AWS Big Data Blog
Category: Analytics

Amazon Kinesis Data Streams: celebrating a decade of real-time data innovation
Data is a key strategic asset for every organization, and every company is a data business at its core. However, in many organizations, data is typically spread across a number of different systems such as software as a service (SaaS) applications, operational databases, and data warehouses. Such data silos make it difficult to get unified […]

How Wallapop improved performance of analytics workloads with Amazon Redshift Serverless and data sharing
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it straightforward and cost-effective to analyze all your data at petabyte scale, using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift Serverless makes it effortless to run and […]

Amazon MSK Serverless now supports Kafka clients written in all programming languages
Amazon MSK Serverless is a cluster type for Amazon Managed Streaming for Apache Kafka (Amazon MSK) that is the most straightforward way to run Apache Kafka clusters without having to manage compute and storage capacity. With MSK Serverless, you can run your applications without having to provision, configure, or optimize clusters, and you pay for […]
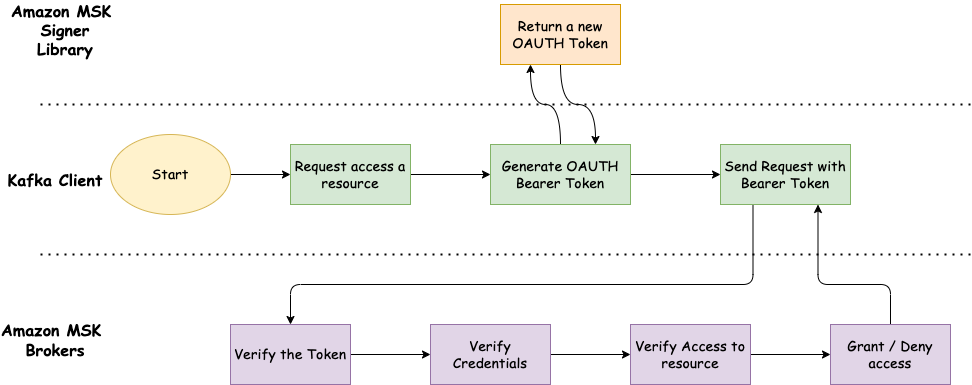
Amazon MSK IAM authentication now supports all programming languages
The AWS Identity and Access Management (IAM) authentication feature in Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports all programming languages. Administrators can simplify and standardize access control to Kafka resources using IAM. This support is based on SASL/OUATHBEARER, an open standard for authorization and authentication. Both Amazon MSK provisioned and serverless cluster […]

Your guide to AWS Analytics at AWS re:Invent 2023
Join the AWS Analytics team at AWS re:Invent this year, where new ideas and exciting innovations come together. For those in the data world, this post provides a curated guide for all analytics sessions that you can use to quickly schedule and build your itinerary. Book your spot early for the sessions you do not […]

How Gameskraft uses Amazon Redshift data sharing to support growing analytics workloads
This post is co-written by Anshuman Varshney, Technical Lead at Gameskraft. Gameskraft is one of India’s leading online gaming companies, offering gaming experiences across a variety of categories such as rummy, ludo, poker, and many more under the brands RummyCulture, Ludo Culture, Pocket52, and Playship. Gameskraft holds the Guinness World Record for organizing the world’s […]

Simplifying data processing at Capitec with Amazon Redshift integration for Apache Spark
This post is co-written with Preshen Goobiah and Johan Olivier from Capitec. Apache Spark is a widely-used open source distributed processing system renowned for handling large-scale data workloads. It finds frequent application among Spark developers working with Amazon EMR, Amazon SageMaker, AWS Glue and custom Spark applications. Amazon Redshift offers seamless integration with Apache Spark, […]

Create a modern data platform using the Data Build Tool (dbt) in the AWS Cloud
Building a data platform involves various approaches, each with its unique blend of complexities and solutions. A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. In this post, we delve into a case […]

How Gilead used Amazon Redshift to quickly and cost-effectively load third-party medical claims data
This post was co-written with Rajiv Arora, Director of Data Science Platform at Gilead Life Sciences. Gilead Sciences, Inc. is a biopharmaceutical company committed to advancing innovative medicines to prevent and treat life-threatening diseases, including HIV, viral hepatitis, inflammation, and cancer. A leader in virology, Gilead historically relied on these drugs for growth but now […]
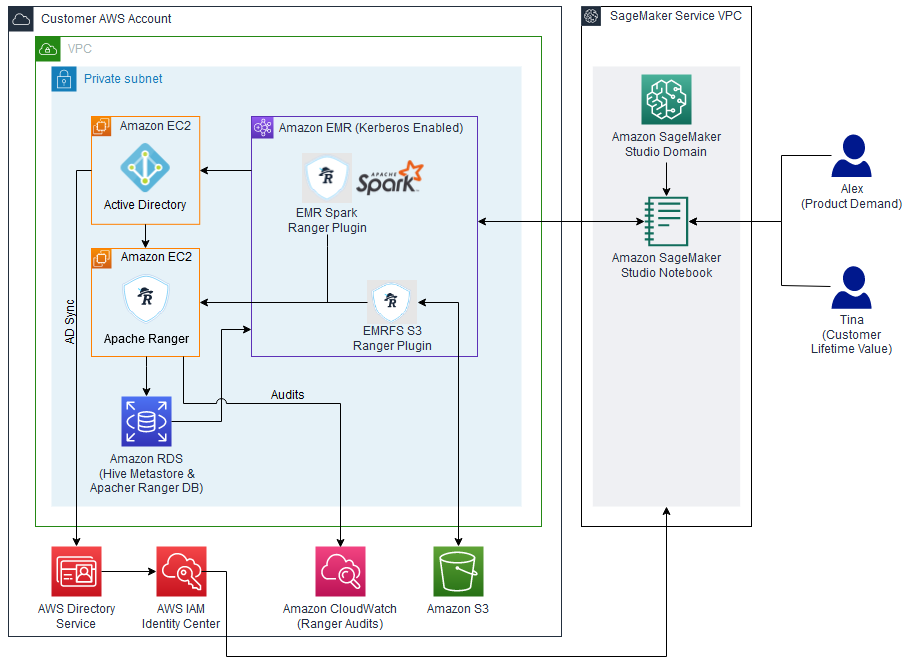
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.