Artificial Intelligence
Category: Artificial Intelligence

Architecting TrueLook’s AI-powered construction safety system on Amazon SageMaker AI
This post provides a detailed architectural overview of how TrueLook built its AI-powered safety monitoring system using SageMaker AI, highlighting key technical decisions, pipeline design patterns, and MLOps best practices. You will gain valuable insights into designing scalable computer vision solutions on AWS, particularly around model training workflows, automated pipeline creation, and production deployment strategies for real-time inference.
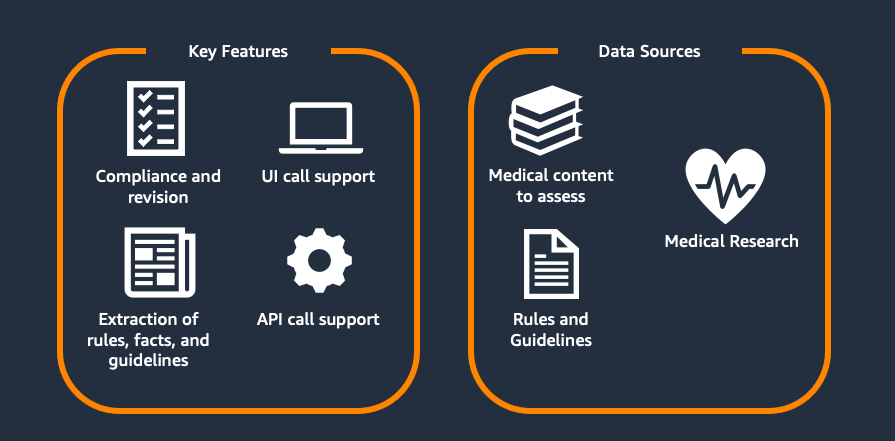
Scaling medical content review at Flo Health using Amazon Bedrock (Part 1)
This two-part series explores Flo Health’s journey with generative AI for medical content verification. Part 1 examines our proof of concept (PoC), including the initial solution, capabilities, and early results. Part 2 covers focusing on scaling challenges and real-world implementation. Each article stands alone while collectively showing how AI transforms medical content management at scale.

Detect and redact personally identifiable information using Amazon Bedrock Data Automation and Guardrails
This post shows an automated PII detection and redaction solution using Amazon Bedrock Data Automation and Amazon Bedrock Guardrails through a use case of processing text and image content in high volumes of incoming emails and attachments. The solution features a complete email processing workflow with a React-based user interface for authorized personnel to more securely manage and review redacted email communications and attachments. We walk through the step-by-step solution implementation procedures used to deploy this solution. Finally, we discuss the solution benefits, including operational efficiency, scalability, security and compliance, and adaptability.

Speed meets scale: Load testing SageMakerAI endpoints with Observe.AI’s testing tool
Observe.ai developed the One Load Audit Framework (OLAF), which integrates with SageMaker to identify bottlenecks and performance issues in ML services, offering latency and throughput measurements under both static and dynamic data loads. In this blog post, you will learn how to use the OLAF utility to test and validate your SageMaker endpoint.

Migrate MLflow tracking servers to Amazon SageMaker AI with serverless MLflow
This post shows you how to migrate your self-managed MLflow tracking server to a MLflow App – a serverless tracking server on SageMaker AI that automatically scales resources based on demand while removing server patching and storage management tasks at no cost. Learn how to use the MLflow Export Import tool to transfer your experiments, runs, models, and other MLflow resources, including instructions to validate your migration’s success.

Build an AI-powered website assistant with Amazon Bedrock
This post demonstrates how to solve this challenge by building an AI-powered website assistant using Amazon Bedrock and Amazon Bedrock Knowledge Bases.

Programmatically creating an IDP solution with Amazon Bedrock Data Automation
In this post, we explore how to programmatically create an IDP solution that uses Strands SDK, Amazon Bedrock AgentCore, Amazon Bedrock Knowledge Base, and Bedrock Data Automation (BDA). This solution is provided through a Jupyter notebook that enables users to upload multi-modal business documents and extract insights using BDA as a parser to retrieve relevant chunks and augment a prompt to a foundational model (FM).

AI agent-driven browser automation for enterprise workflow management
Enterprise organizations increasingly rely on web-based applications for critical business processes, yet many workflows remain manually intensive, creating operational inefficiencies and compliance risks. Despite significant technology investments, knowledge workers routinely navigate between eight to twelve different web applications during standard workflows, constantly switching contexts and manually transferring information between systems. Data entry and validation tasks […]

Agentic QA automation using Amazon Bedrock AgentCore Browser and Amazon Nova Act
In this post, we explore how agentic QA automation addresses these challenges and walk through a practical example using Amazon Bedrock AgentCore Browser and Amazon Nova Act to automate testing for a sample retail application.

Optimizing LLM inference on Amazon SageMaker AI with BentoML’s LLM- Optimizer
In this post, we demonstrate how to optimize large language model (LLM) inference on Amazon SageMaker AI using BentoML’s LLM-Optimizer to systematically identify the best serving configurations for your workload.