AWS for Industries
Data and Analytics environments at Merck KGaA, Darmstadt, Germany using AWS Services
Merck KGaA, Darmstadt, Germany, a leading science and technology company, operates across life science, healthcare, and electronics. More than 60,000 employees work to make a positive difference to millions of people’s lives every day by creating more joyful and sustainable ways to live. From providing products and services that accelerate drug development and manufacturing, well as discovering unique ways to treat the most challenging diseases to enabling the intelligence of devices. Scientific exploration and responsible entrepreneurship have been key to the technological and scientific advances of Merck KGaA, Darmstadt, Germany. This is how the company has thrived since its founding in 1668. In the United States and Canada, the business sectors of Merck KGaA, Darmstadt, Germany operate as MilliporeSigma in life science, EMD Serono in healthcare, and EMD Electronics in electronics.
The challenge
In the enterprise landscape, validating use case ideas, provisioning, and verifying environments involved extensive time and manual effort that hinder innovation and slow down time-to-market. Looking back, Merck KGaA, Darmstadt, Germany had multiple teams from their business sectors exploring diverse enterprise-scale data & analytics (D&A) use cases in areas such as chemical experiment design, tissue image analysis, or financial compliance risk mitigation. However, due to a lack of suitable centralized infrastructure and environment services for advanced analytics, D&A silos were forming, and teams were hindered to progress from Proof of Concept to large scale adoption of their use cases. Additionally, business sectors were independently planning to migrate and re-architect many pre-existing solutions such as commercial data warehouses to become cloud native. Although the teams wanted to capitalize on the strategic data, there has always been friction for data practitioners to start experimenting and later materializing their ideas from a concept in a secure and compliant way. Driven by these challenges, the D&A leadership team decided to invest in automating the provisioning of custom D&A , as well as launch additional self-service accelerators in AWS, as a main building block of the future D&A ecosystem.
Solution overview
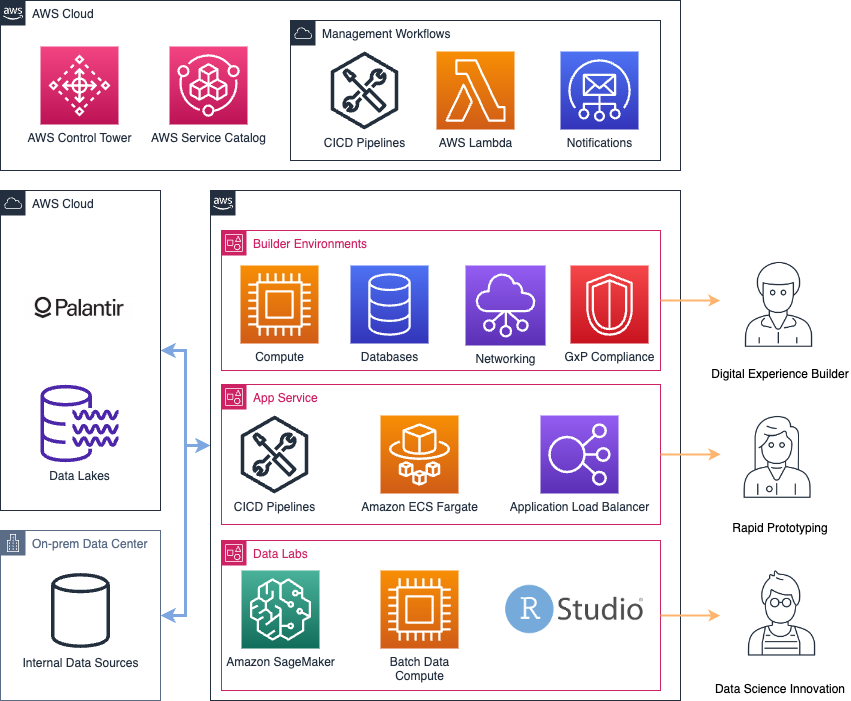
Figure 1: Architecture diagram describing the landing zone for data lakes connecting Data Lake, Palantir Foundry, and on-premises data sources
D&A enables governance and validates business use cases from business teams across the business sectors using Palantir Foundry, a platform to organizes enterprise data. In the portal, teams manage their use cases from Ideation to Industrialization phases. Once a use case idea is assessed and approved, use case teams require the right set of tools to experiment and implement their use case. During 2022, the D&A platform team has built a variety of offerings that cover all developer needs across the different stages of the use case lifecycle. The core offering is the use case specific Builder Environments that are automatically provisioned through Infrastructure-as-Code (IaC) and automated processes based on information in the Foundry use case portal. The Builder Environments offer a flexible end-to-end AWS Account based environment with access to relevant data and tools to host any D&A use case architecture and make it available to end users. In the regulated pharmaceutical environment such as drug development and manufacturing, a set of “good practices” need to be followed to safely use IT systems in these areas (generally known as GxP compliance). GxP-qualified Builder Environments that satisfy these compliance requirements are available as well, even though in a less fully-automated fashion currently. Although the Builder Environments offer the custom baseline for every D&A use case, the D&A platform team has also invested in building two additional self-service accelerator products: the Data Lab and the App Service. During ideation, teams often do not know all the required Infrastructure they might need to run their use case in production. Teams first need easy access to company data across Palantir Foundry and Data Lake on AWS and the right tooling to perform impromptu analysis and data exploration. For this user need, the D&A platform team has built the Data Lab Environment featuring ready-to-use data science workbenches based on pre-configured notebook instances. The second key enabler for use case teams is the App Service, which allows them to easily build and deploy custom frontends for D&A solutions with user-impersonated data access and orchestration through Linux containers, removing the heavy lifting of deployment and scaling.
