Artificial Intelligence
Build a scalable machine learning pipeline for ultra-high resolution medical images using Amazon SageMaker
Neural networks have proven effective at solving complex computer vision tasks such as object detection, image similarity, and classification. With the evolution of low-cost GPUs, the computational cost of building and deploying a neural network has drastically reduced. However, most techniques are designed to handle pixel resolutions commonly found in visual media. For example, typical resolution sizes are 544 and 416 pixels for YOLOv3, 300 and 512 pixels for SSD, and 224 pixels for VGG. Training a classifier over a dataset consisting of gigapixel images (10^9+ pixels) such as satellite or digital pathology images is computationally challenging. These images cannot be directly input into a neural network because each GPU is limited by available memory. This requires specific preprocessing techniques such as tiling to be able to process the original images in smaller chunks. Furthermore, due to the large size of these images, the overall training time tends to be high, often requiring several days or weeks without the use of proper scaling techniques such as distributed training.
In this post, we explain how to build a highly scalable machine learning (ML) pipeline to fulfill three objectives:
- Preprocess ultra high-resolution images by tiling, zooming, and sorting them into train and test splits using Amazon SageMaker Processing
- Train an image classifier on the preprocessed tiled images using Amazon SageMaker, Horovod, and SageMaker Pipe mode
- Deploy a pretrained model as an API using SageMaker
Dataset
In this post, we use a dataset consisting of whole-slide digital pathology images obtained from The Cancer Genome Atlas (TCGA) to accurately and automatically classify them as LUAD (adenocarcinoma), LUSC (squamous cell carcinoma), or normal lung tissue, where LUAD and LUSC are the two most prevalent subtypes of lung cancer. The dataset is available for public use by NIH and NCI.
The raw high-resolution images are in SVS format. SVS files are used for archiving and analyzing Aperio microscope images. You can apply the techniques and tools used in this post to any ultra high-resolution image dataset, including satellite images.
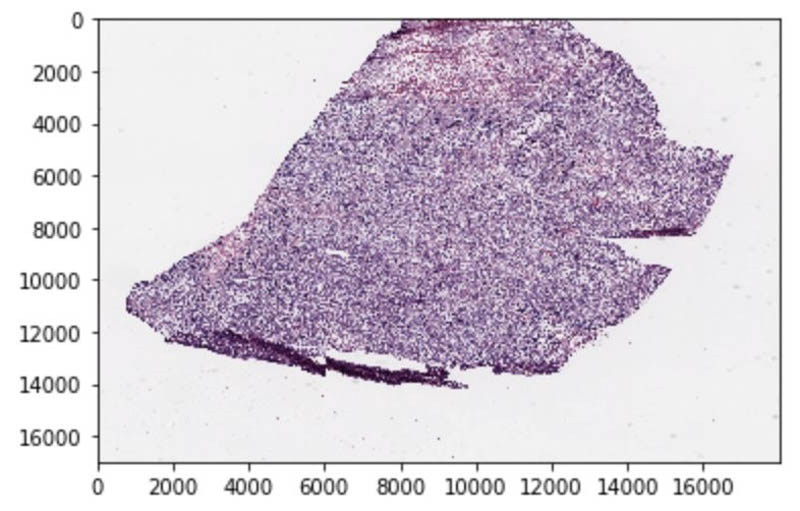
The following is a sample image of a tissue slide. This single image contains over a quarter of a billion pixels, and occupies over 750 MB of memory. This image cannot be fed directly to a neural network in its original form, so we must tile the image into many smaller images.
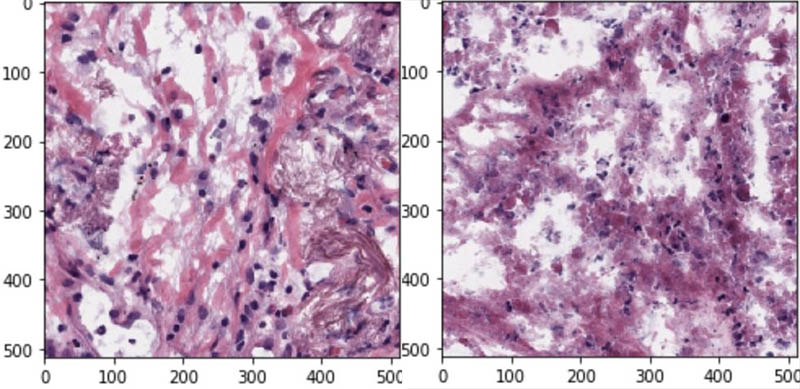
The following are samples of tiled images generated after preprocessing the preceding tissue slide image. These RGB 3-channel images are of size 512×512 and can be directly used as inputs to a neural network. Each of these tiled images is assigned the same label as the parent slide. Additionally, tiled images with more than 50% background are discarded.
