Artificial Intelligence
Autodesk optimizes visual similarity search model in Fusion 360 with Amazon SageMaker Debugger
This post is co-written by Alexander Carlson, a machine learning engineer at Autodesk.
Autodesk started its digital transformation journey years ago by moving workloads from private data centers to AWS services. The benefits of digital transformation are clear with generative design, which is a new technology that uses cloud computing to accelerate design exploration beyond what’s humanly possible. Generative design lets you quickly generate a set of high-performance design options based on your specific constraints (like materials, weight, cost, or manufacturing methods). Generative design has the potential to disrupt the manufacturing industry—for the better. Autodesk scaled the use of generative design to run hundreds of simulations in an hour instead of several hours or days by using Amazon SageMaker.
In the fall of 2019, Autodesk was preparing to build and release visual similarity search capability for the generative design technology in Fusion 360 using machine learning (ML). The Autodesk team partnered with AWS to use Amazon SageMaker Debugger to assess how it could improve the model training and debugging process. SageMaker Debugger provides complete insights into the training process of ML models by automating the capture and analysis of data from training runs in real time, with no code changes.
This post outlines how Autodesk designed, trained, and debugged the model on an accelerated timeframe while realizing several other benefits. The following sections provide you with a view into the visual similarity search model, Autodesk’s pre-SageMaker Debugger approach, the steps undertaken to adapt code for SageMaker Debugger, the post-SageMaker Debugger approach, and a performance comparison between both approaches.
Visual similarity search model
The trained visual similarity search model computes feature vectors, which you can then group by their distances or use to find a generative design outcome nearest neighbor. Similar generative design outcomes have similar feature vectors. Visual similarity search provides a categorical view of the design outcomes from generative design so you can pick the best design. The following screenshot shows an example of Fusion 360 with the visual similarity search model.

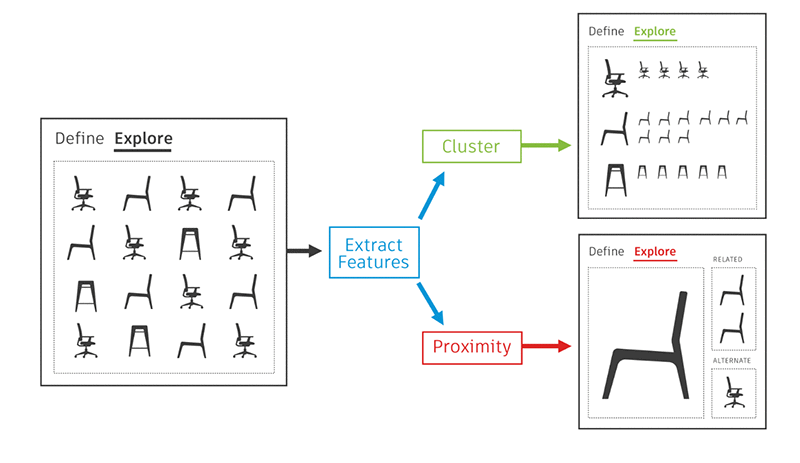
Each outcome that generative design in Fusion 360 produces is a 3D shape. The visual search model takes several snapshots of the 3D object from different angles, and the model tries to reconstruct those snapshots.
Autodesk’s ML model is an autoencoder that consists of the following layers:
- Encoder – Learns the features of the inputs
- Bottleneck– Forces the autoencoder to learn a compressed representation of the input data
- Decoder – Takes latent feature vectors and tries to reconstruct the original inputs
After the autoencoder is trained, one can use the bottleneck layer, which has learned the most important features of a given shape, to produce a feature vector for every geometry. The feature vectors can then be used to cluster similarity design outcomes together to make it easier and more efficient to find the perfect design.
Pre-SageMaker Debugger approach
The Autodesk team followed a linear process for training and editing the model before using SageMaker Debugger. Keeping model training costs under control was one of the drivers for not kicking off parallel training jobs. However, it came at the price of not being able to explore other network architectures and find one that was most efficient and had the best results.
