Artificial Intelligence
Augment fraud transactions using synthetic data in Amazon SageMaker
Developing and training successful machine learning (ML) fraud models requires access to large amounts of high-quality data. Sourcing this data is challenging because available datasets are sometimes not large enough or sufficiently unbiased to usefully train the ML model and may require significant cost and time. Regulation and privacy requirements further prevent data use or sharing even within an enterprise organization. The process of authorizing the use of, and access to, sensitive data often delays or derails ML projects. Alternatively, we can tackle these challenges by generating and using synthetic data.
Synthetic data describes artificially created datasets that mimic the content and patterns in the original dataset in order to address regulatory risk and compliance, time, and costs of sourcing. Synthetic data generators use the real data to learn relevant features, correlations, and patterns in order to generate required amounts of synthetic data matching the statistical qualities of the originally ingested dataset.
Synthetic Data has been in use in lab environments for over two decades; the market has evidence of utility that is accelerating adoption in commercial and public sectors. Gartner predicts that by 2024, 60 percent of the data used for the development of ML and analytics solutions will be synthetically generated and that the use of synthetic data will continue to increase substantially.
The Financial Conduct Authority, a UK regulatory body, acknowledges that “Access to data is the catalyst for innovation, and synthetic financial data could play a role in supporting innovation and enabling new entrants to develop, test, and demonstrate the value of new solutions.”
Amazon SageMaker GroundTruth currently supports synthetic data generation of labeled synthetic image data. This blog post explores tabular synthetic data generation. Structured data, such as single and relational tables, and time series data are the types most often encountered in enterprise analytics.
This is a two-part blog post; we create synthetic data in part one and evaluate its quality in part two.
In this blog post, you will learn how to use the open-source library ydata-synthetic and AWS SageMaker notebooks to synthesize tabular data for a fraud use case, where we do not have enough fraudulent transactions to train a high-accuracy fraud model. The general process of training a fraud model is covered in this post.
Overview of the solution
The aim of this tutorial is to synthesize the minority class of a highly imbalanced credit card fraud dataset using an optimized generative adversarial network (GAN) called WGAN-GP to learn patterns and statistical properties of original data and then create endless samples of synthetic data that resemble the original data. This process can also be used to enhance the original data by up-sampling rare events like fraud or to generate edge cases that are not present in the original.
We use a credit card fraud dataset published by ULB, which can be downloaded from Kaggle. Generating synthetic data for the minority class helps address problems related to imbalanced datasets, which can help in developing more accurate models.
We use AWS services, including Amazon SageMaker and Amazon S3, which incur costs to use cloud resources.
Set up the development environment
SageMaker provides a managed Jupyter notebook instance for model building, training, and deployment.
Prerequisites:
You must have an AWS account to run SageMaker. You can get started with SageMaker and try hands-on tutorials.
For instructions on setting up your Jupyter Notebook working environment, see Get Started with Amazon SageMaker Notebook Instances.
Step 1: Set up your Amazon SageMaker instance
- Sign in to the AWS console and search for “SageMaker.”
- Select Studio.
- Select Notebook instances on the left bar, and select Create notebook instance.
- From the next page (as shown in the following image), select the configurations of the virtual machine (VM) according to your needs, and select Create notebook instance. Note that we used an ML optimized VM with no GPU and 5 GB of data, ml.t3.medium running an Amazon Linux 2, and Jupyter Lab 3 kernel.

- A notebook instance will be ready for you to use within a few minutes.
- Select Open JupyterLab to launch.
- Now that we have a JupyterLab with our required specifications, we will install the synthetic library.
Step 2: Download or extract the real dataset to create synthetic data
Download the reference data from Kaggle either manually, as we do here, or programmatically through Kaggle API if you have a Kaggle account. If you explore this dataset, you’ll notice that the “fraud” class contains much less data than the “not fraud” class.
If you use this data directly for machine learning predictions, the models might always learn to predict “not fraud.” A model will easily have a higher accuracy in nonfraud cases since fraud cases are rare. However, since detecting the fraud cases is our objective in this exercise, we will boost the fraud class numbers with synthetic data modeled on the real data.
Create a data folder in JupyterLab and upload the Kaggle data file into it. This will let you use the data within the notebook since SageMaker comes with storage that you would have specified when you instantiated the notebook.
This dataset is 144 MB

You can then read the data using standard code via the pandas library:
Fraud-detection data has certain characteristics, namely:
- Large class imbalances (typically towards nonfraud data points).
- Privacy-related concerns (owing to the presence of sensitive data).
- A degree of dynamism, in that a malicious user is always trying to avoid detection by systems monitoring for fraudulent transactions.
- The available data sets are very large and often unlabeled.
Now that you have inspected the dataset, let’s filter the minority class (the “fraud” class from the credit card dataset) and perform transformations as required. You can check out the data transformations from this notebook.
