AWS Database Blog
Remove temporal tables and history objects while migrating to Amazon DynamoDB using Amazon DynamoDB Streams
Customers at times use proprietary database features like Microsoft SQL Server temporal tables or Oracle Flashback to store and query historical data from important tables or to record a change trail of contents.
Temporal tables are a database feature that brings built-in support for providing information about data stored in the table at any point in time, rather than only the data at the current moment in time, and when not provided by the relational database management systems (RDBMS), developers often set up triggers and stored procedures to populate history tables. Temporal tables increase the number of objects within a database resulting in increase in database size and operational overhead including long-term maintenance, monitoring, and complexity with data migrations.
In this post, we are going to analyse a customer’s historical table use case and discuss how you can migrate to Amazon DynamoDB and use Amazon DynamoDB Streams for change data capture, thereby reducing the object counts and database size and not having to rely on managing temporal tables.
Use case overview
Amazon Database Migration Accelerator (Amazon DMA) helps customers accelerate their migrations to AWS Databases and Analytics (DB&A) services. We achieve this by offering complementary migration advisory services to create migration strategy and plans, develop migration solutions, unblock ongoing stalled/delayed migrations, and share feedback on migration tooling and service improvements to DB&A service teams to simplify migration experience through automation. We serve as a routing function to hand off the migration solution to the customer’s migration implementation choice (ProServe/APN Partner or customer’s in-house migration team) for execution and will continue to stay engaged with the customer and ProServe/APN Partners (if involved) until the workload goes live on AWS DB&A services to ensure a successful migration.
Our team recently ran a Proof of Concept (PoC) to migrate a customer’s Oracle database to DynamoDB. They had a clipboard framework of files from multiple applications requiring temporary storage. The framework had an Oracle RDBMS database set up as a metadata store, with tables keeping all file details and access-related information. These core tables had insert, update, and delete triggers to populate history tables for all tasks. Over time, a large number of internal applications started using these history tables and single database, with raising requirements for high availability and increased operational overhead.
Prior to migration, the application’s database included four tables with core data and four related history tables. The core tables had eight triggers to populate their related history tables: four for before and four for after the changes. The total database size was over 20 GB. The core metadata tables had 15,000 to 20,000 rows at any given time, occupying a maximum of 400 MB, and the history tables took the remaining 17 GB.
While considering this framework’s migration to AWS, we identified the following key areas of optimization:
- Simplify the current architecture and database design
- Migrate the database to a highly available, lower-cost target from a commercial provision
- Ensure minimal efforts for migration and future scalability with maintenance
- Create a seamless data migration and transition plan
- Enable optimized auditing, logging, and change tracking features
Upon reviewing those topics, it was clear that the customer needed a better solution for their history tables requirements and DynamoDB was chosen as the most suitable target for migration and modernization, as it meets the high availability and high throughput requirements. With DynamoDB, there are no servers to provision, patch, or manage, and no software to install, maintain, or operate. DynamoDB automatically scales tables to adjust for capacity and maintains performance with zero administration and zero-downtime maintenances. Availability and fault tolerance are built in, eliminating the need to architect your applications for these capabilities. DynamoDB offers built-in security, encrypts all data by default, and also integrates with AWS Identity and Access Management (IAM) to manage access permissions and implement fine-grained identity and access controls.
An important built-in feature that we’ll talk about in the next session, DynamoDB Streams removes the need for triggers and history tables, simplifying the database significantly.
Benefits of DynamoDB Streams for metadata tables
DynamoDB Streams captures a time-ordered sequence of item-level modifications in any table and stores this information in a log for up to 24 hours. Applications can access this log and view the data items as they appear before and after they were modified, in near-real time. Metadata tables may contain information about other data like files, photos, and objects in a repository. In this scenario, the metadata tables included information on files stored for temporary purposes by various applications. It also supports streaming of item-level change data capture records in near-real time. You can build applications that consume these streams and take action based on the contents, without having to write any code. You can configure DynamoDB Streams to capture change details at various depths:
- KEYS_ONLY – Only the key attributes of the modified item
- NEW_IMAGE – The entire item, as it appears after it was modified
- OLD_IMAGE – The entire item, as it appears before it was modified
- NEW_AND_OLD_IMAGES – Both the new and the old images of the item
For more information, refer to DynamoDB Streams Use Cases and Design Patterns
Using DynamoDB Streams for metadata tables would include core requirements of:
- Logging – Recording all changes made
- Auditing – Tracking all changes made to the data over time
DynamoDB Streams records are accessible via their own APIs. For longer-term storage, you can upload records to Amazon Simple Storage Service (Amazon S3) or Amazon CloudWatch Logs using Amazon Kinesis Data Firehose. Each DynamoDB stream has its own Amazon Resource Name (ARN). Use of separate security permissions and segregating database access from stream access makes the overall design a highly secured architecture. Traditionally, users getting database access could tamper the metadata as well as their history tables to wipe their trace. With the new architecture, such tampering isn’t possible, with separate permissions for the segregated data and stream records.
