AWS Database Blog
Evolution of Koo’s database and how they connected millions of voices using Amazon DynamoDB
This post is co-authored with Vivek Yadav from Koo.
Koo is a global micro-blogging platform that allows users to share their thoughts and opinions in various languages. Launched in March 2020, the app has quickly gained immense popularity, with millions of users joining the platform to share their views and connect with like-minded individuals.
In a World as diverse as ours, language plays a critical role in communication, and Koo recognized the importance of enabling users to express themselves in the language they are most comfortable with. The app’s interface is available in several languages, including English, Hindi, Portuguese, Spanish, and more. This focus on enabling users to communicate in their preferred language has played a crucial role in the app’s success.
The Koo app has received appreciation from all quarters, and won the Aatmanirbhar App Innovation Challenge held by the Indian government in 2020. It was also named Google PlayStore’s Best Daily Essential App for 2020. Koo currently supports over 20 different languages, has been downloaded over 60 million times, is actively used by 8,000 eminent profiles, and has become the second largest micro-blogging platform in just 3 years.
AWS has been a partner in Koo’s growth journey, providing the platform with a reliable and scalable infrastructure that has helped it grow seamlessly.
Koo was born in the cloud, and embraced microservices, containers, AI, machine learning (ML), and other cutting-edge technologies. In its early days, Koo used a monolithic data architecture with a centralized relational database server to handle all data operations. As the platform expanded globally and added support for more languages, the number of users grew from 20 million to 60 million. With the growth of the user base, the content on the platform and the interactions (likes, shares, and reposts) grew exponentially. The monolithic relational database couldn’t keep up and faced performance and scalability challenges.
In this post, we share the evolution of Koo’s data architecture from a central monolithic relational database to a distributed database. We cover the architectural and operational challenges that Koo faced with their previous data architecture, how they welcomed the NoSQL thought process for their use cases where the transactions can be eventually consistent, how they adopted Amazon DynamoDB—a fully managed, serverless, key-value NoSQL database—to overcome those challenges, and how they migrated their data to support their scalability requirements.
Monolithic data architecture at Koo
Koo has streamlined its core functionalities into a set of simplified, scalable, and robust microservices to make it easier for their engineers to roll out new features to their users as frequently as possible. Koo’s web and mobile apps consume these internal microservices using exposed APIs, which are deployed in Amazon Elastic Kubernetes Service (Amazon EKS). The following figure shows Koo’s initial application and data platform architecture.

The following are some of the Koo application microservices:
- Onboarding –This service helps users join the Koo platform using their social media or email accounts.
- Feed – After signing in, Koo users expect to see content that is relevant to them. The content that is served usually includes the latest trending and highly engaging content (called Koos) from each user’s network. This service prepares and serves the feeds for signed-in users within a few milliseconds.
- Recommender – Koo users want content that is personalized and fresh. The recommender service is responsible for applying the priorities for the retrieved feed based on various parameters.
- Discovery – After a new user signs up with Koo, their Day 0 journey is a clean slate. To improve their engagement with the app, this service is responsible for giving the user suggestions to follow relevant Koo user profiles.
- Notification – To improve engagement with content, this service initiates push and email notifications to millions of users.
Koo started with all the microservices’ transactional data stored, managed, and consumed on a monolithic relational database using Amazon Aurora PostgreSQL-Compatible Edition. The database is a three-node cluster with one writer and two readers deployed in multiple AWS Availability Zones for high availability. The data pipelines are built using AWS Glue jobs and Amazon Managed Streaming for Apache Kafka (Amazon MSK) to capture the changes made to data in the database and deliver them to a centralized data lake set up on Amazon Simple Storage Service (Amazon S3).