When this minority class dataset is synthesized and added back to the original dataset, it allows the generation of a larger synthesized dataset that addresses the imbalance in data. We can achieve greater prediction accuracy by training a fraud detection model using the new dataset.
Let’s synthesize the new fraud dataset.
Step 3: Train the synthesizers and create the model
Since you have the data readily available within SageMaker, it’s time to put our synthetic GAN models to work.
A generative adversarial network (GAN) has two parts:
The generator learns to generate plausible data. The generated instances become negative training examples for the discriminator.
The discriminator learns to distinguish the generator’s fake data from real data. The discriminator penalizes the generator for producing implausible results.
When training begins, the generator produces obviously fake data, and the discriminator quickly learns to tell that it’s fake. As training progresses, the generator gets closer to producing output that can fool the discriminator. Finally, if generator training goes well, the discriminator gets worse at telling the difference between real and fake. It starts to classify fake data as real, and its accuracy decreases.
Both the generator and the discriminator are neural networks. The generator output is connected directly to the discriminator input. Through backpropagation, the discriminator’s classification provides a signal that the generator uses to update its weights.
Step 4: Sample synthetic data from the synthesizer
Now that you have built and trained your model, it’s time to sample the required data by feeding noise to the model. This enables you to generate as much synthetic data as you want.
In this case, you generate an equal quantity of synthetic data to the quantity of actual data because this it makes it easier to compare the similar sample sizes in Step 5.
We have the option to sample rows containing fraudulent transactions—which, when combined with the nonsynthetic fraud data, will lead to an equal distribution of “fraud” and “not-fraud” classes. The original Kaggle dataset contained 492 frauds out of 284,807 transactions, so we create a same sample from the synthesizer.
We have the option to up-sample rows containing fraudulent transactions in a process called data augmentation—which, when combined with the nonsynthetic fraud data, will lead to an equal distribution of “fraud” and “not-fraud” classes.
Step 5: Compare and evaluate the synthetic data against the real data
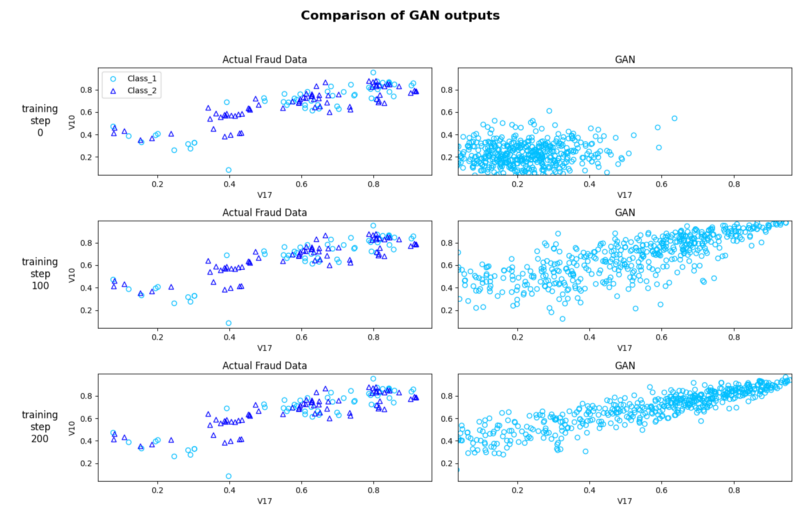
Though this step is optional, you can qualitatively visualize and assess the generated synthetic data against the actual data using a scatter plot.
This helps us iterate our model by tweaking parameters, changing sample size, and making other transformations to generate the most accurate synthetic data. This nature of accuracy is always depends on the purpose of the synthesis
The image below depicts how similar the actual fraud and the synthetic fraud data points are across the training steps. This gives a good qualitative inspection of the similarity between the synthetic and the actual data and how that improves as we run it through more epochs (transit of entire training dataset through algorithm). Note that as we run more epochs, the synthetic data pattern set gets closer to the original data.
Step 6: Clean up
Finally, stop your notebook instance when you’re done with the synthesis to avoid unexpected costs.
Conclusion
As machine learning algorithms and coding frameworks evolve rapidly, high-quality data at scale is the scarcest resource in ML. Good-quality synthetic datasets can be used in a variety of tasks.
In this blog post, you learned the importance of synthesizing the dataset by using an open-source library that uses WGAN-GP. This is an active research area with thousands of papers on GANs published and many hundreds of named GANs available for you to experiment with. There are variants that are optimized for specific use cases like relational tables and time series data.
You can find all the code used for this article in this notebook, and of course, more tutorials like this are available from the SageMaker official documentation page.
In the second part of this two-part blog post series, we will do a deep dive into how to evaluate the quality of the synthetic data from a perspective of fidelity, utility, and privacy.
About the Author
 Faris Haddad is the Data & Insights Lead in the AABG Strategic Pursuits team. He helps enterprises successfully become data-driven.
Faris Haddad is the Data & Insights Lead in the AABG Strategic Pursuits team. He helps enterprises successfully become data-driven.