Artificial Intelligence
Category: Artificial Intelligence

How Lumi streamlines loan approvals with Amazon SageMaker AI
Lumi is a leading Australian fintech lender empowering small businesses with fast, flexible, and transparent funding solutions. They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. This post explores how Lumi uses Amazon SageMaker AI to meet this goal, enhance their transaction processing and classification capabilities, and ultimately grow their business by providing faster processing of loan applications, more accurate credit decisions, and improved customer experience.

How AWS Sales uses generative AI to streamline account planning
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers. In this post, we showcase how the AWS Sales product team built the generative AI account plans draft assistant.

Shaping the future: OMRON’s data-driven journey with AWS
OMRON Corporation is a leading technology provider in industrial automation, healthcare, and electronic components. In their Shaping the Future 2030 (SF2030) strategic plan, OMRON aims to address diverse social issues, drive sustainable business growth, transform business models and capabilities, and accelerate digital transformation. At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI.

AI Workforce: using AI and Drones to simplify infrastructure inspections
Inspecting wind turbines, power lines, 5G towers, and pipelines is a tough job. It’s often dangerous, time-consuming, and prone to human error. This post is the first in a three-part series exploring AI Workforce, the AWS AI-powered drone inspection system. In this post, we introduce the concept and key benefits. The second post dives into the AWS architecture that powers AI Workforce, and the third focuses on the drone setup and integration.

Ray jobs on Amazon SageMaker HyperPod: scalable and resilient distributed AI
Ray is an open source framework that makes it straightforward to create, deploy, and optimize distributed Python jobs. In this post, we demonstrate the steps involved in running Ray jobs on SageMaker HyperPod.
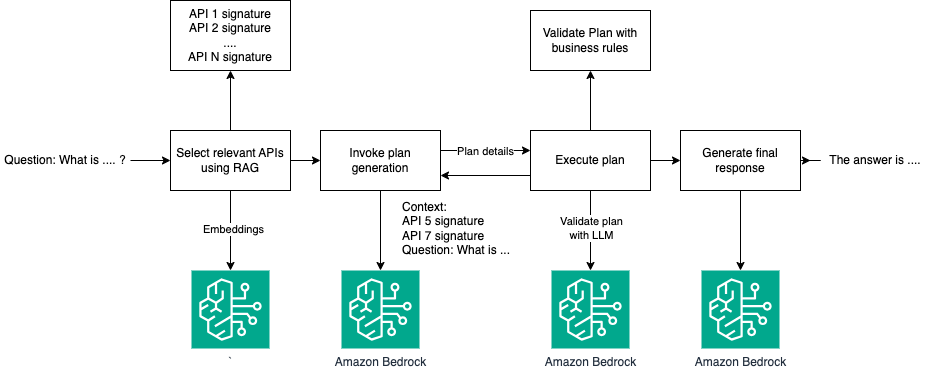
Using Large Language Models on Amazon Bedrock for multi-step task execution
This post explores the application of LLMs in executing complex analytical queries through an API, with specific focus on Amazon Bedrock. To demonstrate this process, we present a use case where the system identifies the patient with the least number of vaccines by retrieving, grouping, and sorting data, and ultimately presenting the final result.

Introducing AWS MCP Servers for code assistants (Part 1)
We’re excited to announce the open source release of AWS MCP Servers for code assistants — a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers. In this post, we walk through how these specialized MCP servers can dramatically reduce your development time while incorporating security controls, cost optimizations, and AWS Well-Architected best practices into your code.

Harness the power of MCP servers with Amazon Bedrock Agents
Today, MCP is providing agents standard access to an expanding list of accessible tools that you can use to accomplish a variety of tasks. In this post, we show you how to build an Amazon Bedrock agent that uses MCP to access data sources to quickly build generative AI applications.

Generate compliant content with Amazon Bedrock and ConstitutionalChain
In this post, we explore practical strategies for using Constitutional AI to produce compliant content efficiently and effectively using Amazon Bedrock and LangGraph to build ConstitutionalChain for rapid content creation in highly regulated industries like finance and healthcare

Minimize generative AI hallucinations with Amazon Bedrock Automated Reasoning checks
To improve factual accuracy of large language model (LLM) responses, AWS announced Amazon Bedrock Automated Reasoning checks (in gated preview) at AWS re:Invent 2024. In this post, we discuss how to help prevent generative AI hallucinations using Amazon Bedrock Automated Reasoning checks.