Artificial Intelligence
Amazon Pinpoint campaigns driven by machine learning on Amazon SageMaker
At the heart of many successful businesses is a deep understanding of their customers. In a previous blog post I explained how a customer 360o initiative could be enhanced by using Amazon Redshift Spectrum as part of an AWS data lake strategy.
In this blog post, I want to continue the theme of demonstrating agility, cost efficiency, and how AWS can help you innovate through your customer analytics practice. Many of you are exploring how AI can enhance their customer 360o initiatives. I’ll demonstrate how targeted campaigns can be driven by machine learning (ML) through solutions that leverage Amazon SageMaker and Amazon Pinpoint.
Let’s look at a retail example. As consumers, we have some intuition of purchasing habits. We might tend to re-purchase types of products we have good experiences with, or conversely, we might drift toward alternatives as a result of unsatisfactory experiences. If you buy a book that is part of a trilogy, there is a higher likelihood that you will buy the next book in the series. If you buy a smart phone, there’s a high probability that you might buy accessories in the near future.
What if we had the ability to learn the purchasing behavior of our customers? What could we do if we knew with relatively high probability what their next purchase will be? There are many things we could take action on if we possessed this predictive capability. For instance, we could improve the efficiency of inventory management or improve the performance of marketing campaigns.
In this blog post, I’ll demonstrate how Amazon SageMaker can be used to build, train, and serve a custom long short-term memory recurrent neural network (LSTM RNN) model to predict purchasing behavior, and leverage predictions to deliver campaigns through Amazon Pinpoint. RNNs are a specialized type of neural network, a class of ML algorithms. RNNs are typically used with sequence data. Common applications include natural language processing (NLP) problems such as translating audio to text, language translation, or sentiment analysis. In this case, we’re going to get a little creative and apply the RNN model on customer transaction history from a real online retail data set[i] downloaded from the UCI Machine Learning Repository.
Challenges
Before we dive into the solution, let’s appreciate the challenges involved in taking such a project from concept to production. Consider a canonical ML process:
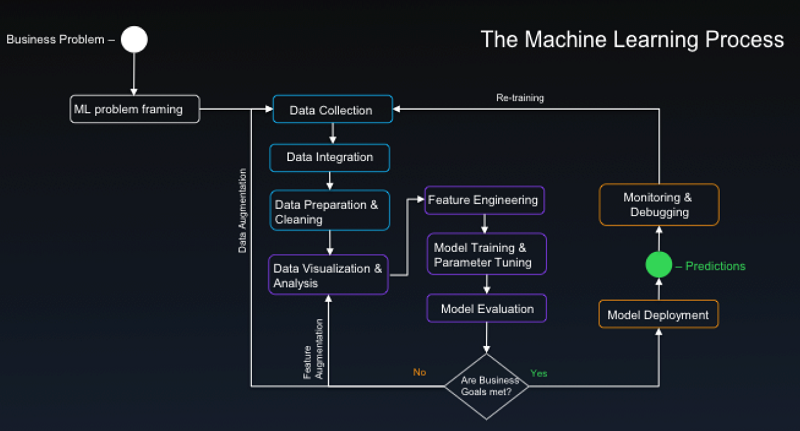
Some key observations:
- The process includes a data pipeline common to data engineering projects, and thus, face big data challenges at scale. The data set presented in this blog is small, but analogous data sets from large retailers like Amazon.com are on the big data scale, and are sourced in batches and streams from a variety of formats. While ample data is good for ML projects because it factors into producing higher model performance, the right platform is necessary to harness data at scale. An AWS data lake strategy can deliver a future-proof solution that minimizes operational complexity and maximizes cost efficiency. The groundwork will continue to pay dividends in your AI initiatives as well as your other data engineering projects.
- There is a need to support diverse activities. Diverse activities translate into a need for a variety of tools that best fits the function and the skillsets of team members. Activities like data processing, discovery, and feature engineering at scale are well suited for tools like Spark. In AWS, Amazon EMR facilitates the management of Spark clusters, and enables capabilities like elastic scaling while minimizing costs through Spot pricing. Frameworks like Keras and Gluon could be favored for prototyping while TensorFlow or MXNet might be better suited as the primary engine for training and model serving in the later stages of development. The right framework depends on the use case and the skillsets on your team. A platform like Amazon SageMaker, which is agnostic to ML frameworks, is ideal. You have the choice of leveraging native Amazon SageMaker algorithms or creating a custom model using your own script or container built on your chosen framework.
