AWS Database Blog
DynamoDB streams use cases and design patterns
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Updated May 2021.
This post describes some common use cases you might encounter, along with their design options and solutions, when migrating data from relational data stores to Amazon DynamoDB.
We will consider how to manage the following scenarios:
- How do you set up a relationship across multiple tables in which, based on the value of an item from one table, you update the item in a second table?
- How do you trigger an event based on a particular item change?
- How do you audit or archive data?
- How do you replicate data across multiple tables (similar to that of materialized views/streams/replication in relational data stores)?
You can use DynamoDB Streams to address all these use cases. DynamoDB Streams is a powerful service that you can combine with other AWS services to solve many similar issues. When you enable DynamoDB Streams, it captures a time-ordered sequence of item-level modifications in a DynamoDB table and durably stores the information for up to 24 hours. Applications can access a series of stream records, which contain an item change, from a DynamoDB stream in near real time.
AWS maintains separate endpoints for DynamoDB and DynamoDB Streams. To work with database tables and indexes, your application must access a DynamoDB endpoint. To read and process DynamoDB Streams records, your application must access a DynamoDB Streams endpoint in the same Region.
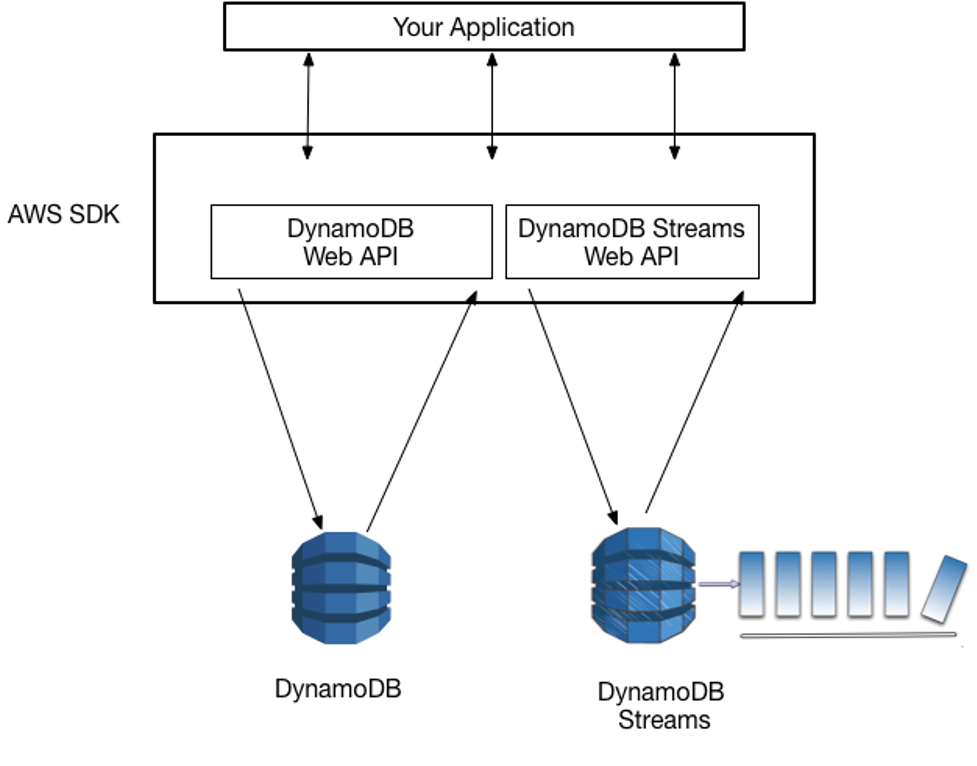
Figure 1: Accessing DynamoDB and DynamoDB Streams
DynamoDB Streams supports the following stream record views:
KEYS_ONLY—Only the key attributes of the modified itemNEW_IMAGE—The entire item as it appears after it was modifiedOLD_IMAGE—The entire item as it appears before it was modifiedNEW_AND_OLD_IMAGES—Both the new and the old images of the item
You can process DynamoDB streams in multiple ways. The most common approaches use AWS Lambda or a standalone application that uses the Kinesis Client Library (KCL) with the DynamoDB Streams Kinesis Adapter. The KCL is a client-side library that provides an interface to process DynamoDB stream changes. It is modified by the DynamoDB Streams Kinesis Adapter to understand the unique record views returned by the DynamoDB Streams service. Lambda runs your code based on a DynamoDB Streams event (insert/update/delete an item). In this approach, Lambda polls the DynamoDB stream and, when it detects a new record, invokes your Lambda function and passes in one or more events.
