AWS Database Blog
How to migrate from Oracle to Amazon Aurora MySQL using AWS CloudFormation (Part 1)
Database migrations are challenging, especially for heterogeneous database migrations such as Oracle to Amazon Aurora PostgreSQL, Oracle to Amazon Aurora MySQL, or Microsoft SQL Server to MySQL. The schema structure, data types, and database code of source databases can be quite different from those of the target databases, requiring a schema and code transformation step before the data migration starts. This makes heterogeneous migrations a two-step process.
In Part 1 of this two-part migration blog series, we build an AWS CloudFormation stack to deploy resources that will help demonstrate the process of migrating data from an Oracle database to an Amazon Aurora MySQL database . In part 2, we will build on the resources created in this post and show how to extract, transform, and load (ETL) data using AWS Glue.
AWS has intuitive tools like the AWS Schema Conversion Tool (AWS SCT) and the AWS Data Migration Service (AWS DMS) for heterogeneous two-step migrations. These tools help reduce migration overhead and complexities. For more information about these tools and settings for optimizing the migration process, see How to Migrate Your Oracle Database to Amazon Aurora.
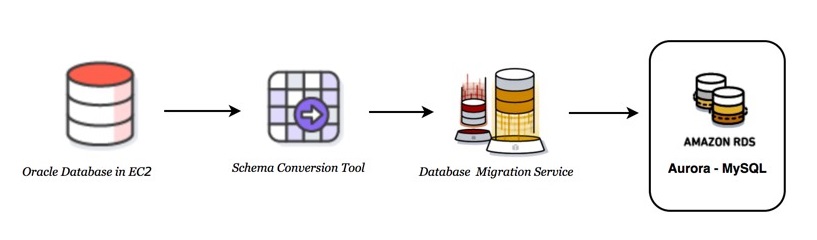
Figure 1: Heterogeneous database migration steps
Our focus in this post is to show you the ease of migration with a self-service working demonstration. It will help you understand and get familiar with AWS SCT and AWS DMS core concepts. AWS DMS now offers free use for 6 months per instance if you’re migrating to Amazon Aurora, Amazon Redshift, or Amazon DynamoDB.
To demonstrate the migration process, we use an AWS CloudFormation script that deploys an Amazon EC2 instance with the Oracle database (HRDATA) pre-installed, an Aurora MySQL cluster, and an AWS DMS replication instance. We use other necessary components like Amazon Virtual Private Cloud (Amazon VPC) and its networking constructs, Amazon S3 buckets, and AWS Identity and Access Management (IAM) roles and policies to aid in the migration process. The AWS CloudFormation stack deployment takes about 10–12 minutes to complete. The overall walkthrough of the example can be done in less than an hour.
Note: The script is designed to work in the Oregon (us-west-2) and Ohio (us-east-2) Regions due to the possibility of running into resource restrictions in other Regions. Also, in part 2, we will be using AWS Glue, which is available only in certain Regions.
Prerequisites
To get started with this migration, do the following:
- Download and install AWS SCT in your laptop or an EC2 instance that has access to the internet.
- Download Oracle and Amazon Aurora MySQL-compatible drivers, and follow the AWS SCT installation instructions to configure the AWS SCT global settings.
- Locate an Amazon EC2 key pair to use in the US West-2 (Oregon) or US East-2 (Ohio) Region. If you don’t have one, create an Amazon EC2 key pair.
- Sign in to the AWS Management Console, and open the IAM console. Under Roles, check to see whether the dms-vpc-role is already present. This is an API/CLI-specific role that is needed for launching an AWS DMS task programmatically. If the role is not present, the AWS CloudFormation stack in the next section will create the role.
Launch the stack
Note: Some of the resources deployed by this stack will incur costs as long as they are in use.
![]()
To get started with deploying the AWS CloudFormation template:
- Choose Launch Stack. This button automatically launches the AWS CloudFormation service in your AWS account with a template to launch. You are prompted to sign-in if needed.
- Ensure that you choose the Ohio or Oregon Region to create the stack. Choose Next.

- Specify a key pair for the EC2 instance, and other parameters as needed. All parameters are required.
- For the DMSVPCRoleExists parameter, choose yes or no based on step 4 of the prerequisites.
- For the MyIP parameter, the default 0.0.0/0 makes port 3306 for open access. We recommend that you use the public IP. (You can check your IP using whatsmyip.org.)
- Most of the parameters take default values. Choose Next.

- On the Review page, acknowledge that AWS CloudFormation will create IAM roles when the stack is launched. Choose Create.