Koo does data transformations and processing using Amazon EMR with Apache Spark and Apache Flink jobs accessing data from various stores such as Amazon S3, Apache Iceberg tables, and more. Koo uses Amazon SageMaker for MLOps to deliver high-performance production ML models that help in classifying, performing sentiment analysis on, and personalizing content to provide rich user engagement and experiences. The models do this by continuously running against the streaming and batch data in the pipelines to calculate various scores and then update them back to the central database so the microservices can use these scores to prepare highly engaging feeds for Koo’s users.
The challenges
When launched in India in 2020, Koo supported four Indian languages (Hindi, Kannada, Tamil, and Telugu) and English. Koo has a vision of onboarding more and more users onto its app that necessitated its application and data platform supporting 20 times their current scale. Since 2020, Koo has expanded geographically to Nigeria, the United States, Brazil, and more, and has added support for more than 20 languages. In early 2022, they faced scalability and performance challenges with their workloads.
Koos didn’t face those issues on their microservices deployment because they deployed using Amazon EKS, which scales to meet the changing demands. But that wasn’t the case with their central database.
Koo faced the following operational challenges:
- Steep drops of freeable memory on the reader instance.
- Increasing query response time due to Lock:tuple events.
- Autovacuum was running on the toast table in the truncating heap phase on the writer with an ACCESS EXCLUSIVE lock, which blocked the reader serving the user requests. This impacted the writer’s performance (to learn more, see Understanding autovacuum in Amazon RDS for PostgreSQL environments).
They also faced the following architectural challenges:
- Relational databases limit the number of readers that you can implement. Vertical scaling wasn’t an option because Koo was using AWS Graviton2 processor-based high-end instance types for their Aurora PostgreSQL writer and readers.
- High latency due to the concurrent reads and writes from different microservices and data pipelines.
- Homogeneity of technology and a lack of modularity because Koo adopted a single database for the application, even if not all the use cases were a natural fit for a relational database.
Reinventing data architecture at Koo
To meet their business requirements and overcome the challenges, Koo realized they had to reimagine their data persistence layer and reinvent their data architecture. They decided to decompose their data architecture into purpose-built databases based on their use cases. Koo chose key-value NoSQL databases because they can handle the scaling of large amounts of data and extremely high volumes of state changes while servicing millions of simultaneous users through distributed processing and storage.
“The best part of microservices is the freedom to allocate dedicated databases to some services and use shared databases for others,”
– Vivek Yadav, Vice President of Engineering at Koo.
Because Koo built the microservices for their applications from inception, taking the next step to NoSQL was quite natural.
The AWS team, in partnership with Koo, took the following steps to help them on their key-value NoSQL journey.
Identify critical user paths
The first step was to identify the critical user paths that were most important to Koo business and plot them against various parameters such as latency sensitivity, throughput requirements, and more. For Koo, we plotted the paths against each parameter as shown in the following table.

The user paths were as follows:
- Koos, Reactions, and User Signups – For the first three paths, we found all the parameters as applicable. They require partition-based lookups, sorting, high input and output operations per second (IOPS), and support querying by different attributes.
- Feed – We found that this path requires lookup by the partition key but not by other attributes, and it has high reads but not writes. For this reason, the preceding table shows a mix of applicable and non-applicable features.
- Social Graph and Recommendations – The last two paths also have a mix of requirements.
Define access patterns
The next step was to define access patterns for the first three use cases. As part of the first step of any table design with NoSQL databases, you must list your application access patterns. The following is the list of identified access patterns for the first three user paths:
- Get a Koo detail by its identifier
- Update the Koo by its identifier
- Get the parent and super-parent Koo identifier for a given Koo identifier
- Get Koos by its language (Hindi, Spanish, French, and more)
- Get Koos by its creator
Refactor data models
The third step was to refactor and optimize data models for the preceding use cases for NoSQL databases, both cloud offerings such as DynamoDB and open-source databases.
