AWS Big Data Blog

Embed Amazon OpenSearch Service dashboards in your application
Customers across diverse industries rely on Amazon OpenSearch Service for interactive log analytics, real-time application monitoring, website search, vector database, deriving meaningful insights from data, and visualizing these insights using OpenSearch Dashboards. Additionally, customers often seek out capabilities that enable effortless sharing of visual dashboards and seamless embedding of these dashboards within their applications, further […]

Seamless integration of data lake and data warehouse using Amazon Redshift Spectrum and Amazon DataZone
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate data lakes or warehouses—hinders visibility and cross-functional analysis. A data mesh framework empowers business units with data ownership and facilitates seamless sharing. However, integrating datasets from different business units can present several […]

Implement data quality checks on Amazon Redshift data assets and integrate with Amazon DataZone
In this post, we show how to capture the data quality metrics for data assets produced in Amazon Redshift. With Amazon DataZone, the data owner can directly import the technical metadata of a Redshift database table and views to the Amazon DataZone project’s inventory. As these data assets gets imported into Amazon DataZone, it bypasses the AWS Glue Data Catalog, creating a gap in data quality integration. This post proposes a solution to enrich the Amazon Redshift data asset with data quality scores and KPI metrics.

Build a serverless data quality pipeline using Deequ on AWS Lambda
Poor data quality can lead to a variety of problems, including pipeline failures, incorrect reporting, and poor business decisions. For example, if data ingested from one of the systems contains a high number of duplicates, it can result in skewed data in the reporting system. To prevent such issues, data quality checks are integrated into […]

Improve the resilience of Amazon Managed Service for Apache Flink application with system-rollback feature
This post explores how to use the system-rollback feature in Managed Service for Apache Flink.We discuss how this functionality improves your application’s resilience by providing a highly available Flink application. Through an example, you will also learn how to use the APIs to have more visibility of the application’s operations.

Organize content across business units with enterprise-wide data governance using Amazon DataZone domain units and authorization policies
Amazon DataZone has announced a set of new data governance capabilities—domain units and authorization policies—that enable you to create business unit-level or team-level organization and manage policies according to your business needs. In this post, we discuss common approaches to structuring domain units, use cases that customers in the healthcare and life sciences (HCLS) industry encounter, and how to get started with the new domain units and authorization policies features from Amazon DataZone.
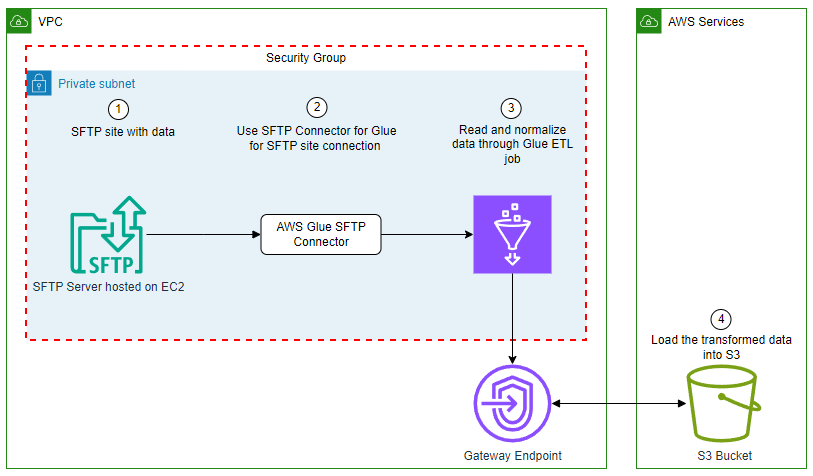
Use AWS Glue to streamline SFTP data processing
In this blog post, we explore how to use the SFTP Connector for AWS Glue from the AWS Marketplace to efficiently process data from Secure File Transfer Protocol (SFTP) servers into Amazon Simple Storage Service (Amazon S3), further empowering your data analytics and insights.

Automate Amazon Redshift Advisor recommendations with email alerts using an API
Amazon Redshift Advisor offers recommendations about optimizing your Redshift cluster performance and helps you save on operating costs. In this post, we show you how to use the ListRecommendations API to set up email notifications for Advisor recommendations on your Redshift cluster. These recommendations, such as identifying tables that should be vacuumed to sort the data or finding table columns that are candidates for compression, can help improve performance and save costs.

Migrate Amazon Redshift from DC2 to RA3 to accommodate increasing data volumes and analytics demands
As businesses strive to make informed decisions, the amount of data being generated and required for analysis is growing exponentially. This trend is no exception for Dafiti, an ecommerce company that recognizes the importance of using data to drive strategic decision-making processes. With the ever-increasing volume of data available, Dafiti faces the challenge of effectively managing and extracting valuable insights from this vast pool of information to gain a competitive edge and make data-driven decisions that align with company business objectives. The growing need for storage space to maintain data from over 90 sources and the functionality available on the new Amazon Redshift node types, including managed storage, data sharing, and zero-ETL integrations, led us to migrate from DC2 to RA3 nodes. In this post, we share how we handled the migration process and provide further impressions of our experience.

How AppsFlyer modernized their interactive workload by moving to Amazon Athena and saved 80% of costs
AppsFlyer develops a leading measurement solution focused on privacy, which enables marketers to gauge the effectiveness of their marketing activities and integrates them with the broader marketing world, managing a vast volume of 100 billion events every day. This post explores how AppsFlyer modernized their Audiences Segmentation product by using Amazon Athena.