DynamoDB Streams design patterns
The following figure shows a reference architecture for different use cases using DynamoDB Streams and other AWS services.

Let’s consider a sample use case of storing and retrieving invoice transactions from a DynamoDB table named InvoiceTransactions. A single invoice can contain thousands of transactions per client. InvoiceNumber is the partition key, and TransactionIdentifier is the sort key to support uniqueness as well as provide query capabilities using InvoiceNumber. The following table shows the schema design.
Table Name: InvoiceTransactions
| Partition Key | Sort Key | Attribute1 | Attribute2 | Attribute3 | Attribute4 |
| InvoiceNumber | TransactionIdentifier | Amount | Trans_country | Invoice_dt | InvoiceDoc |
| 1212121 | Client1_trans1xxxx | $100 | USA | 06062016 | {JSON Doc1} |
| 1212121 | Client1_trans2xxxx | $500 | USA | 06062016 | {JSON Doc2} |
| 1212122 | Client2_trans1xxx | $200 | UK | 06062016 | {JSON Doc3} |
| 1212121 | Client2_trans1xxxx | $500 | China | 06062016 | {JSON Doc4} |
Now, assume that you insert the following new item.
| 1212123 | Client3_trans1xxx | $1000 | USA |
After the item is inserted, the DynamoDB stream has the following entry.
| View Type | Values |
| New image | TransactionIdentifier= Client3_trans1xxx,InvoiceNumber=1212123,Amount-$1000,Trans_country=USA |
| Keys only | InvoiceNumber=1212123, TransactionIdentifier= Client3_trans1xxx |
Now, let’s assume that, due to the nature of this use case, the application requires auditing, searching, archiving, notifications, and aggregation capabilities whenever a change happens in the InvoiceTransactions table. Let’s examine how you can process the stream data to address different types of use cases.
Implementing transactional capabilities with multiple tables
DynamoDB supports transactions to implement business logic that requires multiple, all-or-nothing operations across multiple items both within and across tables. You can leverage DynamoDB server-side transaction APIs to address those use cases with a strong consistency model.
However, if you need to use DynamoDB as a materialized view of data stored from one or more tables for quick lookup or validation, you can use stream data to perform such actions. These materialized view tables typically have different access patterns and operational characteristics. Keep in mind that you can apply changes only in an eventually consistent manner. The following are a few examples:
- Aggregation: Consider a scenario in which you need to maintain the total invoice amount in dollars for the given invoice for reporting purposes. This should be dynamically updated when new items are inserted into the
InvoiceTransactionsor other related tables and kept up to date. To capture the total, create a new table with the following layout.
Table Name: InvoiceTotal
| Partition Key | Number Attribute | String Attribute |
| InvoiceNumber | Total | Update_date |
| 1212121 | $1100 | 06062016 |
| 1212122 | $200 | 06072016 |
Whenever there is a change in the InvoiceTransactions table, you update the total. Let’s try to do that using an update expression like the following.
The :Amount value can be read from the DynamoDB update stream whenever a new item is added to the InvoiceTransactions table, and :date can be the current date. The ADD token is the command token. For a numeric attribute, it adds the specified value to the attribute. SET is another command token. It means that all the attributes that follow will have their values set.
Conditional aggregation: Consider a scenario in which you need to record the number of transactions per location for those invoices where an owner is assigned for verification. In this case, you create a new table named InvoiceAction with the following layout.
Table Name: InvoiceAction
|
InvoiceNumber (Partition Key) |
Trans_country (Sort Key) |
Verify_action | Total_trans |
| 1212121 | USA | admin@com | 2 |
| 1212121 | UK | admin@co.uk | 1 |
| 1212121 | China |
Whenever there is a new transaction in the InvoiceTransactions table, you update the total using an update expression with a conditional write operation like the following.
This operation fails with ConditionalCheckFailedException for those countries where there is no owner assigned—for example, China in this scenario.
