AWS Compute Blog
Category: Best Practices
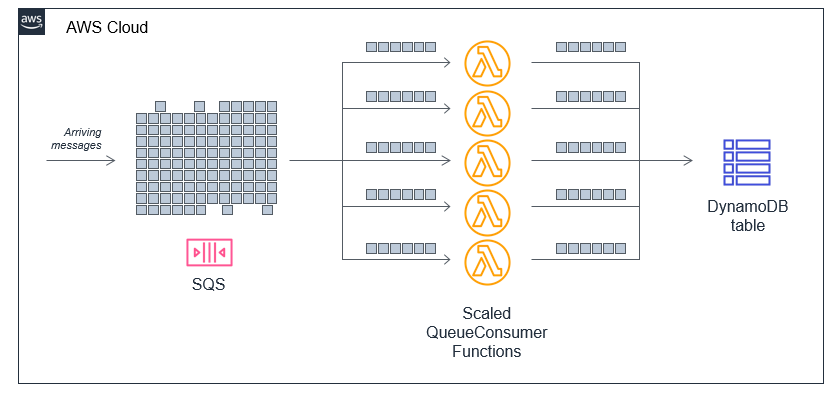
Operating Lambda: Application design – Scaling and concurrency: Part 2
This post explains scaling and concurrency in Lambda and the different behaviors of on-demand and Provisioned Concurrency. It also shows how to use service integrations and asynchronous patterns in Lambda-based applications. Finally, I discuss how reserved concurrency works and how to use it in your application design.
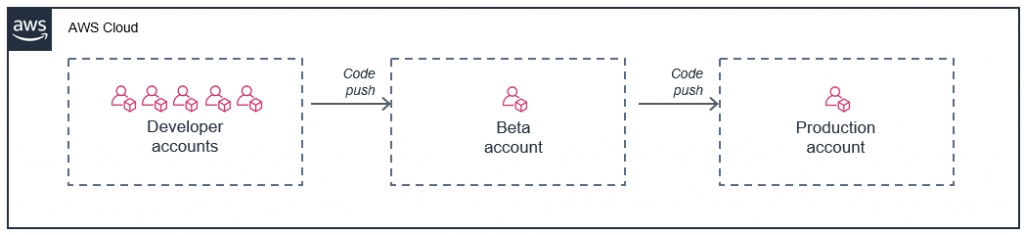
Operating Lambda: Application design and Service Quotas – Part 1
Lambda works with other AWS services to process and manage requests and data. This post explains how to understand and manage Service Quotas, when to request increases, and architecting with quotas in mind. It also explains how to control traffic for downstream server-based resources.

Running cost optimized Spark workloads on Kubernetes using EC2 Spot Instances
This post is written by Kinnar Sen, Senior Solutions Architect, EC2 Spot Apache Spark is an open-source, distributed processing system used for big data workloads. It provides API operations to perform multiple tasks such as streaming, extract transform load (ETL), query, machine learning (ML), and graph processing. Spark supports four different types of cluster managers (Spark standalone, Apache […]

Operating Lambda: Anti-patterns in event-driven architectures – Part 3
This post discusses anti-pattern in event-driven architectures using Lambda. I show some of the issues when using monolithic Lambda functions or using custom code to orchestrate workflows. I explain how to avoid recursive architectures that cause loops and why you should avoid functions calling functions.

How to monitor Windows and Linux servers and get internal performance metrics
This post was written by Dean Suzuki, Solution Architect Manager. Customers who run Windows or Linux instances on AWS frequently ask, “How do I know if my disks are almost full?” or “How do I know if my application is using all the available memory and is paging to disk?” This blog helps answer these […]
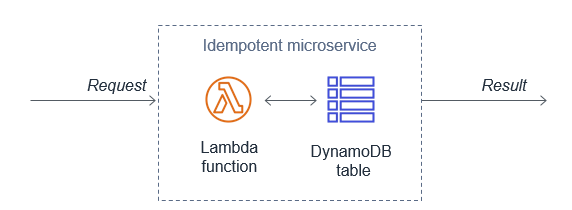
Operating Lambda: Design principles in event-driven architectures – Part 2
This post discusses the design principles that can help you develop well-architected serverless applications. I explain why using services instead of code can help improve your application’s agility and scalability. I also show how statelessness and function design also contribute to good application architecture.
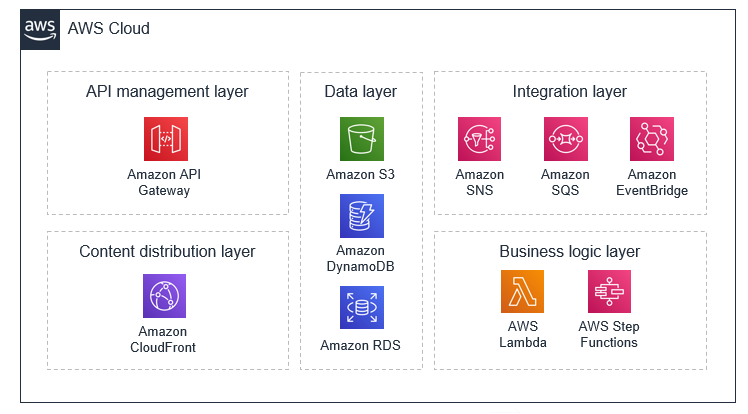
Operating Lambda: Understanding event-driven architecture – Part 1
Event-driven architectures have grown in popularity in modern organizations. This approach promotes the use of microservices, which can be designed as Lambda-based applications. This post discusses the benefits of the event-driven approach, along with the trade-offs involved.

Introducing Spot Blueprints, a template generator for frameworks like Kubernetes and Apache Spark
This post is authored by Deepthi Chelupati, Senior Product Manager for Amazon EC2 Spot Instances, and Chad Schmutzer, Principal Developer Advocate for Amazon EC2 Customers have been using EC2 Spot Instances to save money and scale workloads to new levels for over a decade. Launched in late 2009, Spot Instances are spare Amazon EC2 compute […]
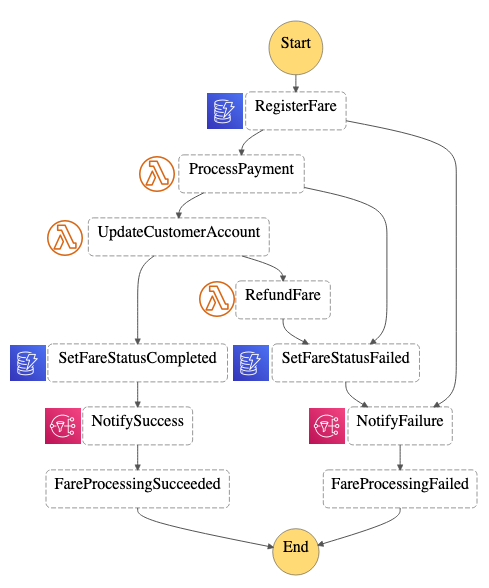
Application integration patterns for microservices: Orchestration and coordination
Using Wild Rydes, I show how to use Amazon SQS and AWS Step Functions to decouple your application components and services. I show you how these services help to coordinate and orchestrate distributed components to build resilient and fault tolerant microservices architectures.

Application integration patterns for microservices: Running distributed RFQs
In this blog, I present the scatter-gather pattern, which is a composite pattern based on pub-sub and point-to-point messaging channels. It also employs correlation ID and return address. I show how this is implemented in the Wild Rydes example application. You can use this integration pattern for communication in your microservices.