Builder Environments as a landing zone for data
D&A use cases have distinct requirements when it comes to cloud infrastructure. Manually designing, deploying, and securing customized environments for every use case team across the business sectors is not feasible. Therefore, the central D&A platform team automated the creation of use case specific Builder Environments. A Builder Environment consists of AWS Accounts, networking configurations, security configuration, and compliance, as well as configuration management and necessary Continuous Integration and Delivery (CI/CD) pipelines. The central D&A platform team is responsible for providing and securing this baseline infrastructure. Use case teams start by validating their use case idea, reviewing the technical feasibility of the use case, and deciding whether the use case is suited for a Builder Environment in AWS. After validation, teams fill a Builder Environment request form in Palantir Foundry. In the form, the teams are asked to provide a unique use case identifier, environment owner, data access patterns to various data sources, and estimated monthly budgets. The information provided in the form is the basis for the automatic provisioning of a Builder Environment consisting of up to three AWS accounts (DEV + QA + PROD).
Once reviewed and submitted, the form automatically lands as a JSON file in an Amazon Simple Storage Service (Amazon S3) bucket for further processing. Amazon S3 acts a durable and cost-effective repository for requests. Amazon S3 also triggers events for objects to enable simple event-driven processing of requests through serverless services integration in a cost-effective manner for these types of infrequent requests. AWS Lambda, a serverless event-driven compute service, is triggered through the arrival of the JSON object to parse, validate, and trigger the creation of the AWS accounts.
AWS Control Tower is a single service to govern and secure well-architected multi-account environments. AWS Control Tower Account Factory simplifies and automates the process to create AWS accounts. The service also enables compliance teams to orchestrate security and compliance rules in those accounts.
The state of the account creation process is tracked in an Amazon DynamoDB table. DynamoDB acts as a cost-effective, reliable and easy to use and configure key value store.
Once AWS account creation is successful, an event is sent to trigger a multi-stage pipeline that further customizes the new Builder Environment Accounts. Pipeline stages use the AWS Cloud Development Kit (AWS CDK), an open-source software development framework used to model and provision your cloud application resources programmatically, and to create resources needed for building services and accessing data. These resources include networking and routing as well as security and compliance configurations and account budgets. The pipeline also creates a CI/CD and code repository project, from which use case teams can deploy new infrastructure to their accounts using IaC.
Once the entire infrastructure was successfully created, use case teams are notified automatically with an email using Amazon Simple Email Service (Amazon SES), a cost-effective cloud email service. Once use case teams from the sectors receive their customized Builder Environment, they can provision any use case specific cloud infrastructure, such as databases or serverless compute clusters. Use case teams get access to their Builder Environment using predefined SSO permission roles, such as admin, developer, and tester. Use case teams can suggest modifications to permission sets of their use case specific roles through pull-request to a repository governed by the central D&A platform team.