- Replication: In relational databases such as Oracle, there is a concept of materialized views that is typically used to replicate data from a master table to child tables for query purposes (query offload/data replication). Likewise, using DynamoDB Streams, you can replicate the
InvoiceTransactionstable to different Regions for low-latency reporting and disaster recovery. You can use DynamoDB global tables to replicate the data to other AWS Regions. Global tables use DynamoDB Streams to propagate changes between replicas in different AWS Regions.
Archiving/auditing
Use case: Suppose that there is a business requirement to store all the invoice transactions for up to seven years for compliance or audit requirements. Also, the users should be able to run ad hoc queries on this data.
Solution: DynamoDB is ideal for storing real-time (hot) data that is frequently accessed. After a while, depending on the use case, the data isn’t hot any more, and it’s typically archived in storage systems such as Amazon S3. You can design a solution by using Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, and Amazon S3. Kinesis Data Firehose is a managed service that you can use to load the stream data into Amazon S3, Amazon Redshift, or Amazon Elasticsearch Service through simple API calls. It also can batch, compress, transform and encrypt the data before loading it, which minimizes the amount of storage used at the destination and increases security.
The following describes the high-level solution.
- Create a new data stream in Kinesis Data Streams (for example, ddbarchive).
- Enable streaming to Kinesis on a DynamoDB table by using the console or API. Whenever items are created, updated, or deleted in the
InvoiceTransactionstable, DynamoDB sends a data record to Kinesis. - Create a Kinesis Data Firehose delivery stream to process the records from ddbarchive and store records in a destination such as Amazon S3, for storing the stream data from DynamoDB. By default, Kinesis Data Firehose adds a UTC time prefix in the format
YYYY/MM/DD/HHbefore putting objects to Amazon S3. You can modify this folder structure by adding your top-level folder with a forward slash (for example,Invoice/YYYY/MM/DD/HHto store the invoice transactions). - Kinesis Data Firehose batches the data and stores it in Amazon S3 based on either buffer size (1-128 MB) or buffer interval (60-900 seconds). The criterion that is met first triggers the data delivery to Amazon S3.
- Implement S3 lifecycle policies to move the older data to S3-IA (for infrequent access) or Amazon Glacier to further reduce the cost.
- You also can use DynamoDB Time to Live (TTL), which simplifies archiving by automatically deleting items based on the timestamp attribute. For example, you can designate
Invoice_dtas a TTL attribute by storing the value in epoch format. For an implementation example, see Automatically Archive Items to S3 Using DynamoDB TTL with AWS Lambda and Amazon Kinesis Firehose. - As an alternate option, you also can use the native feature of DynamoDB to export to S3 without writing any code. After your data is stored in your S3 bucket, you can use Amazon Athena for ad hoc querying of the data for audit and compliance purposes.
Reporting
Use case: How can you run real-time fast lookup against DynamoDB?
Solution: Design the DynamoDB table schema based on the reporting requirements and access patterns. For example, if you need to do real-time reporting of invoice transactions, you can access invoice or transaction data from a DynamoDB table directly by using the Query or GetItem API calls. Design your schema with an appropriate partition key (or partition and sort key) for query purposes. Additionally, you can create local secondary indexes and global secondary indexes to support queries using different attributes against the table.
Example: The following queries are candidates for real-time dashboards. In this example, the table invoiceTotal contains the attributes total, update_date, etc., and is partitioned on invoice_number. The invoiceTransactions table contains InvoiceNumber and TransactionIdentifier. It is partitioned on both the attributes, using InvoiceNumber as the partition key and Transaction_Identifier as the sort key (composite primary key). For your real-time reports, you have the following requirements:
- Report all the transactions for a given
InvoiceNumber.
Solution: Invoke theQueryAPI usingInvoiceNumberas the partition key with no sort key condition specified. - Report all transactions for a given
InvoiceNumberwhereTransactionIdentifierbegins withclient1_.xxx.
Solution: Invoke theQueryAPI usingInvoiceNumberas the partition key and a key condition expression withTransactionIdentifier. - Report the total by
InvoiceNumber.
Solution: Invoke theGetItemAPI withInvoiceNumberas the key.
Use case: How do you run analytical queries against data that is stored in DynamoDB?