- The process is highly iterative. Thus, minimizing the time between iterations is critical for productivity. A big part of each iteration is a process called hyperparameter tuning. The best values for these parameters have to be discovered through experimentation because they are unique for each model, data set, and objective. The process can be challenging because sometimes there are a lot of parameters, and changes to one parameter could have a ripple effect. Each time parameters are adjusted, models are retrained and evaluated, and training time also increases with model complexity and data size. Minimizing turnaround time is often done by leveraging GPU, and using a server cluster to perform distributed training. This could be the difference between waiting for hours instead of days, or minutes instead of hours. Having a platform like Amazon SageMaker that can provide distributed training on GPU as a service, can result in substantial productivity gains and cost efficiency through pay-for-what-you-use economics. Data scientists and machine learning engineers are scarce and expensive resources. Minimizing this process bottleneck is critical to keeping your team lean.
- The picture is incomplete. Of equal importance is what isn’t in the picture. The effectiveness of your analytics practice is measured by the value you deliver back to the business. Delivering a model or an endpoint may not be the ends to your intended business outcomes. Amazon SageMaker automates the deployment of Auto Scaling API endpoints for your ML models. The rest of the AWS platform can take you one step further towards your goal by making your ML models consumable and actionable by end users through integration with a breadth of services. These integrations can be in the form of delivering real-time inference to applications and streams, or bringing predictive analytics to your enterprise data warehouse (EDW) and business intelligence (BI) platform. Later in this blog post, we demonstrate how predictions can be used by Amazon Pinpoint to deliver high performing campaigns.
Predictive campaigns solution
The following image shows the conceptual architecture for the solution I’m going to present. The solution leverages Amazon SageMaker to facilitate the ML process I’ve described. I’ll walk you through the four steps illustrated in the architecture.
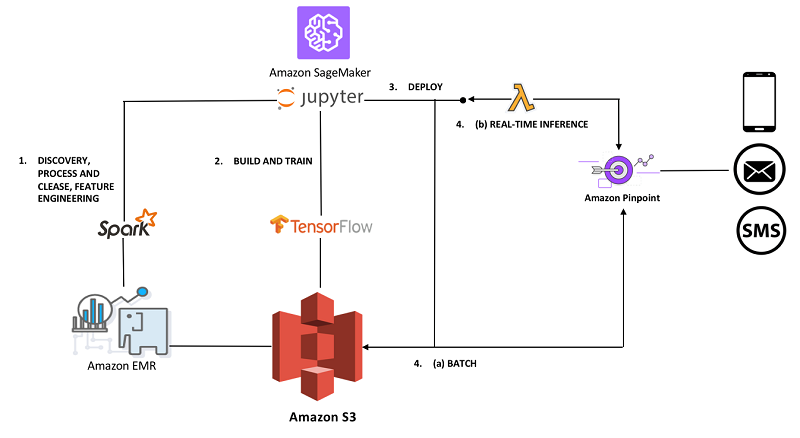
1. DATA ENGINEERING: The data set is stored in an Amazon S3 data lake. The first step to building this solution involves deploying an Amazon SageMaker managed Jupyter notebook.
This first notebook captures the data cleansing, processing, discovery, and feature engineering work that I chose to perform in Spark. Spark is my tool of choice for these activities due to its ability to process large data sets, and the convenience of having SQL support for data discovery among other useful utilities. SageMaker notebook instances can be configured to run against an external Amazon EMR cluster. The ability to scale Spark on Amazon EMR elastically and economically through Spot pricing is valuable in this exploratory phase. Often, it’s not worthwhile to invest time into optimizing pipelines during this phase; instead temporarily scaling-out the cluster is the better strategy to keep your team agile.
2. BUILD AND TRAIN: I chose to build a custom model in TensorFlow, and leverage the distributed training capabilities of Amazon SageMaker. This notebook illustrates the rest of the ML process from preparation of training and validation datasets to the training and deployment of a custom TensorFlow model on Amazon SageMaker.
