AWS Big Data Blog
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently.
Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine learning (ML) using open source frameworks such as Apache Spark, Apache Hive, and Presto. Amazon EMR is the best place to run Apache Spark. You can quickly and effortlessly create managed Spark clusters from the AWS Management Console, AWS Command Line Interface (AWS CLI), or Amazon EMR API. You can also use additional Amazon EMR features, including fast Amazon Simple Storage Service (Amazon S3) connectivity using the Amazon EMR File System (EMRFS), integration with the Amazon EC2 Spot market and the AWS Glue Data Catalog, and EMR Managed Scaling to add or remove instances from your cluster. Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks, and tools like Spark UI and YARN Timeline Service to simplify debugging.
To unlock the potential hidden within the data troves, it’s essential to go beyond traditional analytics. Enter generative AI, a cutting-edge technology that combines ML with creativity to generate human-like text, art, and even code. Amazon Bedrock is the most straightforward way to build and scale generative AI applications with foundation models (FMs). Amazon Bedrock is a fully managed service that makes FMs from Amazon and leading AI companies available through an API, so you can quickly experiment with a variety of FMs in the playground, and use a single API for inference regardless of the models you choose, giving you the flexibility to use FMs from different providers and keep up to date with the latest model versions with minimal code changes.
In this post, we explore how you can supercharge your data analytics with generative AI using Amazon EMR, Amazon Bedrock, and the pyspark-ai library. The pyspark-ai library is an English SDK for Apache Spark. It takes instructions in English language and compiles them into PySpark objects like DataFrames. This makes it straightforward to work with Spark, allowing you to focus on extracting value from your data.
Solution overview
The following diagram illustrates the architecture for using generative AI with Amazon EMR and Amazon Bedrock.
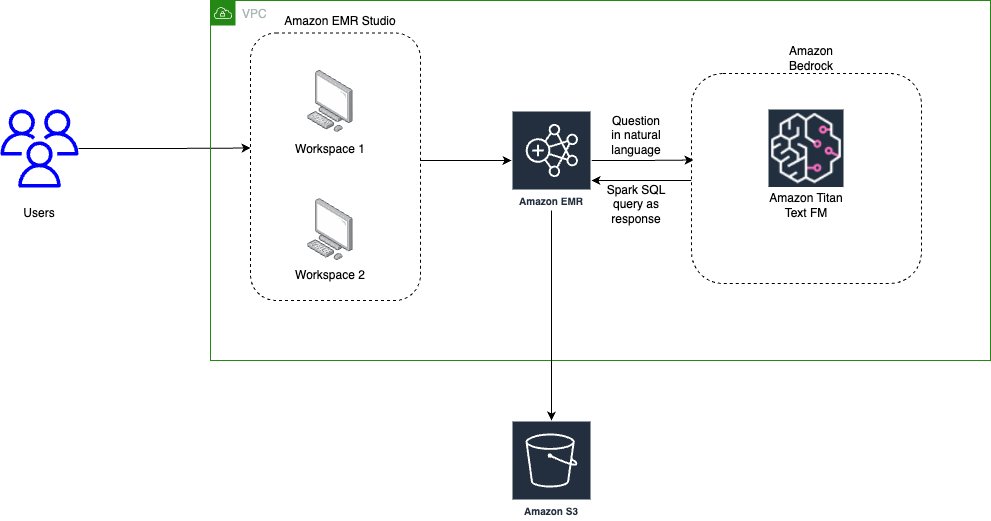
EMR Studio is a web-based IDE for fully managed Jupyter notebooks that run on EMR clusters. We interact with EMR Studio Workspaces connected to a running EMR cluster and run the notebook provided as part of this post. We use the New York City Taxi data to garner insights into various taxi rides taken by users. We ask the questions in natural language on top of the data loaded in Spark DataFrame. The pyspark-ai library then uses the Amazon Titan Text FM from Amazon Bedrock to create a SQL query based on the natural language question. The pyspark-ai library takes the SQL query, runs it using Spark SQL, and provides results back to the user.
In this solution, you can create and configure the required resources in your AWS account with an AWS CloudFormation template. The template creates the AWS Glue database and tables, S3 bucket, VPC, and other AWS Identity and Access Management (IAM) resources that are used in the solution.
The template is designed to demonstrate how to use EMR Studio with the pyspark-ai package and Amazon Bedrock, and is not intended for production use without modification. Additionally, the template uses the us-east-1 Region and may not work in other Regions without modification. The template creates resources that incur costs while they are in use. Follow the cleanup steps at the end of this post to delete the resources and avoid unnecessary charges.
Prerequisites
Before you launch the CloudFormation stack, ensure you have the following:
- An AWS account that provides access to AWS services
- An IAM user with an access key and secret key to configure the AWS CLI, and permissions to create an IAM role, IAM policies, and stacks in AWS CloudFormation
- The Titan Text G1 – Express model is currently in preview, so you need to have preview access to use it as part of this post
Create resources with AWS CloudFormation
The CloudFormation creates the following AWS resources:
- A VPC stack with private and public subnets to use with EMR Studio, route tables, and NAT gateway.
- An EMR cluster with Python 3.9 installed. We are using a bootstrap action to install Python 3.9 and other relevant packages like pyspark-ai and Amazon Bedrock dependencies. (For more information, refer to the bootstrap script.)
- An S3 bucket for the EMR Studio Workspace and notebook storage.
- IAM roles and policies for EMR Studio setup, Amazon Bedrock access, and running notebooks
To get started, complete the following steps:
- Choose Launch Stack:

