AWS Big Data Blog

Cross-account streaming ingestion for Amazon Redshift
As AWS’s fast, petabyte-scale cloud data warehouse delivering the best price-performance, Amazon Redshift makes it simple and cost-effective to analyze all your data using standard SQL, your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools quickly and securely. Tens of thousands of customers use Amazon Redshift to analyze exabytes of data […]

Use Amazon Redshift Spectrum with row-level and cell-level security policies defined in AWS Lake Formation
Data warehouses and data lakes are key to an enterprise data management strategy. A data lake is a centralized repository that consolidates your data in any format at any scale and makes it available for different kinds of analytics. A data warehouse, on the other hand, has cleansed, enriched, and transformed data that is optimized […]

Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks
Enterprise customers are modernizing their data warehouses and data lakes to provide real-time insights, because having the right insights at the right time is crucial for good business outcomes. To enable near-real-time decision-making, data pipelines need to process real-time or near-real-time data. This data is sourced from IoT devices, change data capture (CDC) services like […]

New row and column interactivity options for tables and pivot tables in Amazon QuickSight – Part 2
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to create and deliver insights to everyone in your organization or even with your customers and partners. You can make your data come to life with rich interactive charts and create beautiful dashboards to share with thousands of users, either directly […]

Store Amazon EMR in-transit data encryption certificates using AWS Secrets Manager
With Amazon EMR, you can use a security configuration to specify settings for encrypting data in transit. When in-transit encryption is configured, you can enable application-specific encryption features, for example: Hadoop HDFS NameNode or DataNode user interfaces use HTTPS Hadoop MapReduce encrypted shuffle uses Transport Layer Security (TLS) Presto nodes internal communication uses SSL/TLS (Amazon […]

Easy analytics and cost-optimization with Amazon Redshift Serverless
Amazon Redshift Serverless makes it easy to run and scale analytics in seconds without the need to setup and manage data warehouse clusters. With Redshift Serverless, users such as data analysts, developers, business professionals, and data scientists can get insights from data by simply loading and querying data in the data warehouse. With Redshift Serverless, […]

Convert Oracle XML BLOB data using Amazon EMR and load to Amazon Redshift
In legacy relational database management systems, data is stored in several complex data types, such XML, JSON, BLOB, or CLOB. This data might contain valuable information that is often difficult to transform into insights, so you might be looking for ways to load and use this data in a modern cloud data warehouse such as […]

Enable federation to Amazon QuickSight accounts with Ping One
Amazon QuickSight is a scalable, serverless, embeddable, machine learning (ML)-powered business intelligence (BI) service built for the cloud that supports identity federation in both Standard and Enterprise editions. Organizations are working towards centralizing their identity and access strategy across all of their applications, including on-premises, third-party, and applications on AWS. Many organizations use Ping One […]
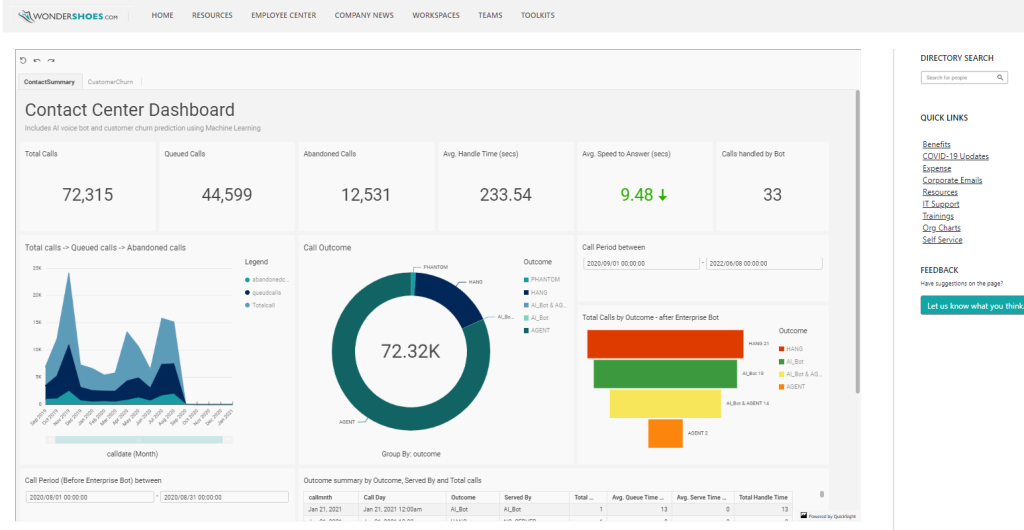
Top Amazon QuickSight features launched in Q2 2022
Amazon QuickSight is a serverless, cloud-based business intelligence (BI) service that brings data insights to your teams and end-users through machine learning (ML)-powered dashboards and data visualizations, which can be accessed via QuickSight or embedded in apps and portals that your users access. This post shares the top QuickSight features and updates launched in Q2 […]

Set up and monitor AWS Glue crawlers using the enhanced AWS Glue UI and crawler history
A data lake is a centralized, curated, and secured repository that stores all your data, both in its original form and prepared for analysis. Setting up and managing data lakes today involves a lot of manual, complicated, and time-consuming tasks. AWS Glue and AWS Lake Formation make it easy to build, secure, and manage data […]