Global Service Control Policies enforced by Service control policies (SCPs), a part of AWS Organizations service to manage permissions in an organization, make sure only allowed services are used and that certain actions cannot be performed. Actions that are invalid include modifications of baseline resources, such as intranet network connectivity. The Builder Environments are embedded into the wider ecosystem of D&A tooling. For example, central ingestion accounts for each business sector can be used to ingest data from on-premises data sources into a central Amazon S3-based Data Hub. Then, this data can be consumed from Builder Environments. In some use cases, data is ingested directly into the Builder Environment Accounts, for example if data already exists on Palantir Foundry or the data is highly custom and cannot be offered as a data product in the central Data Hub. Given the high demand from business sectors for scalable and secure environments, the automation of Builder Environments has reduced the time for AWS Environment provisioning from months to days. This not only increased the bandwidth of the central D&A platform team for new innovations, but also lead to high customer satisfaction, as shown in the following figure.

Figure 2: Architecture overview of governance and workflow management for environments
D&A Lab Environment for experimentation and exploration
To accelerate experimentation and enterprise data exploration, the D&A Lab Environment provides data practitioners with scalable and flexible workbenches for data science and data engineering workflows. The focus is on workflows such as impromptu analyses, data exploration & preparation, as well as training and testing machine learning (ML) models. The D&A Lab Environments provide an easy-to-use self-service entry point for developing remotely on AWS Cloud infrastructure using state-of-the-art tooling. Technical data practitioners can get direct access to powerful infrastructure without lengthy approval processes, as these environments are already provisioned and are offered in a multi-tenant “as-a-service” model. Each of our three business sectors has its own Lab Environment AWS account in which users can launch and manage different AWS products as workbenches using AWS Service Catalog. Service Catalog creates and manages IaC product portfolios pre-approved and curated according to the organization’s best practices. Workbenches that users can launch consist of pre-configured Amazon Elastic Compute Cloud (Amazon EC2) instances, a secure and resizable compute capacity in the cloud. Notebooks focused workbenches use fully managed Amazon SageMaker notebooks, a fully managed Jupyter Notebooks for data science and ML, and managed R-Studio instances, an integrated development environment for R.
For each workbench, users can choose from a wide variety of different CPU and GPU instance types, as well as pre-configured images with custom Conda Python environments containing key libraries (e.g., pandas, pyspark, foundry-dev-tools) to work effectively within the data ecosystem of Merck KGaA, Darmstadt, Germany. Users can leverage the remote development features of popular IDEs, such as VSCode or PyCharm to customize a flexible developer experience.
What makes the Lab Environments so valuable is easy access to enterprise data across Data Hubs in AWS and Palantir Foundry. AWS PrivateLink allows users to connect privately to services in other environments as if they were in the same AWS networking environment. These connections are managed by PrivateLink for high availability and scalability. With PrivateLink Data Lab users can directly read and write data to Palantir Foundry. From their provisioned workbench (e.g., a SageMaker notebook), users can automatically authenticate with Palantir Foundry using SSO and inherit their data access permissions. Finally, workbenches can access the internet allowing users to connect to git repositories and use version control as well as access other allow-listed endpoints, as shown in the following figure.

Figure 3: Architecture diagram for governance, environments, and data access
Automated frontend hosting for D&A solutions
Open-source frameworks such as Streamlit or R-Shiny are often used by data practitioners to validate ideas, test hypotheses, or build simple applications. Making these apps available to end-users in a secure and compliant manner as well as keeping the apps connected to the data supply chain is a challenge. To minimize the administrative and operational burden and the technical skills required of hosting such user facing applications, the central D&A platform team has built the App Service. The App Service is a convenient and easy to use hosting service for container-based (web) applications. The use case is to empower teams to take their service ideas from ideation phase to production with minimum friction and scale when needed. In a nutshell, the App Service hosts each application in a container running on Amazon Elastic Container Service (Amazon ECS) powered by AWS Fargate. This is also offered as a multi-tenant Software-as-a-Service (SaaS) offering to the organization to reduce complexity and management overhead.