The following diagram illustrates the workflow to validate a hyperparameter.
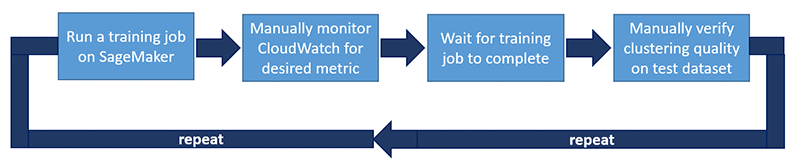
The workflow contains the following steps:
- Run a training job on Amazon SageMaker. After preparing training data, Autodesk set the training job hyperparameters and launched the training job from an Amazon SageMaker notebook. Autodesk used Tensorboard to visualize autoencoder reconstruction performance.
- Manually monitor Amazon CloudWatch Events for the desired metric. Accuracy and loss were reported at specific training intervals. Autodesk used a combination of decreasing loss and increasing accuracy as metrics to identify a healthy training job. For model verification, Autodesk used a local instance of Tensorboard. There was code in the model that produced autoencoder inputs and outputs for each checkpoint, which allowed them to visually inspect and verify the model.
- Wait for the training job to complete. One training job usually took 10–15 hours to complete. Several times, a bad training job left running overnight wasted time and expensive compute resources. A bad training job was defined as a job that was not converging or continued to produce bad outputs after several hours of training.
- Manually verify clustering quality on the test dataset. Autodesk used Tensorboard visualization to validate the clustering performance of the model. The following screenshot shows a Tensorboard visualization.

3D-spacial placement in the Tensorboard projection represented the result of T-SNE clustering. T-SNE are t-distributed stochastic neighbor embeddings. The technique maps highly dimensional data into a two- or three-dimensional space where you can visualize it easily. Similar geometries should produce similar TSNE embeddings and consequently be close in the embedding space. This allowed Autodesk to verify if the model’s embedding was clustering the outcomes of generative design in a desirable way. Good model performance was indicated by successfully grouping the outcomes in the way that a human user would agree with.
Adapting code to use Amazon SageMaker Debugger
Adding SageMaker Debugger to the Autodesk training job was simple. SageMaker Debugger supports the zero-code change paradigm, which means that you don’t have to change the training script at all. You only need to specify a debugger hook configuration in the Amazon SageMaker estimator that defines which tensors to emit.
SageMaker Debugger provides default collections such as weights, biases, gradients, and losses. You can also easily define a custom collection by indicating a regular expression to include tensor names. For instance, if you want to include outputs of Relu activations, you can define the collection with the following code:
For Autodesk’s visual similarity search model, the following default collections were emitted:
The Amazon SageMaker Debugger hook configuration passed to the estimator and the configuration of the LossNotDecreasing built-in rule. See the following code:
The following section explains built-in rules in more detail.
Post-SageMaker Debugger approach
With SageMaker Debugger, Autodesk kicked off parallel training jobs to run a parameter sweep. Parallelization of training jobs significantly changed the overall workflow. To keep compute costs under control, Autodesk used built-in SageMaker Debugger rules to trigger auto-termination for suboptimal training jobs.
Autodesk used different hyperparameter values to assess which combination yielded the best results. Before SageMaker Debugger, Autodesk had to run multiple training jobs, each with a different set of hyperparameter values, and wait for these training jobs to complete before inspecting the results. With SageMaker Debugger, they could run multiple training jobs in parallel, set the built-in rules, and select the option to stop training when an alert is triggered. Autodesk saved time and money because training jobs terminated if a bad hyperparameter led the training job to not converge.
The following diagram illustrates the new workflow.
