AWS Compute Blog
Building a serverless GIF generator with AWS Lambda: Part 2
In part 1 of this blog post, I explain how a GIF generation service can support a front-end application for video streaming. I compare the performance of a server-based and serverless approach and show how parallelization can significantly improve processing time. I introduce an example application and I walk through the solution architecture.
In this post, I explain the scaling behavior of the example application and consider alternative approaches. I also look at how to manage memory, temporary space, and files in this type of workload. Finally, I discuss the cost of this approach and how to determine if a workload can use parallelization.
To set up the example, visit the GitHub repo and follow the instructions in the README.md file. The example application uses the AWS Serverless Application Model (AWS SAM), enabling you to deploy the application more easily in your own AWS account. This walkthrough creates some resources covered in the AWS Free Tier but others incur cost.
Scaling up the AWS Lambda workers with Amazon EventBridge
There are two AWS Lambda functions in the example application. The first detects the length of the source video and then generates batches of events containing start and end times. These events are put onto the Amazon EventBridge default event bus.
An EventBridge rule matches the events and invokes the second Lambda function. This second function receives the events, which have the following structure:
{
"version": "0",
"id": "06a1596a-1234-1234-1234-abc1234567",
"detail-type": "newVideoCreated",
"source": "custom.gifGenerator",
"account": "123456789012",
"time": "2021-0-17T11:36:38Z",
"region": "us-east-1",
"resources": [],
"detail": {
"key": "long.mp4",
"start": 2250,
"end": 2279,
"length": 3294.024,
"tsCreated": 1623929798333
}
}
The detail attribute contains the unique start and end time for the slice of work. Each Lambda invocation receives a different start and end time and works on a 30-second snippet of the whole video. The function then uses FFMPEG to download the original video from the source Amazon S3 bucket and perform the processing for its allocated time slice.
The EventBridge rule matches events and invokes the target Lambda function asynchronously. The Lambda service scales up the number of execution environments in response to the number of events:
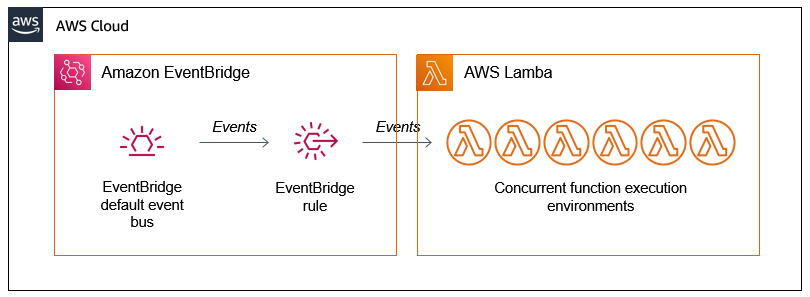
The first function produces batches of events almost simultaneously but the worker function takes several seconds to process a single request. If there is no existing environment available to handle the request, the Lambda scales up to process the work. As a result, you often see a high level of concurrency when running this application, which is how parallelization is achieved:

Lambda continues to scale up until it reaches the initial burst concurrency quotas in the current AWS Region. These quotas are between 500 and 3000 execution environments per minute initially. After the initial burst, concurrency scales by an additional 500 instances per minute.
If the number of events is higher, Lambda responds to EventBridge with a throttling error. The EventBridge service retries the events with exponential backoff for 24 hours. Once Lambda is scaled sufficiently or existing execution environments become available, the events are then processed.
This means that under exceptional levels of heavy load, this retry pattern adds latency to the overall GIF generation task. To manage this, you can use Provisioned Concurrency to ensure that more execution environments are available during periods of very high load.
Alternative ways to scale the Lambda workers
The asynchronous invocation mode for Lambda allows you to scale up worker Lambda functions quickly. This is the mode used by EventBridge when Lambda functions are defined as targets in rules. The other benefit of using EventBridge to decouple the two functions in this example is extensibility. Currently, the events have only a single consumer. However, you can add new capabilities to this application by building new event consumers, without changing the producer logic. Note that using EventBridge in this architecture costs $1 per million events put onto the bus (this cost varies by Region). Delivery to targets in EventBridge is free.
This design could similarly use Amazon SNS, which also invokes consuming Lambda functions asynchronously. This costs $0.50 per million messages and delivery to Lambda functions is free (this cost varies by Region). Depending on if you use EventBridge capabilities, SNS may be a better choice for decoupling the two Lambda functions.
Alternatively, the first Lambda function could invoke the second function by using the invoke method of the Lambda API. By using the AWS SDK for JavaScript, one Lambda function can invoke another directly from the handler code. When the InvocationType is set to ‘Event’, this invocation occurs asynchronously. That means that the calling function does not wait for the target function to finish before continuing.