- Select I acknowledge that this template may create IAM resources.
The CloudFormation stack takes approximately 20–30 minutes to complete. You can monitor its progress on the AWS CloudFormation console. When its status reads CREATE_COMPLETE, your AWS account will have the resources necessary to implement this solution.
Create EMR Studio
Now you can create an EMR Studio and Workspace to work with the notebook code. Complete the following steps:
- On the EMR Studio console, choose Create Studio.
- Enter the Studio Name as
GenAI-EMR-Studioand provide a description. - In the Networking and security section, specify the following:
- For VPC, choose the VPC you created as part of the CloudFormation stack that you deployed. Get the VPC ID using the CloudFormation outputs for the VPCID key.
- For Subnets, choose all four subnets.
- For Security and access, select Custom security group.
- For Cluster/endpoint security group, choose
EMRSparkAI-Cluster-Endpoint-SG. - For Workspace security group, choose
EMRSparkAI-Workspace-SG.
- In the Studio service role section, specify the following:
- For Authentication, select AWS Identity and Access Management (IAM).
- For AWS IAM service role, choose
EMRSparkAI-StudioServiceRole.
- In the Workspace storage section, browse and choose the S3 bucket for storage starting with
emr-sparkai-<account-id>. - Choose Create Studio.

- When the EMR Studio is created, choose the link under Studio Access URL to access the Studio.

- When you’re in the Studio, choose Create workspace.
- Add
emr-genaias the name for the Workspace and choose Create workspace. - When the Workspace is created, choose its name to launch the Workspace (make sure you’ve disabled any pop-up blockers).

Big data analytics using Apache Spark with Amazon EMR and generative AI
Now that we have completed the required setup, we can start performing big data analytics using Apache Spark with Amazon EMR and generative AI.
As a first step, we load a notebook that has the required code and examples to work with the use case. We use NY Taxi dataset, which contains details about taxi rides.
- Download the notebook file NYTaxi.ipynb and upload it to your Workspace by choosing the upload icon.

- After the notebook is imported, open the notebook and choose
PySparkas the kernel.
PySpark AI by default uses OpenAI’s ChatGPT4.0 as the LLM model, but you can also plug in models from Amazon Bedrock, Amazon SageMaker JumpStart, and other third-party models. For this post, we show how to integrate the Amazon Bedrock Titan model for SQL query generation and run it with Apache Spark in Amazon EMR.
- To get started with the notebook, you need to associate the Workspace to a compute layer. To do so, choose the Compute icon in the navigation pane and choose the EMR cluster created by the CloudFormation stack.

- Configure the Python parameters to use the updated Python 3.9 package with Amazon EMR:
- Import the necessary libraries:
- After the libraries are imported, you can define the LLM model from Amazon Bedrock. In this case, we use amazon.titan-text-express-v1. You need to enter the Region and Amazon Bedrock endpoint URL based on your preview access for the Titan Text G1 – Express model.
- Connect Spark AI to the Amazon Bedrock LLM model for SQL query generation based on questions in natural language:
Here, we have initialized Spark AI with verbose=False; you can also set verbose=True to see more details.
Now you can read the NYC Taxi data in a Spark DataFrame and use the power of generative AI in Spark.
- For example, you can ask the count of the number of records in the dataset:
We get the following response:
Spark AI internally uses LangChain and SQL chain, which hide the complexity from end-users working with queries in Spark.
The notebook has a few more example scenarios to explore the power of generative AI with Apache Spark and Amazon EMR.
Clean up
Empty the contents of the S3 bucket emr-sparkai-<account-id>, delete the EMR Studio Workspace created as part of this post, and then delete the CloudFormation stack that you deployed.
Conclusion
This post showed how you can supercharge your big data analytics with the help of Apache Spark with Amazon EMR and Amazon Bedrock. The PySpark AI package allows you to derive meaningful insights from your data. It helps reduce development and analysis time, reducing time to write manual queries and allowing you to focus on your business use case.
About the Authors
 Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
 Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.