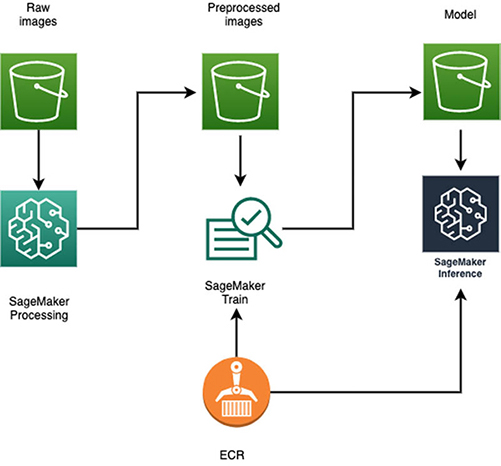
Architecture overview
The following figure shows the overall end-to-end architecture, from the original raw images to inference. First, we use SageMaker Processing to tile, zoom, and sort the images into train and test splits, and then package them into the necessary number of shards for distributed SageMaker training. Second, a SageMaker training job loads the Docker container from Amazon Elastic Container Registry (Amazon ECR). The job uses Pipe mode to read the data from the prepared shards of images, trains the model, and stores the final model artifact in Amazon Simple Storage Service (Amazon S3). Finally, we deploy the trained model on a real-time inference endpoint that loads the appropriate Docker container (from Amazon ECR) and model (from Amazon S3) to process inference requests with low latency.
Data preprocessing using SageMaker Processing
The SVS slide images are preprocessed in three steps:
- Tiling images – The images are tiled by non-overlapping 512×512 pixel windows, and tiles containing over 50% background are discarded. The tiles are stored as JPEG images.
- Converting images to TFRecords – We use SageMaker Pipe mode to reduce our training time, which requires the data to be available in a proto-buffer format. TFRecord is a popular proto-buffer format used for training models with TensorFlow. We explain SageMaker Pipe mode and proto-buffer format in more detail in the following section.
- Sorting TFRecords – We sort the dataset into test, train, and validation cohorts for a three-way classifier (LUAD/LUSC/Normal). The TCGA dataset can have multiple slide images corresponding to a single patient. We need to make sure all the tiles generated from slides corresponding to the same patient occupy the same split to avoid data leakage. For the test set, we create per-slide TFRecord containing all the tiles from that slide so that we can evaluate the model in the way it will be used in deployment.
The following is the preprocessing code:
We use SageMaker Processing for the preceding preprocessing steps, which allows us to run data preprocessing or postprocessing, feature engineering, data validation, and model evaluation workloads with SageMaker. Processing jobs accept data from Amazon S3 as input and store processed output data back into Amazon S3.
A benefit of using SageMaker Processing is the ease of distributing inputs across multiple compute instances. We can simply set s3_data_distribution_type=ShardedByS3Key parameter to divide data equally among all processing containers.
Importantly, the number of processing instances matches the number of GPUs we will use for distributed training with Horovod (i.e., 16). The reasoning becomes clearer when we introduce Horovod training.
The processing script is available on GitHub.
Distributed model training using SageMaker Training
Taking ML models from conceptualization to production is typically complex and time-consuming. We have to manage large amounts of data to train the model, choose the best algorithm for training it, manage the compute capacity while training it, and then deploy the model into a production environment. SageMaker reduces this complexity by making it much easier to build and deploy ML models. It manages the underlying infrastructure to train your model at petabyte scale and deploy it to production.
After we preprocess the whole-slide images, we still have hundreds of gigabytes of data. Training on a single instance (GPU or CPU) would take several days or weeks to finish. To speed things up, we need to distribute the workload of training a model across multiple instances. For this post, we focus on distributed deep learning based on data parallelism using Horovod, a distributed training framework, and SageMaker Pipe mode.
Horovod: A cross-platform distributed training framework
When training a model with a large amount of data, the data needs to distributed across multiple CPUs or GPUs on either a single instance or multiple instances. Deep learning frameworks provide their own methods to support distributed training. Horovod is a popular framework-agnostic toolkit for distributed deep learning. It utilizes an allreduce algorithm for fast distributed training (compared with a parameter server approach) and includes multiple optimization methods to make distributed training faster. For more examples of distributed training with Horovod on SageMaker, see Multi-GPU and distributed training using Horovod in Amazon SageMaker Pipe mode and Reducing training time with Apache MXNet and Horovod on Amazon SageMaker.