Migration and modernization
Because this was a major transformation on the database and workflow, but keeping all aspects seamless to the applications, we set up a parallel run system with the old application stack undisturbed and older files and metadata maintained on the RDBMS.
All AWS services and data were configured within a secured Amazon Virtual Private Cloud (Amazon VPC) and followed AWS best practices, with all infrastructure security measures considered. We advise using non-production sample data for all tests, configured in a secured non-production environment, just like how we configured our services. For further information, refer to Best Practices for Security, Identity, & Compliance.
Architecture overview
The following diagram illustrates the original architecture.
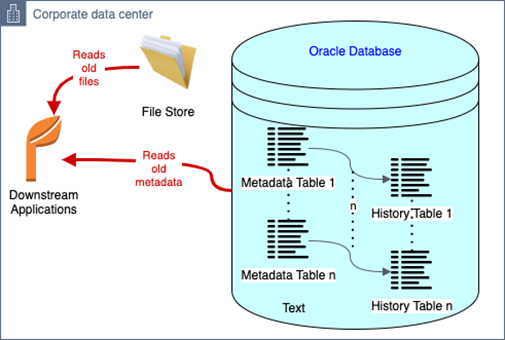
Downstream applications interacted with the framework endpoint, which writes all metadata to the on-premises Oracle database and manages files in file stores.
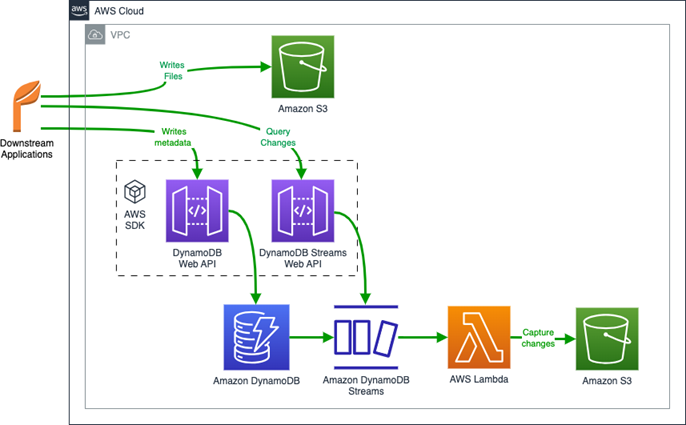
The following diagram illustrates the transitional architecture.

Following the AWS best practices and with all infrastructure security measures considered, an Application Load Balancer (ALB) was deployed in front of the old database to handle and divert queries on a logical basis.
All applications made their database queries via the ALB irrespective of the underlying database being used. All inserts were pointed to the new DynamoDB tables, with the old Oracle tables serving as provisional for updates and deletes of old data. The parallel system ran until all the data from the Oracle core tables was cleaned, after which the old system was decommissioned. This migration didn’t require any changes to the 40 downstream applications because the ALB logically diverted the traffic depending on the operation requested by the downstream applications.
The following diagram illustrates the final, new architecture.
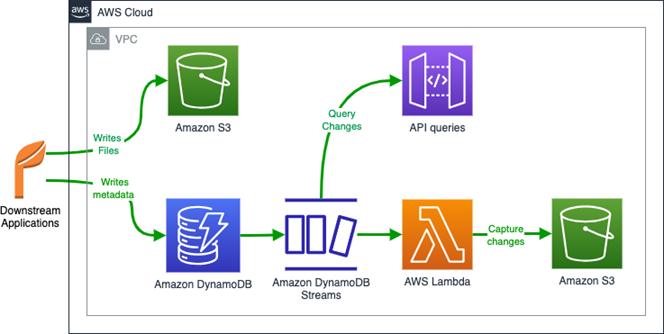
We activated DynamoDB Streams on each of the new core metadata tables with individual ARNs. Every stream is uniquely identified by an ARN for API queries or unique identification.
We added an AWS Lambda function to move all new DynamoDB Streams entries to individual files in an Amazon S3 bucket. The bucket has its dedicated security setup, separate from the DynamoDB database, which provides good segregation of roles. We ran a few sample metadata changes to ensure the audit files were created successfully.
For a complete tutorial with sample code, refer to Tutorial: Process New Items with DynamoDB Streams and Lambda.