The most important factor in reducing response time in NoSQL databases is keeping related items as close together as possible, especially when it comes to fulfilling one-to-many and many-to-many relationships, because response time has a major impact on cost and performance. We used a single table design, which helped Koo achieve the first three access patterns of the application based on content (Koo) identifier (CONTENT_ID)
The next important consideration when modeling for NoSQL databases is the partition key design. A good partition key design distributes the I/O requests effectively and avoids creating one hot (heavily requested) partition. We used 64-bit UUID as the partition key for uniquely identifying each Koo and for even distribution of items across partitions. See Best practices for designing and using partition keys effectively to learn more about partition key design.
The following screenshot shows the data model of the base table.
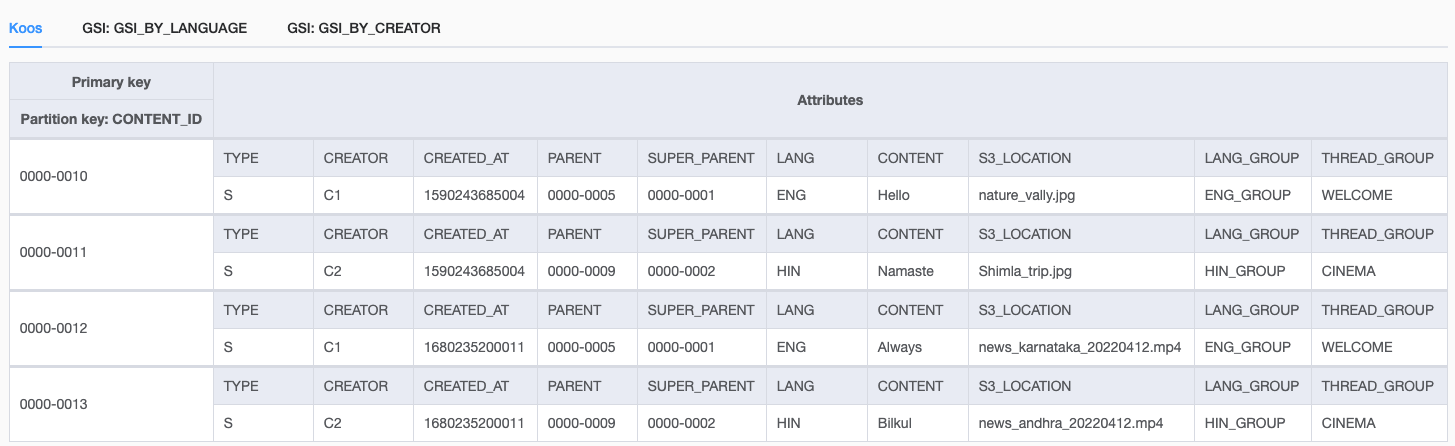
The table stores information about each Koo using attributes such as CONTENT_ID, PARENT, SUPER_PARENT, CREATOR (the author), S3_LOCATION (the associated media file), and more. The CONTENT_ID is used as the primary key and partition key.
When modeling for DynamoDB, the total size of an item is the sum of its attribute name lengths and values. Having long attribute names not only contributes towards storage costs, but it can lead to higher read capacity unit (RCU) and write capacity unit (WCU) consumption. Therefore, we chose shorter attribute names, as shown in the table design.
We shortened the attribute values as well. For example, we preferred to store the media file’s Amazon S3 key location identifier value for the attribute S3_LOCATION, rather than the entire universal resource identifier (URI). If you look at row 1 in the preceding table, instead of storing the URI as s3://<BUCKET_NAME>/<CREATOR_ID>/nature_valley.jpg, we stored its shortened value, nature_valley.jpg, because the other values can be derived. To learn more about the best practices on how to optimize costs while designing for your DynamoDB tables, see Optimizing costs on DynamoDB tables.
The last two access patterns required a list of Koos either by their language or by their creator, so we created two global secondary indexes (GSI) on the base table.
The following table shows the data model for the GSI by language. The partition key is the attribute LANG_GROUP, and the sort key is the attribute CREATED_AT.