The following diagram shows the architecture of the LSTM RNN model that is implemented:

Conceptually, an RNN can be modeled to estimate the conditional probability of a sequence of inputs. In this case, the sequence is the order history from a customer base. What we buy in the past influences what we buy in the future. There is predictive power encoded in the history of previous purchases that can enable us predict what is most likely to be bought next. No doubt, there are models that will outperform this approach in certain situations. If you possess customer data with product recommendations and ratings, a predictive model that leverages those features could be more effective in some cases. If you have a lot of data, a model with higher complexity, such as a multi-layer RNN with some bidirectionality, will likely lead to better results. Another way to improve predictive power is to build an ensemble with boosting. I leave it to you to try out these ideas!
This Python script defines the LSTM RNN model described earlier in a way that is compatible with Amazon SageMaker training and model serving. A developer simply implements an interface as described in the documentation. This interface resembles the TensorFlow interface for custom estimators. Performing remote training is as simple as creating a SageMaker TensorFlow object, and calling the fit method. If you want to perform distributed training, you should instantiate the TensorFlow object with a train_instance_count parameter that is greater than one, and instantiate the training operation in your algorithm with a global_step value of tf.train.get_or_create_global_step(). (This is a TensorFlow framework requirement for performing distributed training.)
Those who run my notebooks will observe different results with each run. This is expected as a result of the non-deterministic nature of the ML algorithms, but it is also amplified by the fact that the data set is relatively small and random splitting and shuffling occurs on the dataset each time you retrain the model.
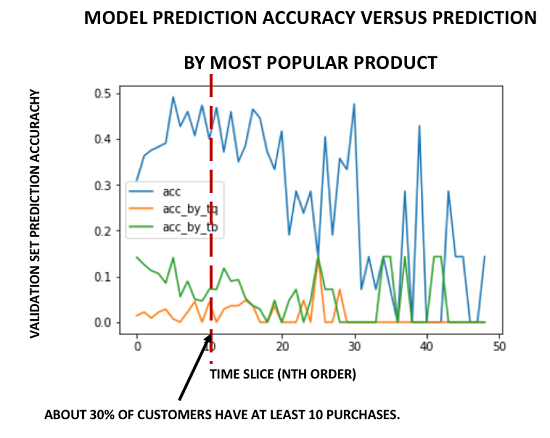
Nonetheless, you should obtain a prediction accuracy of 20-50% for predicting the most likely product out of 3648 that will be purchased next by customers in the validation dataset who have a history of less than 11 previous orders. Although the model was trained on customers who have an order history of 2 to 50 orders, there are relatively few customers who have a history of more than 10 orders. For this reason, due to limitations of the dataset, I chose to use this model for making predictions only with customers with a history of 10 or less orders. The following chart shows the prediction accuracy of one of my trained models (blue). It is compared against the prediction accuracy of a naïve model that predicts the most popular product by most frequently bought (green) and most units sold (orange). Again, due to random shuffling of training and validation sets, you will observe varying results. Nonetheless, expect to see accuracy within the range of 2-15% for these cases.
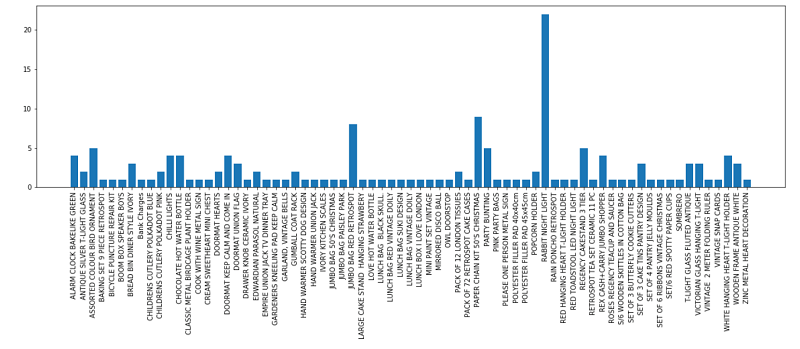