- To see the stack creation progress, choose Refresh. Then select the stack to see the launch events in the Events section below.
 The stack creation takes 7–10 minutes to finish. When the stack is successfully launched, the Status changes from CREATE_IN_PROGRESS to CREATE_COMPLETE.The Output section contains information about the resources deployed by AWS CloudFormation that you need later in this procedure. You can copy these values into a file for easy lookup.
The stack creation takes 7–10 minutes to finish. When the stack is successfully launched, the Status changes from CREATE_IN_PROGRESS to CREATE_COMPLETE.The Output section contains information about the resources deployed by AWS CloudFormation that you need later in this procedure. You can copy these values into a file for easy lookup.
Section 1: Convert existing database schema from source to target using AWS SCT
To proceed with this section, you must have AWS SCT installed as per the prerequisite information. AWS SCT should have access to the internet to connect to resources deployed by AWS CloudFormation.
- Launch AWS SCT.
- Choose File, New Project Wizard.

- In the wizard, provide a name for the project. Choose Oracle as the source, and choose Next.

- Provide the Oracle database connection information. You can find all the required parameters for this step in the Output of the AWS CloudFormation stack deployed previously. Choose Test Connection to ensure that AWS SCT can connect to the Oracle source successfully. Choose Next.

- Choose HRDATA as the schema to be migrated, and choose Next.

- Next you are presented with a Database Migration Assessment Report that provides insights into the migration challenges for various target database engines. This report can help you understand the challenges and choose a target database most suitable for migration. In this post, we are using Amazon Aurora MySQL as the target engine. You can download the report as needed. Choose Next.

- In the target section, provide the Aurora MySQL cluster endpoint in the server name, and use 3306 as the port. Type the user name and password of the Aurora cluster that was provisioned by the AWS CloudFormation stack. Choose Test Connection to ensure that AWS SCT can connect to the Aurora target successfully. Choose Finish.

- After the wizard finishes, you are shown the main view with two panes. The left pane is the source Oracle database, and the right is the target Amazon Aurora MySQL database. To generate a more specific and detailed assessment report, open the context (right-click) menu for the HRDATA schema in the source, and choose Create Report.
 The report provides Action Items that can help a database administrator (DBA) resolve the schema discrepancies in the target for a successful migration.For example: In the source pane, navigate to Views and choose EMP_DETAILS_VIEW. There are two action items for resolving the issues during automatic creation of EMP_DETAILS_VIEW in the target database.
The report provides Action Items that can help a database administrator (DBA) resolve the schema discrepancies in the target for a successful migration.For example: In the source pane, navigate to Views and choose EMP_DETAILS_VIEW. There are two action items for resolving the issues during automatic creation of EMP_DETAILS_VIEW in the target database. AWS SCT is a powerful tool that converts the schema, functions, and stored procedure from the source database to the target database along with action Items.For the scope of this post, the database is simple, and no major action items need to be taken.
AWS SCT is a powerful tool that converts the schema, functions, and stored procedure from the source database to the target database along with action Items.For the scope of this post, the database is simple, and no major action items need to be taken. - In the source Oracle database, open the context (right-click) menu for the HRDATA schema, and choose Convert Schema. The HRDATA schema is created in the target Amazon Aurora MySQL database.
 You are prompted with a warning stating that the objects that already exist in the target will be replaced. Choose Yes to proceed.
You are prompted with a warning stating that the objects that already exist in the target will be replaced. Choose Yes to proceed. - In the target Amazon Aurora MySQL database pane, open the context (right-click) menu for the HRDATA schema, and choose Apply to database.

At this point, you have successfully used the AWS Schema Conversion Tool to generate a database migration assessment report, and you’ve written the HRDATA schema in the target Amazon Aurora MySQL.
AWS SCT automatically converts the source database schema and most of the custom code to a format that is compatible with the target database. Any code that the tool cannot convert automatically is clearly marked so that you can convert it yourself. For best results, save your converted schema to a file as a SQL script, and review the converted schema with a target database expert. The schema should be reviewed and optimized for the target database before proceeding with data migration.
For our purposes, we did not explore the optimization steps for the target database objects. We did a simple conversion of a schema from source to target in AWS SCT.
Now you can proceed with the migration.
Section 2: Migrate data from the source to the target using AWS DMS
In this section, we use AWS DMS to do bulk loading from the Oracle database to the Amazon Aurora MySQL database.
- Sign in to the AWS Management Console and open the AWS DMS console.
- Ensure that you are in the same AWS Region (us-east-2 or us-west-2) in which you deployed the AWS CloudFormation stack in Section 1.
- In the left navigation pane, choose Replication instances. You might notice that the AWS CloudFormation stack already created a new replication instance. Note the virtual private cloud (VPC) of the replication instance. It is the same VPC that was created by the CloudFormation stack.

- In the left navigation pane, choose
- Choose Create endpoint.