The following table shows the data model of the GSI by Koo creator. The partition key is the attribute CREATOR, and the sort key is the attribute CREATED_AT.

Benchmark performance
We benchmarked the performance for the top two use cases: Koos and reactions. Koo initially prepared a production-like environment with the full data loaded into various NoSQL database tables as the base load for benchmarking. They then used K6—an open-source load testing tool for performance benchmarking—deployed as a Kubernetes operator in their EKS cluster to run distributed load tests. The benchmarks were run for 48 hours, and the load was gradually increased from its base production-like traffic up to 40,000 requests per second with the load characteristics controlled through custom scripts. The following screenshot shows the result of the benchmarking exercise conducted on DynamoDB.

The results of the benchmarking test are shown in the following table.
| Legend | Operation | Average Latency in Milliseconds |
|---|---|---|
| Yellow | Reaction: Get | 4.42 |
| Green | Reaction: Write | 5.42 |
| Blue | Content: Get by ID | 4.26 |
| Orange | Content: Get by creator | 6.24 |
| Red | Content: Write | 5.71 |
Koo witnessed consistent performance for 20 times the base product scale during benchmarking on DynamoDB. Not only did they consider the consistent low latency of the read and write operations of the use cases when choosing DynamoDB as their NoSQL data store, they also considered scalability, high availability, and operational ease parameters.
Current architecture
Koo took a multi-database approach and used different databases for different use cases as appropriate. The following figure shows the architecture that Koo implemented to meet the needs of their ever-growing user base, Koos, and reactions.
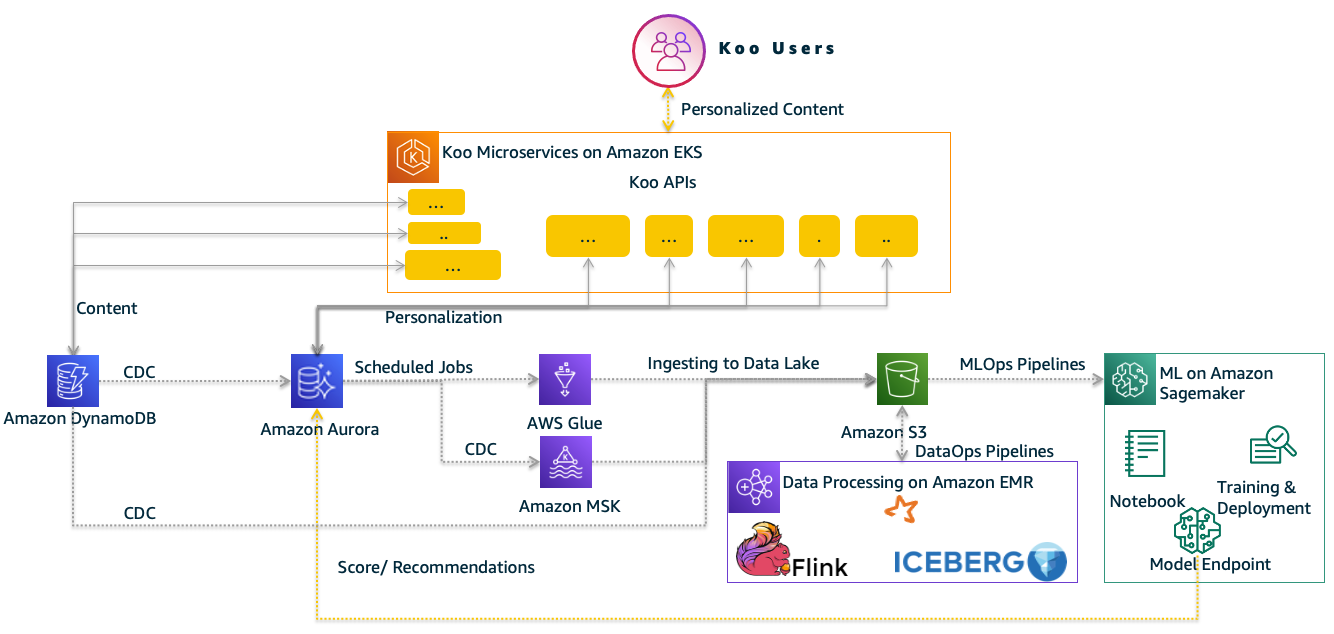
With this architecture, the content is primarily served from DynamoDB tables, and the personalization data is served from Koo’s relational data store. Additionally, Koo started adding other purpose-built databases such as a document database for real-time big data and a graph database for its user graph and more to the architecture.