SageMaker Pipe mode
You can provide input to SageMaker in either File mode or Pipe mode. In File mode, the input files are copied to the training instance. With Pipe mode, the dataset is streamed directly to your training instances. This means that the training jobs start sooner, compute and download can happen in parallel, and less disk space is required. Therefore, we recommend Pipe mode for large datasets.
SageMaker Pipe mode requires data to be in a protocol buffer format. Protocol buffers are language-neutral, platform-neutral, extensible mechanisms for serializing structured data. TFRecord is a popular proto-buffer format used for training models with TensorFlow. TFRecords are optimized for use with TensorFlow in multiple ways. First, they make it easy to combine multiple datasets and integrate seamlessly with the data import and preprocessing functionality provided by the library. Second, you can store sequence data—for instance, a time series or word encodings—in a way that allows for very efficient and (from a coding perspective) convenient import of this type of data.
The following diagram illustrates data access with Pipe mode.
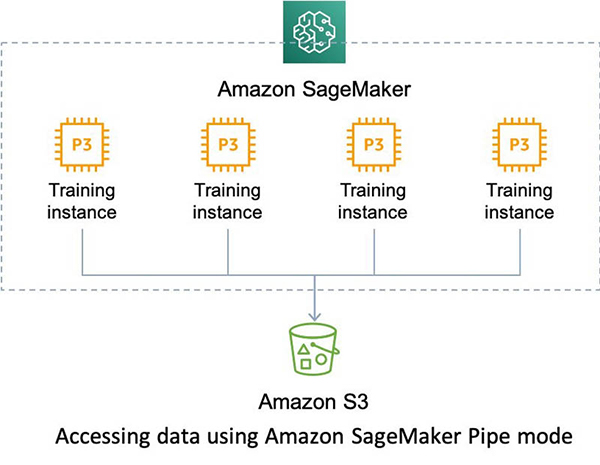
Data sharding with SageMaker Pipe mode
You should keep in mind a few considerations when working with SageMaker Pipe mode and Horovod:
- The data that is streamed through each pipe is mutually exclusive of the other pipes. The number of pipes dictates the number of data shards that need to be created.
- Horovod wraps the training script for each compute instance. This means that data for each compute instance needs to be from a different shard.
- With the SageMaker Training parameter
S3DataDistributionTypeset toShardedByS3Key, we can share a pipe with more than one instance. The data is streamed in round-robin fashion across instances.
To illustrate this better, let’s say we use two instances (A and B) of type ml.p3.8xlarge. Each ml.p3.8xlarge instance has four GPUs. We create four pipes (P1, P2, P3, and P4) and set S3DataDistributionType = 'ShardedByS3Key’. As shown in the following table, each pipe equally distributes the data between two instances in a round-robin fashion. This is the core concept needed in setting up pipes with Horovod. Because Horovod wraps the training script for each GPU, we need to create as many pipes as there are GPUs per training instance.
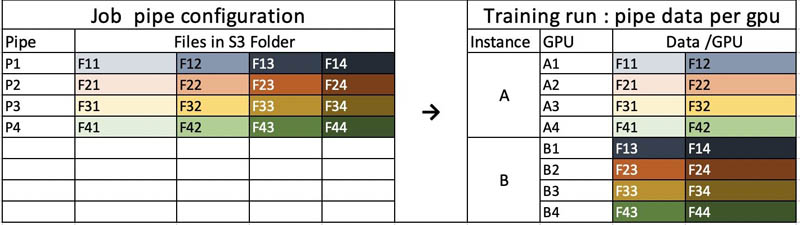
The following code shards the data in Amazon S3 for each pipe. Each shard should have a separate prefix in Amazon S3.
We use a SageMaker estimator to launch training on four instances of ml.p3.8xlarge. Each instance has four GPUs. Thus, there are a total of 16 GPUs. See the following code:
The following code snippet of the training script shows how to orchestrate Horovod with TensorFlow for distributed training:
Because Pipe mode streams the data to each of our instances, the training script cannot calculate the data size during training (which is needed to compute steps_per_epoch). The parameter is therefore provided manually as a hyperparameter to the TensorFlow estimator. Additionally, the number of data points must be specified so that it can be divided equally amongst the GPUs. An unequal division could lead to a Horovod deadlock, because the time taken by each GPU to complete the training process is no longer identical. To ensure that the data points are equally divided, we use the same of number of instances for preprocessing as the number of GPUs for training. In our example, this number is 16.