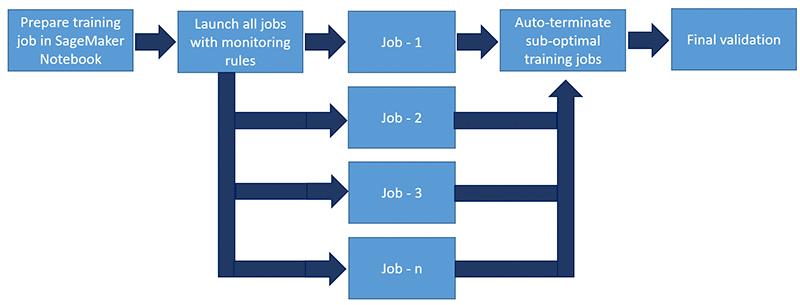
SageMaker Debugger comes with a set of built-in rules that detect the most common training issues, including vanishing and exploding gradients, neuron saturations, and more. These rules emit metrics to CloudWatch that indicate if there is an issue. You can set up a CloudWatch alarm and an AWS Lambda function to stop training jobs.
This feature allowed Autodesk to kick off parallel training jobs to run large parameter sweeps and to auto-terminate suboptimal training jobs. As a result, they saved compute costs and produced better models.
During the parameter sweep, Autodesk primarily used the built-in rule LossNotDecreasing, which triggers when the loss does not decrease by a specified percentage. A loss function evaluates the model output versus groundtruth: in the case of autoencoders, the loss function measures the distance between autoencoder output and the input. Autodesk’s visual similarity search model used the L2 loss: the better the reconstructed output, the smaller the L2 loss. A non-decreasing loss may indicate the following:
- The training has arrived at a local optimum, so there is no need to train the model further because it may lead to overfitting
- The model does not learn at all if loss does not decrease throughout the whole training process due to bad hyperparameters
In both cases, it is best to stop the training.
During the parameter sweep, Autodesk varied the learning rate, learning rate decay, batch size, and training dataset.
You can also define custom rules for SageMaker Debugger. Autodesk used SageMaker Debugger as a key indicator for model performance—how well it groups similar inputs in the latent space. You can easily define a custom rule that checks the distance between inputs of the same class in the latent space and raise an exception if similar inputs are not nearby.
In addition to the ability to run parallel training jobs and terminate them automatically based on rules, SageMaker Debugger allowed Autodesk to visualize and compute statistics on tensors in real time as training progressed.
The smdebug open-source library facilitates reading and filtering tensors. Conveniently, smdebug provides the data as NumPy arrays, so you can use libraries like NumPy, Scipy, Scikit, and others to analyze and visualize the data.
The following code example shows how to obtain the minimum and maximum values of gradients per layer:
After you retrieve the tensors, you can visualize the distribution of weights, gradients, activation outputs, and more in real time. For Autodesk, this analysis revealed that the model suffered from vanishing gradients and that weights in inner layers only received small updates. This was due to the following factors:
- The L2 loss function converged too quickly and produced small gradients. This is a common problem in autoencoders because L2 loss only compares the intensity values between input and output. This can lead to small loss values and blurry reconstructed output.
- The model consisted of too many layers, so the gradients became smaller as they got closer to the initial layers of the model.
- The bottleneck layer consisted of several fully connected layers, while most of them only received small updates.
The following graphs show the distribution of gradients for the first and last layers of the encoder. Gradients have tiny ranges and their order of magnitude differs between layers.
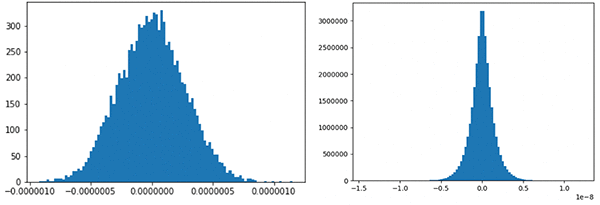
Based on the analysis, Autodesk applied the following optimizations:
- The structural similarity index (SSIM) loss replaced the L2 loss function. SSIM is a metric that is more suited to comparing the similarity between images. The visual similarity search model learned more fine-grained details and produced higher-quality output by using SSIM.