Battle-tested at international launch
Social networks thrive on virality, and user traffic can come anytime from anywhere, which is good and also creates challenges. The new architecture equips Koo to manage the surges associated with viral growth.
One instance where the benefits of the new architecture were particularly evident for Koo was during a sudden surge when the app was launched internationally in November 2022. A large number of users flocked to Koo from countries like Brazil (see Koo records over 1 mn downloads within 2 days of launch in Brazil for more details) and the US, and started using it extensively. Koo was able to handle the massive spike in traffic without experiencing any performance degradation and kept delivering more and more features to delight the new global user base.
Conclusion
In this post, we shared the challenges that Koo experienced with its monolithic data architecture; how they adopted DynamoDB for their ever-growing Koos, user base, and reactions; and how the new architecture helped them scale geographically.
The new architecture provided Koo increased scalability and improved performance and reliability. DynamoDB has been particularly beneficial by providing Koo with a highly scalable and performant NoSQL database that can handle billions of requests per day with single-digit millisecond latency. Koo is actively exploring migrating other use cases to DynamoDB.
Check out the following resources for more information:
- To learn more about what’s happening behind the scenes at Koo, see their blog posts at Koo Blogs
- For details on maximizing performance and minimizing throughput costs when working with DynamoDB, see Best practices for designing and architecting with DynamoDB
- For information about the benefits of designing a highly transactional online system on DynamoDB, see Data modelling for an internet-scale online transactional system using Amazon DynamoDB
- For more details about table design in DynamoDB, see Single-table vs. multi-table design in Amazon DynamoDB
About the Authors
 Vivek Yadav is VP of Engineering at Koo. With over 14 years of experience in software engineering, he leads the backend systems and data engineering teams at Koo, ensuring that the social network delivers a top-notch user experience and scales globally.
Vivek Yadav is VP of Engineering at Koo. With over 14 years of experience in software engineering, he leads the backend systems and data engineering teams at Koo, ensuring that the social network delivers a top-notch user experience and scales globally.
 Kayalvizhi Kandasamy works with digital-native companies to support their innovation. As a Senior Solutions Architect (APAC) at Amazon Web Services, she uses her experience to help people bring their ideas to life, focusing primarily on microservice architectures and cloud-native solutions using AWS services. Outside of work, she likes playing chess and is a FIDE rated chess player. She also coaches her daughters the art of playing chess, and prepares them for various tournaments.
Kayalvizhi Kandasamy works with digital-native companies to support their innovation. As a Senior Solutions Architect (APAC) at Amazon Web Services, she uses her experience to help people bring their ideas to life, focusing primarily on microservice architectures and cloud-native solutions using AWS services. Outside of work, she likes playing chess and is a FIDE rated chess player. She also coaches her daughters the art of playing chess, and prepares them for various tournaments.
 Soumyadeep Dey is a Database Specialist Solutions Architect with AWS. He works with AWS customers to design scalable, performant, and robust database architectures on the cloud using both SQL and NoSQL database offerings.
Soumyadeep Dey is a Database Specialist Solutions Architect with AWS. He works with AWS customers to design scalable, performant, and robust database architectures on the cloud using both SQL and NoSQL database offerings.