3. DEPLOY: After you have an Amazon SageMaker trained model, to create an Auto Scaling API endpoint for your model you simply call the deploy method. If you deploy one of my pre-trained models, you can use the validation set to predict the next purchase. In my case, I selected customers from the validation set that have made 10 or less orders, and predicted what they will purchase next. You could sample your test data from the entire dataset. However, I chose to avoid using data from the training set because signs of overfitting were observed despite applying regularization techniques. To be clear, the validation set was used to ensure that the model performs and generalizes well by measuring the prediction accuracy of the next known purchases in the order history sequence. Now we use it again for a different purpose to predict the next unknown purchase for customers in this data set. For instance, we will predict the 10th purchase for a customer who has a history of 9 orders. The observed distribution of predictions should be as follows:
4. BATCH and REAL-TIME INFERENCE: Now it’s time to take action. These predictions can be leveraged to help drive various campaign objectives. For instance, we could run a promotion on a selection of the products in the illustration in step 3. We could leverage these predictions to drive high conversion-rate traffic to special events. As conceptualized in the solution architecture diagram at the top of this section, there are multiple ways we can deliver these predictions to Amazon Pinpoint to drive our marketing campaign. If real-time mobile push is the right way to deliver predicted promos, you could design a system to trigger an AWS Lambda function that calls the prediction endpoint when the state of a shopping cart is updated, and potentially do a mobile push to an end user. The process would look like this:
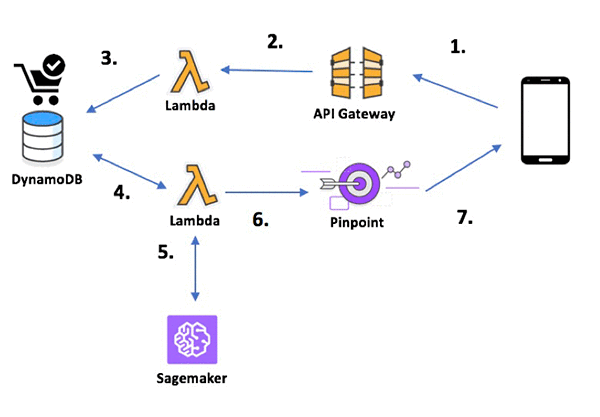
Alternatively, predictions can be processed in batch and cataloged in the data lake from where the marketing team can import into Amazon Pinpoint to launch a campaign. You can use the AWS Management Console to do this. Try it yourself with this sample endpoint file. This endpoint file contains the cohort of customers that our model predicts will buy the “Rabbit Night Light” next. The file contains standard attributes, such as demographics, as well as the channels and addresses that the customers can be reached at. Additionally, custom attributes can be added. In this case, I’ve added a custom attribute for the predicted product ID. This attribute could be utilized within the message body of campaigns to dynamically personalize content. For instance, the predicted product image could be dynamically referenced using this custom attribute.
The first step to importing this data is to create a segment. A segment can be created by importing the endpoint file from Amazon S3:
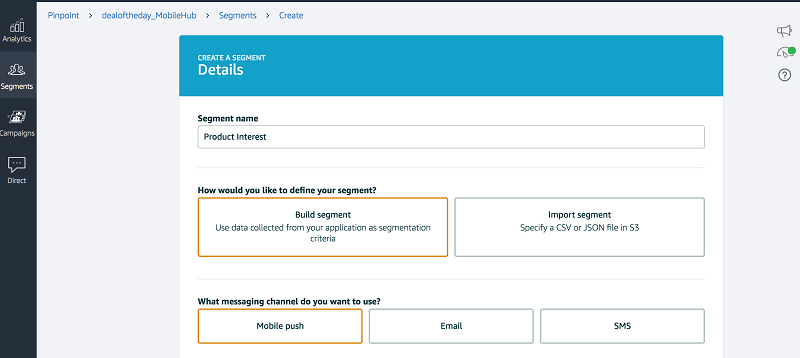
Wait for the import job to reach a COMPLETED status:

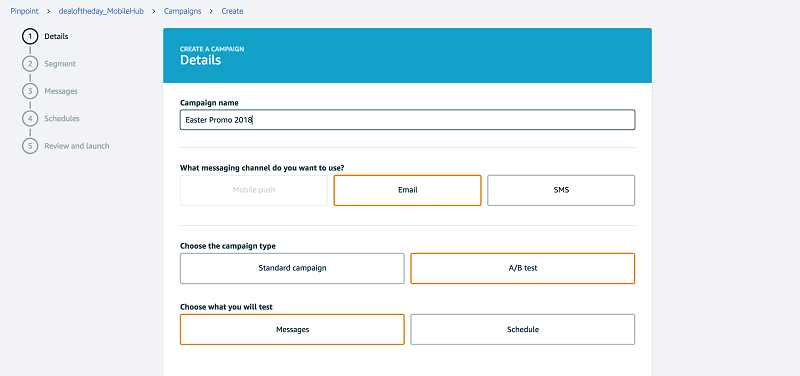
After you have created the segment, you can launch a campaign:
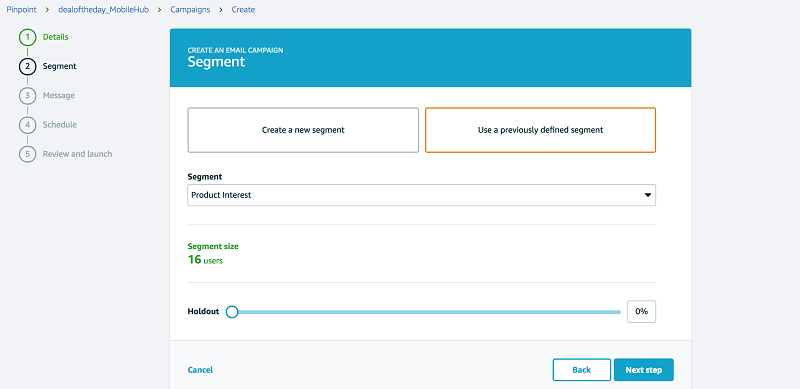
Select the segment that you just created as the target group for your campaign.
Craft a message for your campaign. You’ll need to craft a message for each treatment group if you launch a campaign with A/B testing:
Finally, set up the schedule for your campaign:
We’ve launched our campaign! However, our work isn’t done. Be sure to have a strategy to measure campaign as well as your predictive model performance independently.
- Campaign performance can be affected by the way you craft and present your message. Leverage A/B testing in Amazon Pinpoint to measure the performance of variations in your messaging.
- Your validation set might not be a good measure of your model’s performance. Your dataset might be flawed or insufficient. Have a strategy to test actual performance in production. One strategy is to maintain a control group. Amazon Pinpoint can facilitates this by allowing you to specify a holdout percentage on your segment. You can also leverage the Amazon Pinpoint Amazon Kinesis integration to capture campaign events, so additional data is available for diagnosing and measuring the performance of your campaign and models.
- ML model development is an iterative process. Have a strategy to validate various versions of your model in production. You can leverage the Amazon SageMaker built in A/B testing functionality to facilitate this task.
- Last but not least, measure the value you deliver to the business. As an example, consider public statistics for ecommerce conversion rates. Various sites on the internet report conversion rates in the 1-5% range, and open rates ranging from 10-60%. What if you had a predictive model with high prediction accuracy, and could craft personalized content that is highly compelling? The competitive edge potential is significant. Prove the effectiveness of your predictive campaigns to your business with the help of Amazon Pinpoint analytics to track and present metrics that include campaign performance, app usage, and revenue attribution.
Conclusion
In this blog post, I’ve demonstrated how your organization can bring data science and marketing together on the AWS platform with the help of Amazon SageMaker, Amazon Pinpoint, and an AWS data lake strategy. I’ve used a predictive campaigning solution that demonstrates how you can deliver bar raising results at high velocity and cost efficiency through automation, serverless architectures, and pay-on-use economics.
Happy campaigning!
—————————
[i] Citation request from dataset donor: Daqing Chen, Sai Liang Sain, and Kun Guo, Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining, Journal of Database Marketing and Customer Strategy Management, Vol. 19, No. 3, pp. 197–208, 2012 (Published online before print: 27 August 2012. doi: 10.1057/dbm.2012.17).
About the Author
 Dylan Tong is an Enterprise Solutions Architect at AWS. He works with customers to help drive their success on the AWS platform through thought leadership and guidance on designing well architected solutions. He has spent most of his career building on his expertise in data management and analytics by working for leaders and innovators in the space.
Dylan Tong is an Enterprise Solutions Architect at AWS. He works with customers to help drive their success on the AWS platform through thought leadership and guidance on designing well architected solutions. He has spent most of his career building on his expertise in data management and analytics by working for leaders and innovators in the space.