AWS Big Data Blog
Category: Analytics

Optimize your workloads with Amazon Redshift Serverless AI-driven scaling and optimization
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the data warehouse. However, you might need to automatically scale compute resources based on factors like query complexity and data volume to meet price-performance targets, irrespective of query queuing. […]

Reducing long-term logging expenses by 4,800% with Amazon OpenSearch Service
When you use Amazon OpenSearch Service for time-bound data like server logs, service logs, application logs, clickstreams, or event streams, storage cost is one of the primary drivers for the overall cost of your solution. Over the last year, OpenSearch Service has released features that have opened up new possibilities for storing your log data […]

Unlock scalable analytics with a secure connectivity pattern in AWS Glue to read from or write to Snowflake
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. As organizations increasingly rely on data stored across various platforms, such as Snowflake, Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these […]

Embed Amazon OpenSearch Service dashboards in your application
Customers across diverse industries rely on Amazon OpenSearch Service for interactive log analytics, real-time application monitoring, website search, vector database, deriving meaningful insights from data, and visualizing these insights using OpenSearch Dashboards. Additionally, customers often seek out capabilities that enable effortless sharing of visual dashboards and seamless embedding of these dashboards within their applications, further […]

Seamless integration of data lake and data warehouse using Amazon Redshift Spectrum and Amazon DataZone
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate data lakes or warehouses—hinders visibility and cross-functional analysis. A data mesh framework empowers business units with data ownership and facilitates seamless sharing. However, integrating datasets from different business units can present several […]

Implement data quality checks on Amazon Redshift data assets and integrate with Amazon DataZone
In this post, we show how to capture the data quality metrics for data assets produced in Amazon Redshift. With Amazon DataZone, the data owner can directly import the technical metadata of a Redshift database table and views to the Amazon DataZone project’s inventory. As these data assets gets imported into Amazon DataZone, it bypasses the AWS Glue Data Catalog, creating a gap in data quality integration. This post proposes a solution to enrich the Amazon Redshift data asset with data quality scores and KPI metrics.

Improve the resilience of Amazon Managed Service for Apache Flink application with system-rollback feature
This post explores how to use the system-rollback feature in Managed Service for Apache Flink.We discuss how this functionality improves your application’s resilience by providing a highly available Flink application. Through an example, you will also learn how to use the APIs to have more visibility of the application’s operations.

Organize content across business units with enterprise-wide data governance using Amazon DataZone domain units and authorization policies
Amazon DataZone has announced a set of new data governance capabilities—domain units and authorization policies—that enable you to create business unit-level or team-level organization and manage policies according to your business needs. In this post, we discuss common approaches to structuring domain units, use cases that customers in the healthcare and life sciences (HCLS) industry encounter, and how to get started with the new domain units and authorization policies features from Amazon DataZone.
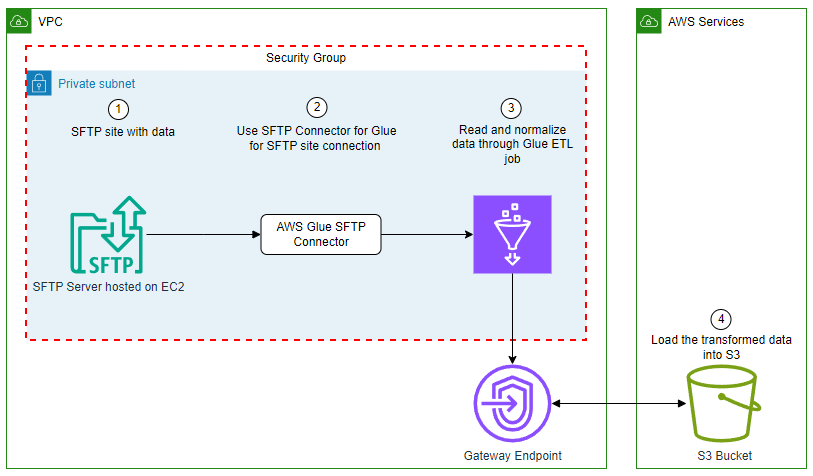
Use AWS Glue to streamline SFTP data processing
In this blog post, we explore how to use the SFTP Connector for AWS Glue from the AWS Marketplace to efficiently process data from Secure File Transfer Protocol (SFTP) servers into Amazon Simple Storage Service (Amazon S3), further empowering your data analytics and insights.

Automate Amazon Redshift Advisor recommendations with email alerts using an API
Amazon Redshift Advisor offers recommendations about optimizing your Redshift cluster performance and helps you save on operating costs. In this post, we show you how to use the ListRecommendations API to set up email notifications for Advisor recommendations on your Redshift cluster. These recommendations, such as identifying tables that should be vacuumed to sort the data or finding table columns that are candidates for compression, can help improve performance and save costs.