AWS for Industries
Easy Genomics Solution for Public Health Labs
Having timely and complete access to genomic sequencing data and analytics helps public health agencies respond better to a disease. It allows them to know when a new variant increases in prevalence. When paired with clinical and epidemiologic data, it can answer key questions like: Which variants cause less severe illness? and Who is more likely to become ill from this variant? and Is the vaccine effective against this variant?
Genomic sequencing workloads are computationally intensive and require large volumes of data storage. Furthermore, implementation can be complex, requiring users to interact with command line interfaces to upload sequencing data, select and run pipelines with appropriate runtime parameters. Considerable knowledge of bioinformatics and IT is required to select the correct pipelines and run them appropriately.
To accelerate genomic sequencing analysis, customers seek solutions that are simple to use, scalable and require limited technical expertise. We present Easy Genomics that democratizes genomic sequencing analytics by providing a no-code way for non-bioinformaticians to upload laboratory data and run the workflows needed to analyze appropriately. Easy Genomics allows low-resourced labs to scale bioinformatics capacity without needing extra coders or bioinformaticians.
Developed through a collaboration between Amazon Web Services (AWS), Two Bulls (Part of DEPT), and the Wisconsin State Laboratory of Hygiene (WSLH), the Easy Genomics solution leverages Nextflow Tower APIs for an automated solution. AWS worked with WSLH (thought leaders in public health bioinformatics) to conceptualize an architecture, then identified a member of its AWS Partner Network, Two Bulls, to develop Easy Genomics to WSLH’s specifications.
Easy Genomics is designed for organizations that need a low-code or no-code solution for laboratorians or other staff to upload their genomic sequence samples to the cloud for processing. Easy Genomics presents a straightforward landing page for individuals to:
- Securely login
- Upload single or multiple samples
- Select the appropriate analytic workflow
- Monitor sample progress
- Receive the results via the browser or email
To make the experience seamless for its users, Easy Genomics includes functionality that allows an Administrator to:
- Add, modify, or delete users
- Add, modify, or delete organizations
- Manage users’ pipeline access
You can quickly deploy Easy Genomics in your AWS environment with the open source AWS CloudFormation template or Terraform template. These templates facilitate developers and businesses to create a collection of related AWS and third-party resources, while provisioning and managing them in an orderly and predictable fashion. You can personalize your web application with your logo and text through the administration tool in Easy Genomics.
Automatically Scaling, Managed Architecture
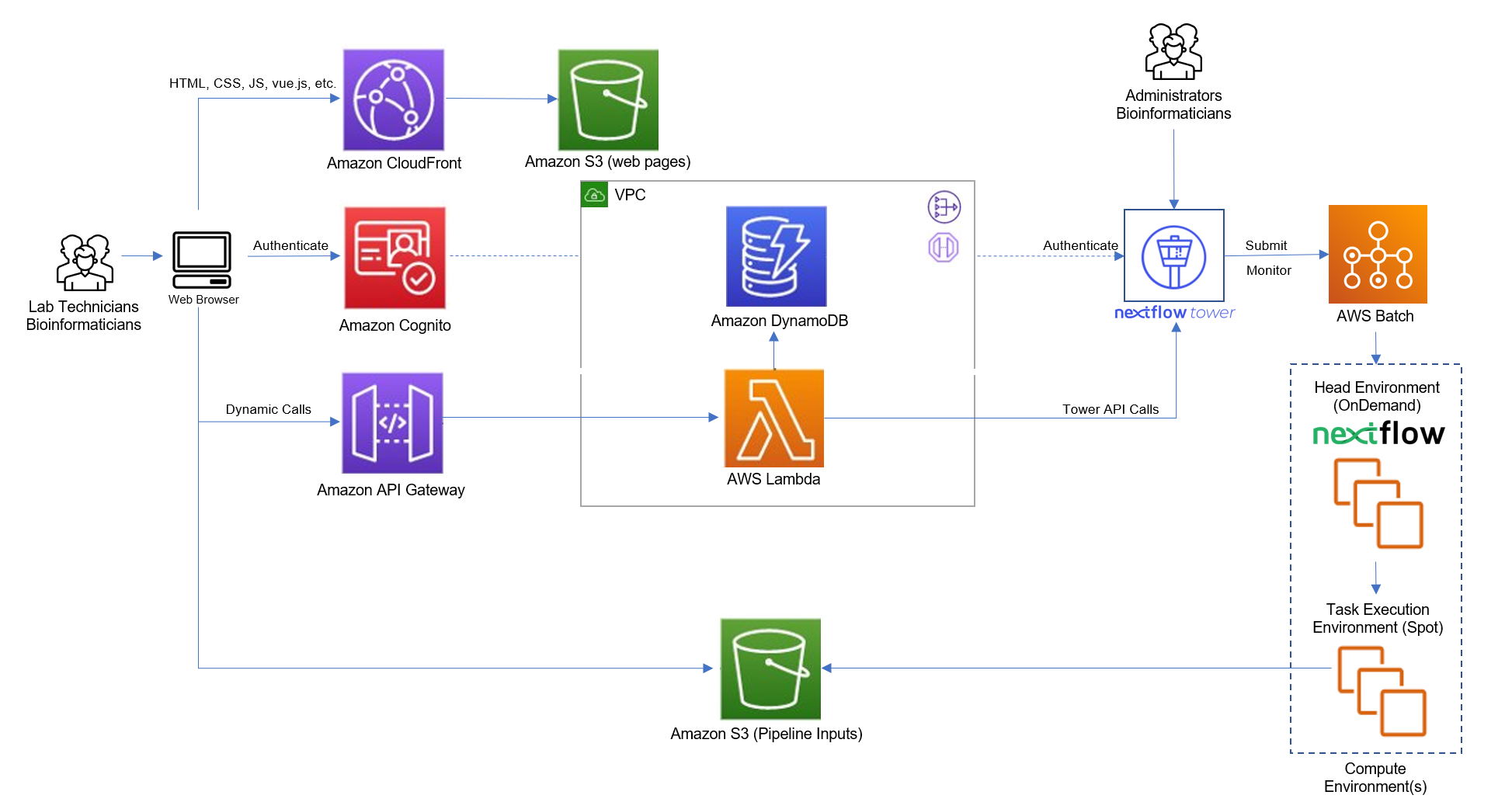
Figure 1 – High-Level Architecture of the Easy Genomics Solution
The reference architecture shown in Figure 1 provides a system overview for Easy Genomics. The guidance provided here is generic and must be adapted to meet specific customer requirements and business outcomes.