Solution: For low frequency use cases, you can use Amazon Athena Federated Query or Amazon EMR with HiveQL to query directly against DynamoDB. DynamoDB is optimized for online, transactional use, where the majority of data operations are expected to be fully indexed (and materialized—to avoid variability in performance). For frequent analytical use, it’s generally better to export DynamoDB data (periodically or by ongoing stream-based propagation) into a data store such as Amazon Redshift, which is optimized by storage format to efficiently serve aggregations across large data sets.
The following summarizes this solution:
- Amazon Redshift is a managed data warehouse solution that provides out-of-the-box support for running complex analytical queries.
- Enable streaming in the DynamoDB table, which enables capturing of events in near-real time in a Kinesis data stream. Create the Firehose delivery stream to consume the records from the data stream by configuring Amazon Redshift as the destination.
- Kinesis Data Firehose uses an intermediate S3 bucket and the
COPYcommand for uploading the data into Amazon Redshift. - Use Amazon QuickSight or standard BI tools to run queries against Amazon Redshift.
- For information about implementing a data pipeline using Kinesis Firehose, Amazon Redshift, and Amazon QuickSight, see Amazon Kinesis – Setting up a Streaming Data Pipeline.
Alternate options
- Use the Amazon Redshift COPY command to read the DynamoDB table and load it into Amazon Redshift. See the DynamoDB documentation for more details.
- Use AWS Data Pipeline to extract the data from DynamoDB and import it into Amazon Redshift.
Example: Queries like the following are best served from Amazon Redshift.
- Get the daily run rate from the
invoiceTransactionstable for the last three years. - Select
max(invoice_amount),sum(total_amount), andcount(invoice_trans)from theInvoice Transactions group_by YYYYHHMMDD.
Notifications/messaging
Use case: Assume a scenario in which you have the InvoiceTransactions table, and if there is a zero value inserted or updated in the invoice amount attribute, the concerned team must be immediately notified to take action.
Solution: Build a solution using DynamoDB Streams, Lambda, and Amazon SNS to handle such scenarios.
The following summarizes the solution:
- Define SNS topic and subscribers (email or SMS).
- Use Lambda to read the DynamoDB stream and check whether the invoice amount is zero. Then, publish a message to the SNS topic. For example: “Take immediate action for Invoice number 1212121 as zero value is reported in the
InvoiceTransactionstable as on YYMMHH24MISS.” - Subscribers receive notifications in near real-time fashion and can take appropriate action.
For more information about this implementation, see the blog post Building NoSQL Database Triggers with Amazon DynamoDB and AWS Lambda.
Use case: Assume a scenario in which if there is a new entry for an invoice, the data must be sent to a downstream payment-processing system.
Solution: You can build a solution using DynamoDB Streams, Lambda, Amazon SNS, and Amazon SQS to handle such scenarios. Let’s assume that the downstream payment system expects an SQS message to trigger a payment workflow.
The following summarizes the solution:
- Define an Amazon SNS topic with Amazon SQS as a subscriber. For details, see the Amazon SNS documentation.
- Use Lambda to read the DynamoDB stream and check whether there is a new invoice transaction, and send an Amazon SNS message.
- The SNS message delivers the message to the SQS queue.
- As soon as the message arrives, the downstream application can poll the SQS queue and trigger a processing action.
Search
Use case: How do you perform free text searches in DynamoDB? For example, assume that the InvoiceTransactions table contains an attribute InvoiceDoc as a Map data type to store the JSON document as described in the following table. How do you filter the particular client transaction or query the data (quantity for printers/desktops, vendor names such as %1%, etc.) within the attribute stored as a document in DynamoDB?
| Partition Key | Sort Key | Attribute4 |
| InvoiceNumber | TransactionIdentifier | InvoiceDoc |
| 1212121 | Client1_trans1xxxx |
Partition Key Sort Key Attribute4 InvoiceNumber TransactionIdentifier InvoiceDoc 1212121 Client1_trans1xxxx { “Vendor Name”: “Vendor1 Inc”, “NumberofItems”: “5”, “ItemsDesc”: [ { “laptops”: { “Quantity”: 2 }, “desktops”: { “Quantity”: 1 }, “printer”: { “Quantity”: 2 } } ] } |
Solution: DynamoDB is not suitable for free text search against large volumes of data. We recommend using Amazon Elasticsearch Service (Amazon ES) to address such requirements.
