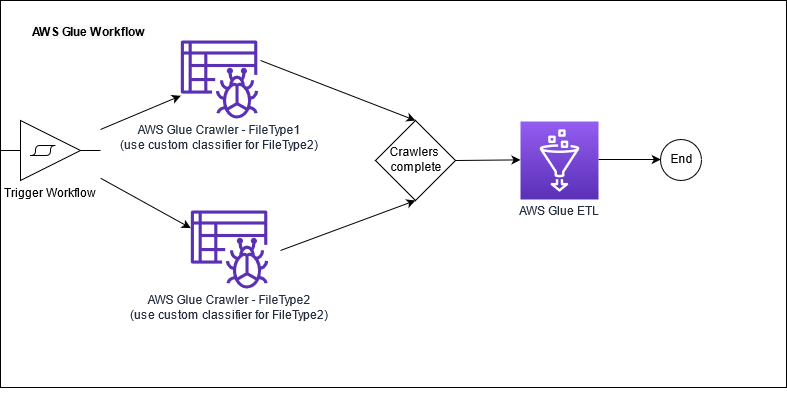
Orchestrate an ETL pipeline using AWS Glue workflows, triggers, and crawlers with custom classifiers
Extract, transform, and load (ETL) orchestration is a common mechanism for building big data pipelines. Orchestration for parallel ETL processing requires the use of multiple tools to perform a variety of operations. To simplify the orchestration, you can use AWS Glue workflows. This post demonstrates how to accomplish parallel ETL orchestration using AWS Glue workflows […]

Design captivating Amazon QuickSight dashboards with new Table and Pivot Table features
Amazon QuickSight is a fast and cloud-powered business intelligence (BI) service that makes it easy to create and deliver insights to everyone in your organization without any servers or infrastructure. QuickSight dashboards can also be embedded into applications and portals to deliver insights to external stakeholders. And QuickSight Q lets end-users simply ask questions in […]
Secure and simplify account setup and access management with new Amazon QuickSight administrative controls
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards, and share these with tens of thousands of users, either within the QuickSight interface, or embedded in software as a service (SaaS) applications or web portals. Unlike many BI solutions in the market […]

Amazon QuickSight Recap re:Invent 2021
AWS re:Invent is a learning conference hosted by AWS for the global cloud computing community. This year’s re:Invent was held in person in Las Vegas from November 29th through December 3rd. AWS is also hosting virtual re:invent for attendees to access on demand content. Register now for virtual re:invent or subscribe to the AWS Events […]

Query data in Amazon OpenSearch Service using SQL from Amazon Athena
Amazon Athena is an interactive serverless query service to query data from Amazon Simple Storage Service (Amazon S3) in standard SQL. Amazon OpenSearch Service is a fully managed, open-source, distributed search and analytics suite derived from Elasticsearch, allowing you to run OpenSearch Service or Elasticsearch clusters at scale without having to manage hardware provisioning, software […]

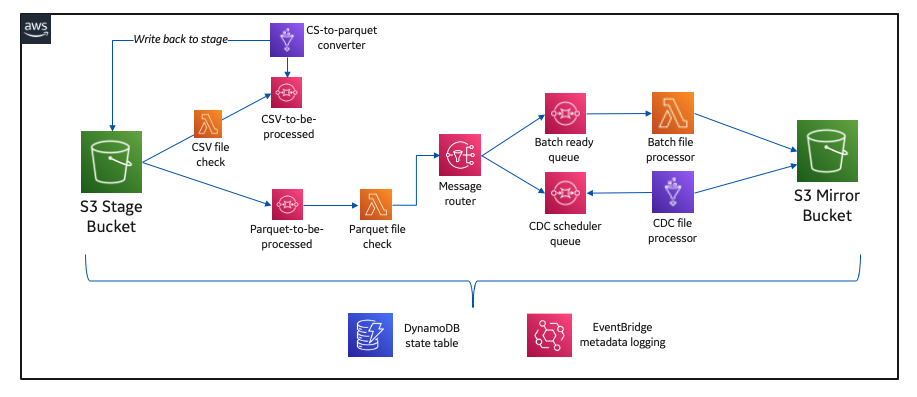
Create a serverless event-driven workflow to ingest and process Microsoft data with AWS Glue and Amazon EventBridge
Microsoft SharePoint is a document management system for storing files, organizing documents, and sharing and editing documents in collaboration with others. Your organization may want to ingest SharePoint data into your data lake, combine the SharePoint data with other data that’s available in the data lake, and use it for reporting and analytics purposes. AWS […]

Accelerate self-service analytics with Amazon Redshift Query Editor V2
August 2023: This post was reviewed and updated with new features. Amazon Redshift is a fast, fully managed cloud data warehouse. Tens of thousands of customers use Amazon Redshift as their analytics platform. Users such as data analysts, database developers, and data scientists use SQL to analyze their data in Amazon Redshift data warehouses. Amazon […]