This direct integration between two Lambda services is the lowest latency alternative. However, this limits the extensibility of the solution in the future without modifying code.
Managing memory, temp space, and files
You can configure the memory for a Lambda function up to 10,240 MB. However, the temporary storage available in /tmp is always 512 MB, regardless of memory. Increasing the memory allocation proportionally increases the amount of virtual CPU and network bandwidth available to the function. To learn more about how this works in detail, watch Optimizing Lambda performance for your serverless applications.
The original video files used in this workload may be several gigabytes in size. Since these may be larger than the /tmp space available, the code is designed to keep the movie file in memory. As a result, this solution works for any length of movie that can fit into the 10 GB memory limit.
The FFMPEG application expects to work with local file systems and is not designed to work with object stores like Amazon S3. It can also read video files from HTTP endpoints, so the example application loads the S3 object over HTTPS instead of downloading the file and using the /tmp space. To achieve this, the code uses the getSignedUrl method of the S3 class in the SDK:
// Configure S3
const AWS = require('aws-sdk')
AWS.config.update({ region: process.env.AWS_REGION })
const s3 = new AWS.S3({ apiVersion: '2006-03-01' })
// Get signed URL for source object
const params = {
Bucket: record.s3.bucket.name,
Key: record.s3.object.key,
Expires: 300
}
const url = s3.getSignedUrl('getObject', params)
The resulting URL contains credentials to download the S3 object over HTTPs. The Expires attributes in the parameters determines how long the credentials are valid for. The Lambda function calling this method must have appropriate IAM permissions for the target S3 bucket.
The GIF generation Lambda function stores the output GIF and JPG in the /tmp storage space. Since the function can be reused by subsequent invocations, it’s important to delete these temporary files before each invocation ends. This prevents the function from using all of the /tmp space available. This is handled by the tmpCleanup function:
const fs = require('fs')
const path = require('path')
const directory = '/tmp/'
// Deletes all files in a directory
const tmpCleanup = async () => {
console.log('Starting tmpCleanup')
fs.readdir(directory, (err, files) => {
return new Promise((resolve, reject) => {
if (err) reject(err)
console.log('Deleting: ', files)
for (const file of files) {
const fullPath = path.join(directory, file)
fs.unlink(fullPath, err => {
if (err) reject (err)
})
}
resolve()
})
})
}
When the GenerateFrames parameter is set to true in the AWS SAM template, the worker function generates one frame per second of video. For longer videos, this results in a significant number of files. Since one of the dimensions of S3 pricing is the number of PUTs, this function increases the cost of the workload when using S3.
For applications that are handling large numbers of small files, it can be more cost effective to use Amazon EFS and mount the file system to the Lambda function. EFS charges based upon data storage and throughput, instead of number of files. To learn more about using EFS with Lambda, read this Compute Blog post.
Calculating the cost of the worker Lambda function
While parallelizing Lambda functions significantly reduces the overall processing time in this case, it’s also important to calculate the cost. To process the 3-hour video example in part 1, the function uses 345 invocations with 4096 MB of memory. Each invocation has an average duration of 4,311 ms.
Using the AWS Pricing Calculator, and ignoring the AWS Free Tier allowance, the cost to process this video is approximately $0.10.

There are additional charges for other services used in the example application, such as EventBridge and S3. However, in terms of compute cost, this may compare favorably with server-based alternatives that you may have to scale manually depending on traffic. The exact cost depends upon your implementation and latency needs.
Deciding if a workload can be parallelized
The GIF generation workload is a good candidate for parallelization. This is because each 30-second block of work is independent and there is no strict ordering requirement. The end result is not impacted by the order that the GIFs are generated in. Each GIF also takes several seconds to generate, which is why the time saving comparison with the sequential, server-based approach is so significant.
Not all workloads can be parallelized and in many cases the work duration may be much shorter. This workload interacts with S3, which can scale to any level of read or write traffic created by the worker functions. You may use other downstream services that cannot scale this way, which may limit the amount of parallel processing you can use.
To learn more about designing and operating Lambda-based applications, read the Lambda Operator Guide.
Conclusion
Part 2 of this blog post expands on some of the advanced topics around scaling Lambda in parallelized workloads. It explains how the asynchronous invocation mode of Lambda scales and different ways to scale the worker Lambda function.
I cover how the example application manages memory, files, and temporary storage space. I also explain how to calculate the compute cost of using this approach, and considering if you can use parallelization in a workload.
For more serverless learning resources, visit Serverless Land.