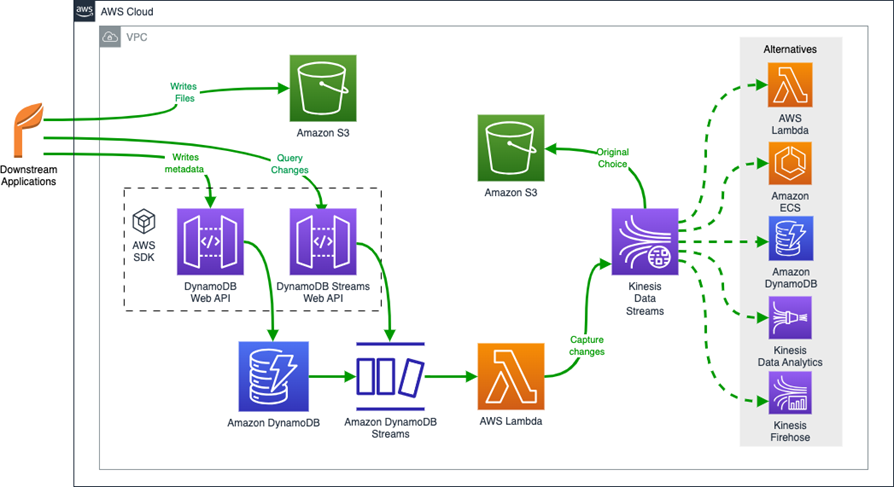
Alternative methods to store DynamoDB Streams data
In this section, we discuss alternative methods to store DynamoDB Streams data and their respective architectures.
One option is to access DynamoDB Streams directly via dedicated APIs.
Another option is near-real-time notifications or messaging using Amazon Simple Notification Service (Amazon SNS). For more information, refer to DynamoDB Streams Use Cases and Design Patterns.

You can also store DynamoDB Streams data to other storage services using Amazon Kinesis Data Streams. For more information, refer to How to perform ordered data replication between applications by using Amazon DynamoDB Streams.
Further enhancements
Because the file store of this application is on Amazon S3, you can take advantage of DynamoDB Time to Live (TTL) feature and remove the overhead of deleting files by the framework. DynamoDB TTL enables you to automatically delete expired items from your tables, at no additional cost. For more information, refer to Expiring items by using DynamoDB Time to Live (TTL).
Conclusion
In this post, we shared a modernization use case where a financial institution (insurance) company migrated from using a RDBMS to store metadata and implemented a solution using Amazon DynamoDB.
For this use case, using DynamoDB Streams led to removing over 66% of secondary objects, reducing the database to 20% of its original size therefore helping the customer reduce 30% of cost. Another benefit was to free up operation resources time by reducing overheads of managing history tables, leading to lower management costs.
A NoSQL database like DynamoDB can free you from the restrictions of an RDBMS database and let you add additional columns to only a small set of data, where required. All remaining datasets as well as its structures don’t need to be changed or tested. This can reduce your application coding and testing efforts drastically.
AWS provides the broadest selection of purpose-built databases, allowing you to save, grow and innovate faster. For more information, refer to Build Modern Applications with Free Databases on AWS. To get started with DynamoDB, please see the DynamoDB Developer Guide
About the Authors
 Paurav Chudasama is a Business Development specialist for Amazon DMA, covering EMEA. He is a key influencer of best practices, tools and methodologies for accelerating database migration and modernization of workloads to AWS. In the past, Paurav built AWS professional service (ProServe) packaged offerings, tools and documents giving technical guidance to consultants, AWS partners and customers for migrating on-premises databases to AWS and modernizing commercial databases to open source at scale.
Paurav Chudasama is a Business Development specialist for Amazon DMA, covering EMEA. He is a key influencer of best practices, tools and methodologies for accelerating database migration and modernization of workloads to AWS. In the past, Paurav built AWS professional service (ProServe) packaged offerings, tools and documents giving technical guidance to consultants, AWS partners and customers for migrating on-premises databases to AWS and modernizing commercial databases to open source at scale.
 Ivan Cardoso is a solutions architect and a subject matter expert on database migrations for Amazon DMA, covering EMEA. Ivan has experience in commercial, open-source and purpose-built database migration, working with customer and partners to move workloads from both transactional and analytics environments to AWS.
Ivan Cardoso is a solutions architect and a subject matter expert on database migrations for Amazon DMA, covering EMEA. Ivan has experience in commercial, open-source and purpose-built database migration, working with customer and partners to move workloads from both transactional and analytics environments to AWS.
 Pratik Chunawala is a Principal Cloud Infrastructure Architect within Migrations and Modernization Global Specialty Practice at AWS Professional Services. Pratik leads the Cloud Migration Factory Solution in the Americas and works with global customers to streamline planning and performing migrations at scale. Outside of work, Pratik delivers guest lectures at Carnegie Mellon University, serves as male ally at NYU’s Alumnae council for women in STEM talking to students about cloud security, secure migrations, and industry use cases.
Pratik Chunawala is a Principal Cloud Infrastructure Architect within Migrations and Modernization Global Specialty Practice at AWS Professional Services. Pratik leads the Cloud Migration Factory Solution in the Americas and works with global customers to streamline planning and performing migrations at scale. Outside of work, Pratik delivers guest lectures at Carnegie Mellon University, serves as male ally at NYU’s Alumnae council for women in STEM talking to students about cloud security, secure migrations, and industry use cases.