AWS Big Data Blog
Category: Advanced (300)
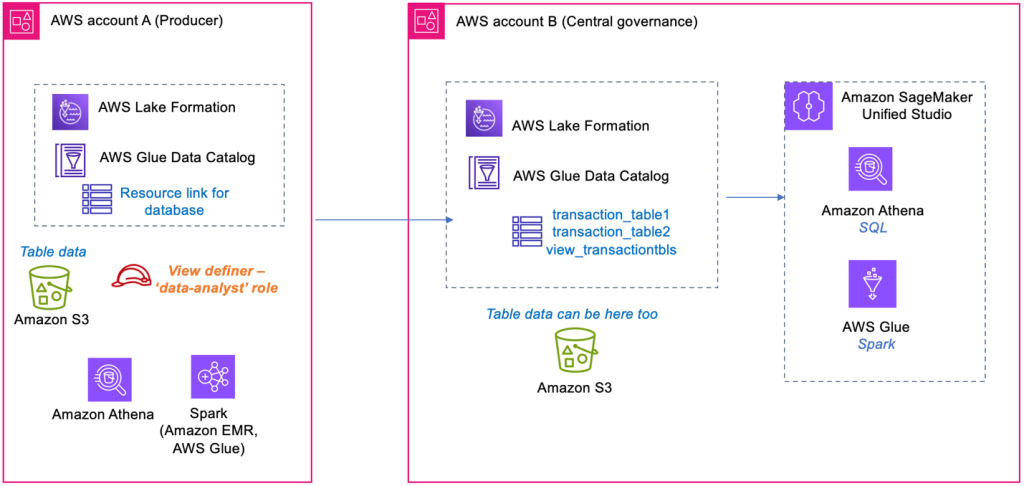
Create AWS Glue Data Catalog views using cross-account definer roles
In this post, we demonstrate how to use cross-account IAM definer roles with AWS Glue Data Catalog views. We show how data owner accounts can create and manage views in a central governance account while maintaining security and control over their data assets.

Simplify multi-warehouse data governance with Amazon Redshift federated permissions
Amazon Redshift federated permissions simplify permissions management across multiple Redshift warehouses. In this post, we show you how to define data permissions one time and automatically enforce them across warehouses in your AWS account, removing the need to re-create security policies in each warehouse.

Unifying governance and metadata across Amazon SageMaker Unified Studio and Atlan
In this post, we show you how to unify governance and metadata across Amazon SageMaker Unified Studio and Atlan through a comprehensive bidirectional integration. You’ll learn how to deploy the necessary AWS infrastructure, configure secure connections, and set up automated synchronization to maintain consistent metadata across both platforms.

Modernize Apache Spark workflows using Spark Connect on Amazon EMR on Amazon EC2
In this post, we demonstrate how to implement Apache Spark Connect on Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) to build decoupled data processing applications. We show how to set up and configure Spark Connect securely, so you can develop and test Spark applications locally while executing them on remote Amazon EMR clusters.

Create and update Apache Iceberg tables with partitions in the AWS Glue Data Catalog using the AWS SDK and AWS CloudFormation
In this post, we show how to create and update Iceberg tables with partitions in the Data Catalog using the AWS SDK and AWS CloudFormation.

IPv6 addressing with Amazon Redshift
As we witness the gradual transition from IPv4 to IPv6, AWS continues to expand its support for dual-stack networking across its service portfolio. In this post, we show how you can migrate your Amazon Redshift Serverless workgroup from IPv4-only to dual-stack mode, so you can make your data warehouse future ready.

Reference guide for building a self-service analytics solution with Amazon SageMaker
In this post, we show how to use Amazon SageMaker Catalog to publish data from multiple sources, including Amazon S3, Amazon Redshift, and Snowflake. This approach enables self-service access while ensuring robust data governance and metadata management.

Introducing the Apache Spark troubleshooting agent for Amazon EMR and AWS Glue
In this post, we show you how the Apache Spark troubleshooting agent helps analyze Apache Spark issues by providing detailed root causes and actionable recommendations. You’ll learn how to streamline your troubleshooting workflow by integrating this agent with your existing monitoring solutions across Amazon EMR and AWS Glue.

Introducing Apache Spark upgrade agent for Amazon EMR
In this post, you learn how to assess your existing Amazon EMR Spark applications, use the Spark upgrade agent directly from the Kiro IDE, upgrade a sample e-commerce order analytics Spark application project (including build configs, source code, tests, and data quality validation), and review code changes before rolling them out through your CI/CD pipeline.

How Socure achieved 50% cost reduction by migrating from self-managed Spark to Amazon EMR Serverless
Socure is one of the leading providers of digital identity verification and fraud solutions. Socure’s data science environment includes a streaming pipeline called Transaction ETL (TETL), built on OSS Apache Spark running on Amazon EKS. TETL ingests and processes data volumes ranging from small to large datasets while maintaining high-throughput performance. In this post, we show how Socure was able to achieve 50% cost reduction by migrating the TETL streaming pipeline from self-managed spark to Amazon EMR serverless.