- Some layers were removed in the encoder and decoder, which resulted in a smaller model without impacting model quality.
- The bottleneck layer was reduced by more than a factor of three, which lead to a significant decrease in the number of parameters.
Autodesk used the visualization of TSNE embeddings to determine if their autoencoder model was training well. With SageMaker Debugger and Scikit-Learn, they could compute and visualize those embeddings in real time while training was still ongoing. For more information, see the GitHub repo.
The following screenshot shows example images produced by the optimized model.

Benefits of Amazon SageMaker Debugger
The Autodesk team realized the following benefits by using SageMaker Debugger:
- Time savings – The ability to trigger parallel training jobs reduced overall model training time by over 90%. Autodesk trained the complete model in 10 hours by using SageMaker Debugger, as compared to 5–6 days with the manual training approach.
- Compute cost savings – Most of the training jobs set up using SageMaker Debugger terminated quickly, which saved approximately 70% of compute costs. It also saved developer time by avoiding the verification step of suboptimal training jobs.
- Reduced model size – The Autodesk team determined the performance of each network layer by using the insights drawn from model performance data. These insights resulted in reducing the number of layers by 33% and therefore reducing the overall model size by 40%.
Recommendations
In addition to the approaches and benefits outlined in this post, you should consider the following recommendations when training and deploying ML models:
- Use Amazon SageMaker Studio to help simplify model creation.
- Use concurrent Lambda functions to quickly apply transformations to datasets on Amazon S3. You can take advantage of concurrent Lambda functions by submitting jobs to an Amazon SQS queue acting as a Lambda trigger.
- Training with Amazon SageMaker Spot Instances can save up to 70% of compute costs. You can increase the frequency of checkpointing to reduce time loss to interrupts.
- Set up private data labeling jobs in Amazon SageMaker Ground Truth that only your team or organization can access, which allows you to use the tool without exposing your data externally.
For more information about using SageMaker Debugger, see the GitHub repo.
Conclusion
This post discussed how Autodesk designed, trained, and debugged an ML model with SageMaker Debugger. You can use SageMaker Debugger to save time, compute costs, and reduce your model size.
About the Authors
 Alexander Carlson is a Machine Learning Engineer at Autodesk working on the Fusion 360 Machine Learning team. Currently, he is working on AWS-based infrastructure for implementing machine learning in Autodesk’s production workflows.
Alexander Carlson is a Machine Learning Engineer at Autodesk working on the Fusion 360 Machine Learning team. Currently, he is working on AWS-based infrastructure for implementing machine learning in Autodesk’s production workflows.
 Nathalie Rauschmayr is a Machine Learning Scientist at AWS, where she helps customers develop deep learning applications.
Nathalie Rauschmayr is a Machine Learning Scientist at AWS, where she helps customers develop deep learning applications.
 Niraj Jetly is the Software Development Manager for Neptune with AWS. Prior to his current role, Niraj led Autodesk digital transformation journey as a Senior CSM. Before working with AWS, Niraj led several product and engineering teams as a CTO, VP-Engineering, and Head of Product Management for over 15 years.
Niraj Jetly is the Software Development Manager for Neptune with AWS. Prior to his current role, Niraj led Autodesk digital transformation journey as a Senior CSM. Before working with AWS, Niraj led several product and engineering teams as a CTO, VP-Engineering, and Head of Product Management for over 15 years.
 Satadal Bhattacharjee is Principal Product Manager at AWS AI. He leads the machine learning engine PM team on projects such as Amazon SageMaker, optimizing machine learning frameworks such as TensorFlow, PyTorch, and MXNet.
Satadal Bhattacharjee is Principal Product Manager at AWS AI. He leads the machine learning engine PM team on projects such as Amazon SageMaker, optimizing machine learning frameworks such as TensorFlow, PyTorch, and MXNet.