The following describes the solution:
- In this design, the DynamoDB
InvoiceTransactionstable is used as the primary data store. An Amazon ES cluster is used to serve all types of searches by indexing theInvoiceTransactionstable. - Using DynamoDB streams, any update/delete or new item on the main table is captured and processed using AWS Lambda. Lambda makes appropriate calls to Amazon ES for indexing the data in near real time.
- For more details about this architecture, see Indexing Amazon DynamoDB Content with Amazon Elasticsearch Service Using AWS Lambda or Loading Streaming Data into Amazon ES from Amazon DynamoDB
- Alternatively, you can leverage the streaming functionality to send the changes to Amazon ES via a Firehose delivery stream. Before you load data into Amazon ES, you might need to perform transforms on the data. You can use Lambda functions to perform this task; for more information, see Data Transformation.
Elasticsearch also supports all kinds of free-text queries, including ranking and aggregation of results. Another advantage of this approach is extensibility. Elasticsearch Query can be easily modified to add new filters, and Amazon ES does it out of the box. So, for example, if you add a new attribute in DynamoDB, it’s automatically available for querying in Amazon ES.
Best practices for working with DynamoDB Streams
Keep in mind the following best practices when you are designing solutions that use DynamoDB Streams:
- DynamoDB Streams enables you to build solutions using near real-time synchronization of data. It doesn’t enforce consistency or transactional capability across many tables. This must be handled at the application level. Also, be aware of the latency involved (subsecond) in the processing of stream data as data is propagated into the stream. This helps you define the SLA regarding data availability for your downstream applications and end users.
- All item-level changes will be in the stream, including deletes. Your application should be able to handle deletes, updates, and creations.
- Design your stream-processing layer to handle different types of failures. Make sure that you store the stream data in a dead letter queue such as SQS or S3, for later processing in the event of a failure.
- Failures can occur in the application that reads the events from the stream. You can design the application to minimize the risk and blast radius. To that end, try not to update too many tables with the same code. In addition, you can design your tables so that you update multiple attributes of a single item (instead of five different items, for example). You can also define your processing to be idempotent, which can allow you to retry safely. You should also catch different exceptions in your code and decide if you want to retry or ignore these records and put them in a DLQ for further analysis.
- Be aware of the following constraints while you are designing consumer applications:
- Data retention in streams is 24 hours.
- No more than two processes should be reading from a stream shard at the same time.
- We recommend that you consider Lambda for stream processing whenever possible because it is serverless and therefore easier to manage. First, evaluate if Lambda can be used. If it can’t be, use the Kinesis Client Library (KCL). The following comparison table can help you decide.
| Parameters | AWS Lambda | Kinesis Client Library |
| Deployment | Lambda polls the DynamoDB stream and invokes your function/code as soon as it detects the new record. | You write your custom application using KCL with DynamoDB Streams Kinesis Adapter and host it in an EC2 instance. |
| Manageability | Lambda automatically scales based on the throughput. | You must manage the shards, monitoring, scaling, and checkpointing process in line with KCL best practices. (For details, see this design blog post and this monitoring blog post.) |
| How it works | For every DynamoDB partition, there is a corresponding shard and a Lambda function poll for events in the stream (shard). Based on the batch size you specify, it fetches the records, processes it, and then fetches the next batch. |
|
| Execution time | The Lambda maximum execution duration per request is 900 seconds. | There are no restrictions. |
| Availability | Lambda is a managed service and is fully available. There are no maintenance windows or scheduled downtimes required. | The application must be hosted in an EC2 Auto Scaling group for High Availability. |
| Other considerations | Note the impact of the Lambda payload limit on using Lambda to consume stream messages. Any of the _IMAGE types can exceed it, especially for larger items. Therefore you should specify the batch size accordingly. |
Summary
DynamoDB Streams is a powerful service that you can combine with other AWS services to create practical solutions for migrating from relational data stores to DynamoDB. This post outlined some common use cases and solutions, along with some best practices that you should follow when working with DynamoDB Streams.
If you have questions or suggestions, please comment below.
About the Author
 Gowri Balasubramanian is a senior solutions architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on both relational as well as NoSQL database services, helping them improve the value of their solutions when using AWS.
Gowri Balasubramanian is a senior solutions architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on both relational as well as NoSQL database services, helping them improve the value of their solutions when using AWS.