- On the Create endpoint page, choose Source, and provide the necessary information about the Oracle source database. The AWS CloudFormation Outputs tab contains the necessary information to complete this step.
 Under Test endpoint connection, choose the VPC replication instance that was created by the AWS CloudFormation stack. Ensure that the test is successful, and then create the source endpoint.
Under Test endpoint connection, choose the VPC replication instance that was created by the AWS CloudFormation stack. Ensure that the test is successful, and then create the source endpoint.
- Similarly, on the Create endpoint page, choose Target, and provide the necessary information about the Aurora MySQL target database. The AWS CloudFormation Outputs section contains the necessary information to complete this step.

- Open the Advanced section, and type the following string as extra connection attributes:
initstmt=SET FOREIGN_KEY_CHECKS=0;parallelLoadThreads=5;maxFileSize=131072Theinitstmt=SET FOREIGN_KEY_CHECKS=0attribute disables foreign key checks in the target Aurora MySQL database. TheparallelLoadThreads=5attribute specifies how many threads to use to load the data into the MySQL target database. ThemaxFileSize=131072attribute specifies the maximum size (128 MB) of a file that is used to transfer data to MySQL. - In the Test endpoint connection section, choose the VPC replication instance that was created by the AWS CloudFormation stack. Ensure that the test is successful, and then create the target endpoint.Note: Don’t execute any DDL statements on the target database while foreign key checks are disabled (for example, throughout the entire AWS DMS migration). Doing so can lead to data dictionary corruption.

- In the left navigation pane, choose Tasks. Then choose Create task.

- In the task settings:
- Choose the replication instance that was deployed by the AWS CloudFormation stack.
- Choose the Oracle endpoint as the source.
- Choose the Amazon Aurora MySQL endpoint as the target.
- For Migration type, choose Migrate existing data. This option allows you to do bulk loading without change data capture (CDC). You can choose other options, but you must enable supplemental logging to allow for CDC.
- Select the Start task on create check box to start loading as soon as the task is created.
- For Target table preparation mode, choose Do Nothing because we used AWS SCT to convert the schemas already.
- Select the Enable validation option to compare each row in the source with its corresponding row at the target, and verify that those rows contain the same data.
- Optionally, select Enable logging to log the task in CloudWatch for troubleshooting or log analysis if needed.

- Finally, in the Table Mappings section, choose the source HRDATA schema to be migrated. For the Table name option, specify the % wildcard for all tables in the schema.
- Choose Add selection rule to add the table mapping rule.

- Choose Create task to proceed.
- After the task is created, it automatically starts loading data from the source to the target database. Choose the task, and in the properties pane below, navigate to Table Statistics to see the progress. The validation state should change from Pending records to Validated. Also ensure that the Total count matches the Full Load Rows values.

At this point, you have successfully migrated the data from the Oracle database to an Amazon Aurora MySQL database. You can optionally connect via a MySQL client to Aurora MySQL and see the loaded data.
Clean up resources
Next, you execute cleanup tasks to remove the AWS resources that were deployed as part of the walkthrough. You can continue to run the resources, but note that they continue to accrue charges as long as they are running.
Note: In Part 2 of this migration series, we show you how to use AWS Glue for ETL processing using the Amazon Aurora MySQL database that is deployed in this post. To complete Part 2, be sure to complete the migration steps in this post.
Follow these steps to delete the resources that were created:
- In the AWS Management Console, open AWS DMS, and choose Tasks in the left navigation pane. Choose the task that you created in Section 2, and choose Delete.

- After the task is deleted, choose Endpoints in the left pane. Delete the Oracle source and Aurora MySQL target endpoints you created as part of Section 2.

- Open the AWS CloudFormation console. Choose the stack that you created previously, and choose Delete. You get a warning about deleting all the resources of the stack. Choose Yes Delete to proceed.

- The deletion process takes 7–10 minutes to complete. It deletes all the resources that were created by the stack. The status shows DELETE_IN_PROGRESS. After the deletion is successful, the stack disappears from the stack list.
At this point, all the resources deployed as part of this exercise have been successfully deleted.
Conclusion
In this post, we saw how easy and straightforward heterogeneous migration can be using the AWS Schema Conversion Tool and AWS Data Migration Service. We showed you how to build a working environment to understand and test migrations from Oracle to Amazon Aurora MySQL databases. You can also customize the AWS CloudFormation script to deploy other database engine types easily and test other migrations.
About the authors
 Sona Rajamani is a solutions architect at AWS. She lives in the San Francisco Bay area and helps customers architect and optimize applications on AWS. In her spare time, she enjoys hiking and traveling.
Sona Rajamani is a solutions architect at AWS. She lives in the San Francisco Bay area and helps customers architect and optimize applications on AWS. In her spare time, she enjoys hiking and traveling.
 Ballu Singh is a solutions architect at AWS. He lives in the San Francisco bay area and helps customers architect and optimize applications on AWS. In his spare time, he enjoys reading and spending time with his family.
Ballu Singh is a solutions architect at AWS. He lives in the San Francisco bay area and helps customers architect and optimize applications on AWS. In his spare time, he enjoys reading and spending time with his family.