Inference and deployment
After we train the model using SageMaker, we deploy it for inference on new images. To set up a persistent endpoint to get one prediction at a time, use SageMaker hosting services. To get predictions for an entire dataset, use SageMaker batch transform.
In this post, we deploy the trained model as a SageMaker endpoint. The following code deploys the model to an m4 instance, reads tiled image data from TFRecords, and generates a slide-level prediction:
The model is trained on individual tile images. During inference, the SageMaker endpoint provides classification scores for each tile. These scores are averaged out across all tiles to generate the slide-level score and prediction. The following diagram illustrates this workflow.
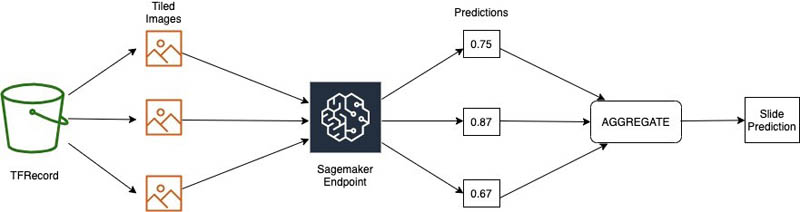
A majority vote scheme would also be appropriate.
To perform inference on a large new batch of slide images, you can run a batch transform job for offline predictions on the dataset in Amazon S3 on multiple instances. Once the processed TFRecords are retrieved from Amazon S3, you can replicate the preceding steps to generate a slide-level classification for each of the new images.
Conclusion
In this post, we introduced a scalable machine learning pipeline for ultra high-resolution images that uses SageMaker Processing, SageMaker Pipe mode, and Horovod. The pipeline simplifies the convoluted process of large-scale training of a classifier over a dataset consisting of images that approach the gigapixel scale. With SageMaker and Horovod, we eased the process by distributing inputs across multiple compute instances, which reduces training time. We also provided a simple but effective strategy to aggregate tile-level predictions to produce slide-level inference.
For more information about SageMaker, see Build, train, and deploy a machine learning model with Amazon SageMaker. For the complete example to run on SageMaker, in which Pipe mode and Horovod are applied together, see the GitHub repo.
References
- Nicolas Coudray, Paolo Santiago Ocampo, Theodore Sakellaropoulos, Navneet Narula, Matija Snuderl, David Fenyö, Andre L. Moreira, Narges Razavian, Aristotelis Tsirigos. “Classification and mutation prediction from non–small cell lung cancer histopathology images using deep learning”. Nature Medicine, 2018; DOI: 10.1038/s41591-018-0177-5
- https://github.com/ncoudray/DeepPATH/tree/master/DeepPATH_code
- https://www.cancer.gov/about-nci/organization/ccg/research/structural-genomics/tcga
About the Authors
 Karan Sindwani is a Data Scientist at Amazon Machine Learning Solutions where he builds and deploys deep learning models. He specializes in the area of computer vision. In his spare time, he enjoys hiking.
Karan Sindwani is a Data Scientist at Amazon Machine Learning Solutions where he builds and deploys deep learning models. He specializes in the area of computer vision. In his spare time, he enjoys hiking.
 Vinay Hanumaiah is a Deep Learning Architect at Amazon ML Solutions Lab, where he helps customers build AI and ML solutions to accelerate their business challenges. Prior to this, he contributed to the launch of AWS DeepLens and Amazon Personalize. In his spare time, he enjoys time with his family and is an avid rock climber.
Vinay Hanumaiah is a Deep Learning Architect at Amazon ML Solutions Lab, where he helps customers build AI and ML solutions to accelerate their business challenges. Prior to this, he contributed to the launch of AWS DeepLens and Amazon Personalize. In his spare time, he enjoys time with his family and is an avid rock climber.
 Ryan Brand is a Data Scientist in the Amazon Machine Learning Solutions Lab. He has specific experience in applying machine learning to problems in healthcare and the life sciences, and in his free time he enjoys reading history and science fiction.
Ryan Brand is a Data Scientist in the Amazon Machine Learning Solutions Lab. He has specific experience in applying machine learning to problems in healthcare and the life sciences, and in his free time he enjoys reading history and science fiction.
 Tatsuya Arai, Ph.D. is a biomedical engineer turned deep learning data scientist on the Amazon Machine Learning Solutions Lab team. He believes in the true democratization of AI and that the power of AI shouldn’t be exclusive to computer scientists or mathematicians.
Tatsuya Arai, Ph.D. is a biomedical engineer turned deep learning data scientist on the Amazon Machine Learning Solutions Lab team. He believes in the true democratization of AI and that the power of AI shouldn’t be exclusive to computer scientists or mathematicians.