Easy Genomics uses AWS serverless services, which provide automatic scaling and built-in high availability. Serverless services used in Easy Genomics include AWS Lambda (Lambda), Amazon API Gateway, Amazon DynamoDB (DynamoDB), Amazon Cognito, Amazon Simple Storage Service (Amazon S3), Amazon CloudFront (CloudFront) and AWS Batch. These serverless services eliminate infrastructure management tasks (like capacity provisioning, patching and a pay-for-use billing model) to increase agility and optimize costs.
Easy Genomics stores static web resources (including HTML, CSS, JavaScript, and image files) in Amazon S3, and serves them to the individual’s browser using CloudFront content delivery network (CDN) service. This creates a secure, cost-effective front-end which can scale as demand and workloads change. Easy Genomics also displays the analytic results in this browser front-end and can send them by email.
The front-end application sends and receives data from a back-end micro-service built using Lambda and API Gateway. The Lambda function uses Nextflow Tower APIs to run the pipelines. Nextflow Tower APIs require an authentication token to be specified in each API request using the Bearer HTTP header. Administrators can generate that token from the Nextflow Tower. Information on how to generate that token is provided in the Nextflow Tower documentation.
Users access Easy Genomics using the web browser, upload the sequencing data, select the workflow and submit for processing. Behind the scenes, Easy Genomics interfaces with Nextflow Tower API’s for processing the workflows and upload the results to an Amazon S3 bucket.
Built with Data Security in Mind
Easy Genomics uses Amazon Cognito for user management and authentication to secure the REST API in API Gateway. User accounts are stored in Amazon Cognito. Site Administrators manage user accounts and delegate access to specific Amazon S3 buckets with permissions to perform various workflow activities (create, update, delete, run workflows) through the web interface.
Easy Genomics stores the metadata about the labs and pipeline runs in DynamoDB. DynamoDB is a fast and flexible non-relational database service. It provides a highly durable storage infrastructure designed for mission-critical and primary data storage. Data is redundantly stored automatically on multiple devices across multiple facilities in a DynamoDB region.
To store lab pipeline input and output artifacts, Easy Genomics allows administrators to apply security best practices (for example, storage in new Amazon S3 buckets, data encryption, and versioning).
Run DynamoDB and Lambda functions in private subnets within a virtual private cloud (VPC). Lambda functions, which are deployed in a private subnet, access the Nextflow Tower Public APIs by using a NAT Gateway. Use VPC endpoints for communication between Lambda and AWS Batch (where workflow jobs will be processed), and Amazon S3.
Recommendations When Using Easy Genomics
- Encrypt data at rest using customer managed keys for least-privileged access controls and AWS Key Management Service (AWS KMS). AWS KMS lets you create, manage, and control cryptographic keys across your applications and AWS services.
- Configure compute environments in Tower to use the AWS Batch integration. Tower Forge automatically provisions Amazon Elastic Compute Cloud (Amazon EC2) in AWS Batch so that organizations only pay for the infrastructure they use.
- Keep costs low by using Amazon EC2 Spot Instances configurable in Nextflow Tower, which can reduce your cost by as much as 90% compared to on-demand compute prices. Nextflow Tower has the ability to automatically relaunch failed tasks, you can benefit from Spot Instances’ lower costs without concern for losing your tasks and the data associated with it.
- Use Amazon S3 Glacier (S3 Glacier) for long-term storage of infrequently used data. S3 Glacier provides long-term, secure, durable storage classes for data archiving at the lowest cost with milliseconds access. Customers can use S3 Glacier to store both raw sequencing datasets and outputs generated by Nextflow pipelines.
Conclusion
The Easy Genomics solution can help public health labs to accelerate their genomics sequencing analytics. It allows laboratories to scale more genomic sequencing capacity without needing to add additional bioinformatics staff. Easy Genomics’ no-code front-end makes it simple to upload samples and trigger the appropriate analytics. As an open source solution, its accessible to everyone.
For more information on Amazon services in healthcare, life sciences, and genomics, please visit aws.amazon.com/health. To know what AWS can do for you contact an AWS Representative.
Source Code Request: Easy Genomics – To deploy the solution in your AWS account, you may request the source code and deployment instructions by sending an email to: sourcecode@easygenomics.org.
Further Reading
- To learn more about Nextflow Tower go to: https://cloud.tower.nf/
- To learn more about the AWS Batch which is used by Nextflow tower to run the jobs go to https://aws.amazon.com/batch/
- To learn more about how AWS can enable your genomics workloads, be sure to check out the AWS Genomics page.