AWS Database Blog
Category: Analytics

Writing results from an Athena query to Amazon DynamoDB
Many industries are taking advantage of the Internet of Things (IoT) to track information from and about connected devices. One example is the energy industry, which is using smart electricity meters to collect energy consumption from customers for analytics and control purposes. Vector, a New Zealand energy company, combines its energy knowledge with Amazon Web […]

Export and analyze Amazon QLDB journal data using AWS Glue and Amazon Athena
Amazon Quantum Ledger Database (Amazon QLDB) is a fully managed ledger database that maintains a complete, immutable record of every change committed to the database. As transactions are committed to the database, they are appended to a transaction log called a journal and are cryptographically hash-chained to the previous transaction. Once committed, the record of […]

Access Bitcoin and Ethereum open datasets for cross-chain analytics
In this post, we share an open-source solution for running cross-chain analytics on public blockchain data along with public datasets for Bitcoin and Ethereum available through AWS Open Data. These datasets are still experimental and are not recommended for production workloads. You can find the open-source project on GitHub here and the public blockchain datasets […]

Modernize legacy databases using event sourcing and CQRS with AWS DMS
When moving from monoliths to microservices, you often need to propagate the same data from the monolith into multiple downstream data stores. These include purpose-built databases serving microservices as part of a decomposition project, Amazon Simple Storage Service (Amazon S3) for hydrating a data lake, or as part of a long-running command query responsibility segregation […]

Migrate from Azure Cosmos DB to Amazon DynamoDB using AWS Glue
To take advantage of the performance, security, and scale of Amazon DynamoDB, customers want to migrate their data from their existing NoSQL databases in a way that is cost-optimized and performant. In this post, we show you how to migrate data from Azure Cosmos DB to Amazon DynamoDB through an offline migration approach using AWS […]

Archive data from Amazon DynamoDB to Amazon S3 using TTL and Amazon Kinesis integration
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In this post, we share how you can use Amazon Kinesis integration and the Amazon DynamoDB Time to Live (TTL) feature to design data archiving. Archiving old […]

Combine Amazon Neptune and Amazon OpenSearch Service for geospatial queries
Many AWS customers are looking to solve their business problems by storing and integrating data across a combination of purpose-built databases. The reason for that is purpose-built databases provide innovative ways to build data access patterns that would be challenging or inefficient to solve otherwise. For example, we can model highly connected geospatial data as […]
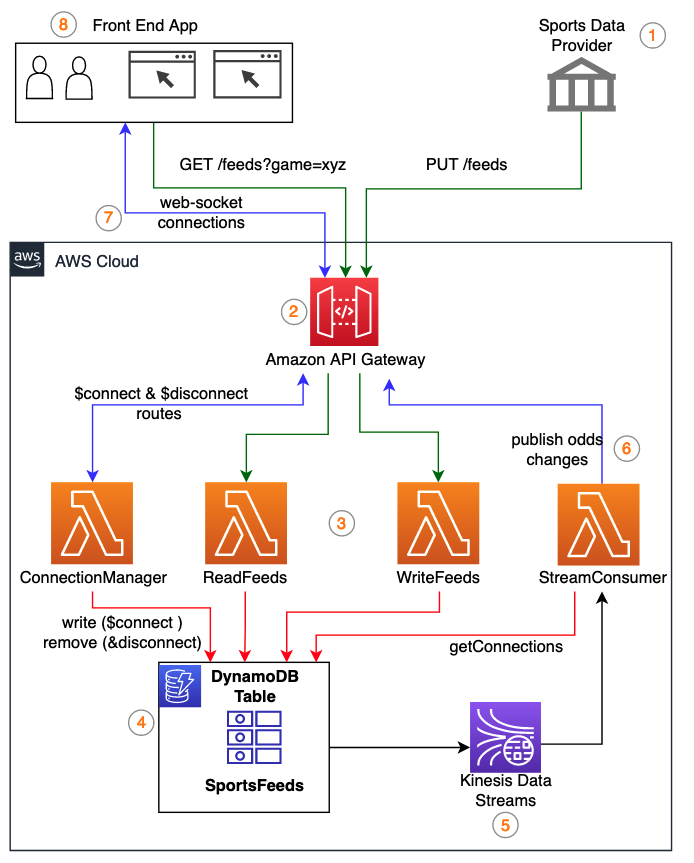
Store and stream sports data feeds using Amazon DynamoDB and Amazon Kinesis Data Streams
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Online bookmakers are innovating to offer their clients continuously updated sports data feeds that allow betting throughout the duration of matches. In this post, we walk through […]

Build interactive graph data analytics and visualizations using Amazon Neptune, Amazon Athena Federated Query, and Amazon QuickSight
Customers have asked for a way to interact with graph datasets in Amazon Neptune using business intelligence (BI) tools such as Amazon QuickSight. Although some BI tools offer generic HTTP connectors that allow you to define a set of REST API calls to extract data from REST endpoints, you have to predefine either Gremlin or […]

Build a fault-tolerant, serverless data aggregation pipeline with exactly-once processing
The business problem of real-time data aggregation is faced by customers in various industries like manufacturing, retail, gaming, utilities, and financial services. In a previous post, we discussed an example from the banking industry: real-time trade risk aggregation. Typically, financial institutions associate every trade that is performed on the trading floor with a risk value […]