Amazon ECS is a fully managed container orchestration service that makes it easy for you to deploy, manage, and scale containerized applications. And by using Fargate, a serverless compute engine for Amazon ECS, the team does not have to manage any clusters. AWS Application Load Balancer (ALB) is used to securely route traffic to the apps and authenticate the end-users to deployed applications based on custom routing rules. The App Service also manages the creation of a source code repository and a CI/CD pipeline for building and updating the application automatically.
To use the App Service, D&A teams simply head to the App Service UI and with a few clicks they can configure a fully working prototype application that can be found minutes later under a custom URL – all in self-service mode. Based on user input, the App Service automatically registers and creates each container within Amazon ECS/Fargate and pushes the code of the prototype frontend to a git-based repository service. The App Service features sample apps for an ever-growing list of popular open-source application frameworks that currently includes Streamlit, Plotly Dash, R-Shiny, and FastAPI with a React frontend making it easy for users to get started.
The App Service is integrated with the Builder Environment offering as well as Palantir Foundry. App Service users can select their Builder Environment AWS Account from a dropdown menu to automatically establish a connection between their containerized application running in the App Service AWS Account and their Builder Environment AWS resources. This allows applications in the App Service to fully utilize any additional AWS resources and services needed that are running in Builder Environments.
Once connected, containerized applications running in the App Service can for example, use AWS Lambda Functions to manage data transformation jobs, use an S3 bucket as storage backend, or use a DynamoDB table as a persistence layer. The App Service – Builder Environment connection is established through VPC endpoints, a scalable and highly available service that allows communication between applications in an account and AWS services for selected AWS services. Amazon ECS tasks hosting containers in the App Service assume temporary credentials to perform allow-listed actions on Builder Environment AWS resources through API requests. The running containerized applications also have network connectivity as well as an OAuth2 integration to Palantir Foundry, allowing App Service containers to request for data or writeback data to Foundry on behalf of the end-user. This allows apps to seamlessly integrate with the data supply chain of Merck KGaA, Darmstadt, Germany avoiding data duplication, data silos, or outdated data.
Next steps
The post shows how to build customized analytical environments, a key component of a distributed data and analytics environment is a data governance solution. Currently consumption experiences catalog data products technically using AWS Glue Data Catalog, a serverless reliable store for metadata. Consumption experiences define how to consume the data product as services or datasets. For a next step the D&A platform provides a business data catalog and incorporates granular access controls over data products to setup an internal data marketplace experience.
The D&A platform team is adopting additional services that provide value for the consumption experiences. The philosophy is to find more ways to work backward and build innovative experiences that propels the flywheel to increase platform adoption through removing heavy lifting from experiences team and thus offering more experiences.
Conclusion
In this post, we showed how Merck KGaA, Darmstadt, Germany is building a connected D&A platform leveraging many AWS services and Palantir Foundry. D&A teams within the business sectors profit from the different offerings, such as the Builder Environments, the Data Lab, and the App Service by accelerating the time-to-market of D&A use cases. Since launching the platform offering in Spring 2022, 50+ Factory Environments were provisioned, more than 200 data practitioners are using the Data Lab, and 100+ Apps are hosted on the App Service. The platform was built to accelerate data driven decision making at Merck KGaA, Darmstadt, Germany as a part of a continuously evolving data strategy.
A crucial part of the success of the platform is that the D&A platform team is listening to their customers and constantly shipping platform improvements. Building a D&A ecosystem is a journey, and the D&A platform team is now working on the next set of accelerators. For example, future topics are offering a managed cloud data warehousing stack, improving data governance processes across the platform, and upskilling more teams to develop cloud native solutions using IaC, CI/CD, and more.
To get started on how to build compliant environments, you can check out the Landing Zone Accelerators for Healthcare. From there you can check resources on automating GxP on AWS, and more information on deployment pipelines reference architectures. And for more information on creating serverless applications with Amazon ECS and Fargate, check Serverless Land patterns. Finally, for more information on building data lakes on AWS, check out architecture best practices for analytics, and then you can check out how to extract value from your data using Machine Learning for Health Care and Life Sciences.